第十九章 一般控制问题
这个章节似乎是对于控制的讨论的尾声。此前,已经讨论了常规的控制结构和非常规的控制结构。
19.1 布尔表达式
几乎所有控制结构都关乎布尔表达式。
【回顾】在读书笔记(二)、读书笔记(三)中有关于变量名与布尔变量的讨论,其中提到:
- 布尔变量名应该使用显然有两个状态的名字,如done ok;可以使用is开头的变量名,如isFound等等。关于is开头的变量名,我之后实践中有尝试操作,却发现常常导致变量名过分冗长,如isComplete;而且假如变量名为类的私有属性,访问器的名字会更加冗长,如getIsComplete。后来意识到,对于__显然__有两个状态、__显然__为布尔值的名字,可以不需要is,如valid、done这种名字本身已经足够。is用于比较模糊的名字,如isRed。
- 可以用布尔变量简化复杂的布尔表达式。这个技巧我也有使用,不过这个变量是临时变量、却可能会存活很久,所以出于完美主义有点不习惯。看来只能进行权衡了。
对于true和false:
- 布尔表达式中应该使用true和false,而非0和1。
- 不要显式地比较布尔表达式,如if(valid == false),while((a > b) == true),这样语义复杂而不自然。不过我其实经常用valid == false这种表达形式,因为感觉c/cpp中的!不太显眼。以后可以各自尝试一下。
简化判断条件:
- 用布尔变量表示中间结果,从而简化判断。
- 将复杂而且反复出现的判断条件写作布尔函数。这样既能简化代码,又有自注释的效果。
编写肯定的布尔表达式,不要用太多否定。这个和我之前提到的我经常使用valid == false应该是一个思路。不过书中建议的是用摩根律减少not的出现。
用括号使布尔表达式更清晰。不过个人觉得因为运算符的优先级过于复杂、而且不同语言都不太一样,所以所有的式子中都应该多用括号……
可以把整个布尔表达式都括在括号里,尤其是使用三目运算符时。
注意逻辑运算符是否有短路求值。如,c/cpp中&& ||有短路求值,java中&& ||有短路求值,而& |没有短路求值。
对于数值大小比较,建议按照数轴顺序书写。如,应该写MIN_VAL <= i && i <= MAX_VAL而非i >= MIN_VAL && i <= MAX_VAL。(我还挺经常这么写的qwq),应该写MIN_VAL < i而非i > MIN_VAL。这也是为了让式子具有自注释性。
把变量与0比较:
- 如果是布尔值,直接隐式比较即可。
- 对于非布尔值,不要隐式比较,而应该用显式比较。包括数值变量、字符、指针等。
另一些常见问题:
- 为了及时发现把==写成=的问题,可以将常量写在左边。但个人认为这种错误犯得已经不是太多了,强行这样写有时候会非常笨拙,而且有时候比较双方都是变量。
- 如果&&和&、||和|、==和=真的那么容易弄错,可以用宏定义。个人感觉也有点没必要,而且很多编译器都会提供警告。
- java中,a.equals(b)为比较两个对象的值是否相等,==比较的是两个是否为同一对象的引用。(python中也是)
19.2 复合语句(语句块)
一些原则:
- 应该将语句块的两个大括号一起写出,再在中间填充。像vs这样的ide就可以完成这个功能~
- 在if, for, while后面,就算只有一条语句也推荐用大括号,从而清楚显示要执行那一句话,而且日后方便扩充。
19.3 空语句
一些原则与方法:
- 不推荐在if, for, while后面用分号表示空语句,这太容易出错。推荐用一个空的大括号表示,甚至在大括号里写一个空语句从而强调。
(总结一下,在if, for, while后面可以直接接一条语句而不需要大括号是一个为了简化代码用的feature,最后却因为降低了可读性变成了一个bug…) - 可以用一个DoNothing()宏表示空语句。这个宏也可以用在switch语句中,在一种情况后表示这个情况考虑到了,但确实没什么可做的。也方便后续修改补充。
- 空语句大多是为了利用控制循环语句的副作用,如
for(i = 0; str[i] != ‘�’; i++) ;
可以考虑能否通过修改控制语句消除空语句,并使代码更简洁。(不过就个人而言,因为经常这么做,感觉已经很习惯了,可读性并没有那么差。不过这个思想之后会尝试的。)
19.4 深层嵌套
这个问题没有根本的解决方案,只有一些折衷的小技巧。
- 通过多次重复判断减少嵌套层数,需要忍受更复杂的判断与冗余代码。如,对代码
if( statusA ){
// do sth1
if( statusB ){
// do sth2
if( statusC ){
// do sth3
