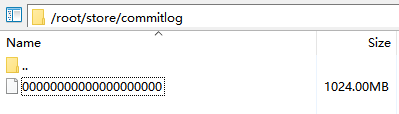
CommitLog
消息内容原文的存储文件,同Kafka一样,消息是变长的,顺序写入,生成规则:
每个文件的默认1G =1024 * 1024 * 1024,commitlog的文件名fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1 073 741 824Byte;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824, 消息存储的时候会顺序写入文件,当文件满了则写入下一个文件。
ConsumeQueue
ConsumeQueue中并不需要存储消息的内容,而存储的是消息在CommitLog中的offset。也就是说ConsumeQueue其实是CommitLog的一个索引文件。一个ConsumeQueue文件对应topic下的一个队列。
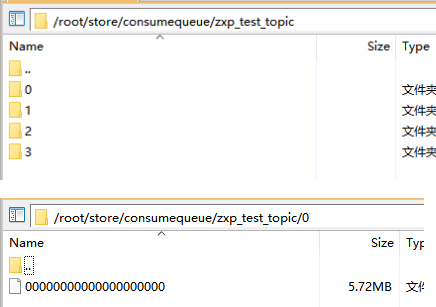
ConsumeQueue是定长的结构,每1条记录固定的20个字节。很显然,Consumer消费消息的时候,要读2次:先读ConsumeQueue得到offset,再通过offset找到CommitLog对应的消息内容。

ConsumeQueue的作用
- 通过broker保存的offset(offsetTable.offset json文件中保存的ConsumerQueue的下标)可以在ConsumeQueue中获取消息,从而快速的定位到commitLog的消息位置
- 过滤tag是也是通过遍历ConsumeQueue来实现的(先比较hash(tag)符合条件的再到consumer比较tag原文)
- 并且ConsumeQueue还能保存于操作系统的PageCache进行缓存提升检索性能
下面是我解析的ConsumeQueue
public static void main(String[] args) throws IOException { decodeCQ(new File("D:\00000000000000000000")); } static void decodeCQ(File consumeQueue) throws IOException { FileInputStream fis = new FileInputStream(consumeQueue); DataInputStream dis = new DataInputStream(fis); long preTag = 0; long count = 1; while (true) { long offset = dis.readLong(); int size = dis.readInt(); long tag = dis.readLong(); if (size == 0) { break; } preTag = tag; System.out.printf(" %d %d %d ", tag, size, offset); } fis.close(); }
hash(tag)|size|offset(commitLog) 3552231 191 180081 3552231 191 180654 3552231 191 180845 3552231 191 182182 3552231 192 182565 121074 201 182757 3552231 245 190411 3552231 245 190656 3552231 245 190901 3552231 245 191146 3552231 245 191391 3552231 245 191636 3552231 245 191881 99 197 219910 99 197 220107 99 197 220304
offsetTable.offset(json中保存)
和commitLog的offset不是一回事,这个offset是ConsumeQueue文件的(已经消费的)下标/行数,可以直接定位到ConsumeQueue并找到commitlogOffset从而找到消息体原文。这个offset是消息消费进度的核心
offset持久化 类型(父类是OffsetStore):
- 本地文件类型:DefaultMQPushConsumer的BROADCASTING模式,各个Consumer没有互相干扰,使用LoclaFileOffsetStore,把Offset存储在Consumer本地
- Broker代存储类型:DefaultMQPushConsumer的CLUSTERING模式,由Broker端存储和控制Offset的值,使用RemoteBrokerOffsetStore
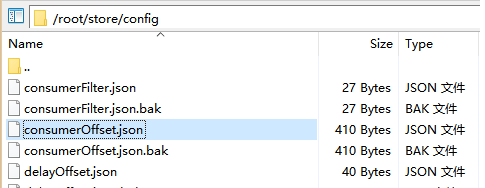
{ "offsetTable":{ "zxp_test_topic@zxp_test_group2":{0:16,1:17,2:23,3:43 }, "TopicTest@please_rename_unique_group_name_4":{0:250,1:250,2:250,3:250 }, "%RETRY%zxp_test_group2@zxp_test_group2":{0:3 }, "%RETRY%please_rename_unique_group_name_4@please_rename_unique_group_name_4":{0:0 }, "%RETRY%zxp_test_group3@zxp_test_group3":{0:0 }, "order_topic@zxp_test_group3":{0:0,1:3,2:3,3:3 } } }
indexFile
如果我们需要根据消息ID,来查找消息,consumequeue 中没有存储消息ID,如果不采取其他措施,又得遍历 commitlog文件了,indexFile就是为了解决这个问题的文件。
偏移量总结
由于出现了多个偏移量的概念,所以我总结一下:
1、CommitLog中的offset(消息体偏移量)
体现在commitlog文件名称中,对应这个CommitLog文件所有消息在整个topic的队列中起始偏移量(方便通过ConsumeQueue.commitlogOffset找到当前要消费的消息存在于哪个commitlog文件)
2、ConsumeQueue中的commitlogOffset(消息体偏移量)
定位了当前这条消息在commitlog中的偏移量
3、offsettable.offset(下标)
定位了当前已经消费的ConsumeQueue的下标是哪条消息