if( statusD ){
// do sth4
}
}
}
}
修改为
if( statusA ){
// do sth1
if( statusB ){
// do sth2
}
}
if( statusA && statusB && statusC ){
// do sth3
if( statusD ){
// do sth4
}
}
- 用break return简化嵌套,这个读书笔记(五)中也有提到 。
- 假如可以,将嵌套转化为if-else语句串,尤其是为变量确定区间时。
- 如果嵌套的深层代码反复出现,可以将其写作子程序。
- 在OOP语言中,使用继承类和函数的多态,简化对于对象类型的判断。
19.5 结构化编程
(这个名词又是万能的Dijkstra提出的)
核心思想:应用程序应该采用单入单出的结构,而不应该在内部甚至在程序之间随意跳转。
结构化编程的三个组成部分:顺序、选择(if-else可以看作选择)、迭代(循环可以看作迭代)。
作者认为,所有非结构化的控制结构,如return break continue throw-catch,使用时都应该抱有警惕。
19.6 程序复杂度
一般来说,程序越复杂,出错可能性越大。
度量复杂度的一种方法,为记录代码中的“决策点”,即控制结构的分支或者逻辑表达式的组合:
- 从1开始,一直往下阅读程序
- 一旦遇到这样的词语(或者类似功能的词)就加一:if while for repeat and or…
- 给case中每种情况加一
对于子程序,0 ~ 5个决策点挺不错,5 ~ 10个可以接受,更多的就应该考虑简化结构或者提取一部分作为另一个子程序。
这个标准不是绝对的,但应该起到警示作用。
我试着数了几个我的代码……发现夸张一点的可以到20多个……emmmm突然反思人生
第二十章 代码质量概述
从这一章起,进入第五部分代码改善。这一章是对代码质量衡量的综述。
20.1 软件质量的特性
外在特性(面向用户):正确性、可用性、效率(时间与空间)、可靠性(可以用平均无故障时间衡量(这个词感觉最近在哪里见过?微机原理或者计网?))、完整性(程序能够阻止未经验证或者不正确的访问)、适应性、精确性、健壮性。
各个外在特性是相互关联的,典型的关联如图:

内在特性(面向程序员):可维护性、灵活性、可移植性、可重用性、可读性、可测试性、可理解性(比可读性更高一层的要求)。
20.2 改善软件质量的技术
普遍的技术:
- 明确定义软件的质量目标,即应该关注哪些外在质量,并明确规定质量需要保证。目标不能随意变动。
假如编程者理解的质量目标与用户不同,就会南辕北辙(这一点在现有的软工课程中已经感受到了。)。
而如果没有规定质量的重要性,编程者可能会把速度看得高于质量,从而编出快速完成但十分糟糕的代码。
书中举了一个小实验,证明明确的目标能驱使程序员实现,而且没有哪个程序员能够兼顾所有目标。 - 测试。
- 需要一套软件构件指南,我的理解相当于是一份内部文档,规定了解决哪些问题、采用什么架构、约定哪些编码风格、如何进行测试等。
- 正式与非正式技术复查。
开发过程中:
- 不要毫无节制地变更需求。我也在软工课程中明确地感受到了变更需求的恐怖,并且打算绝对不要在团队项目中发生这种事情。这样不仅会浪费时间,还会打乱架构。
- 对结果进行量化。但书中没有讨论如何进行量化,而推荐了Principles of software Engineering(很奇怪地software没有首字母大写)。之后再看。
- 制作原型。原型技巧与相关联的曳光弹技巧在之前的读书笔记中讨论过很多了。
20.3 不同质量保障技术的相对效能
话说把technique翻译成技术怎么总觉得怪怪的…
缺陷检测率

值得注意的是,这些错误检测率都不足够高。这提醒我们应该综合使用多种方法。
书中提出,人工方法和计算机方法各自适合检查不同的错误。如阅读代码能找到更多接口错误,功能测试能找到更多控制错误。
书中引述了“极限编程”方法,认为它的高错误检出率来源于多种方法的结合使用。
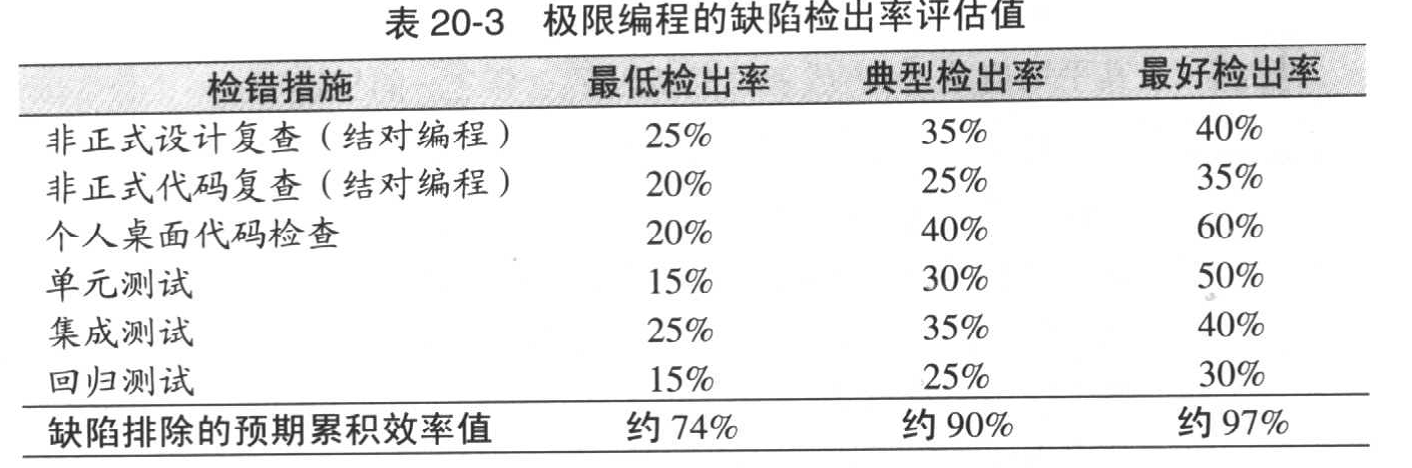
这意味着,虽然单元测试必须要做,但并不能够仅仅依赖单元测试。(头疼。)
找出错误的成本
人工阅读显著小于测试。
修正错误的成本
一个错误待的时间越长,修正成本就越大。
另外,人工阅读发现的错误属于“一步到位”型错误,可以直接修改,成本较低;测试发现的错误还需要进行调试分析才能找到,因而成本较高。(我经常测试结果错了,调试之后发现是我自己算的期望值算错了……
20.4 何时开始质量保证工作
尽早……
20.5 软件质量的普遍原理
更高质量的软件不一定会耗费更多时间,反而会节约很多返工的时间。