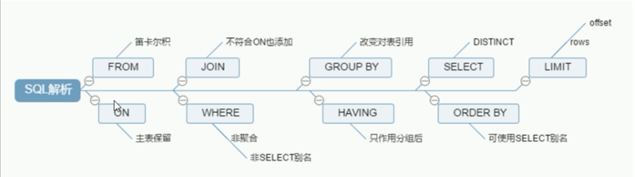
-- 查询语法 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_condition>
机器对查询语句的解读
ROM <left_table> ON <join_condition> <join_type> JOIN <right_table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> select DISTINCT <select_list> ORDER BY <order_by_condition> LIMIT <limit_condition>
一、条件查询
-- 语法: SELECT 查询列表 FROM 表名 WHERE 筛选条件;
一、按条件表达式筛选 简单条件运算符:> < = != <> >= <= 二、按逻辑表达式筛选 逻辑运算符: 作用:用于连接条件表达式 && || ! and or not &&和and:两个条件都为true,结果为true,反之为false ||或or: 只要有一个条件为true,结果为true,反之为false !或not: 如果连接的条件本身为false,结果为true,反之为false 三、模糊查询 like between and in is null
二、排序查询
-- 语法 SELECT 查询列表 FROM 表名 WHERE 筛选条件 ORDER BY 排序的字段或表达式;
特点
2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段
3、order by子句在查询语句的最后面,除了limit子句
三、分组查询
-- 语法 SELECT 查询列表 FROM 表 [ WHERE 筛选条件 ] GROUP BY 分组的字段 [ORDER BY 排序的字段 ] ;
特点: 1、和分组函数一同查询的字段必须是group by后出现的字段。
2、筛选分为两类:分组前筛选和分组后筛选
| 针对的表 | 位置 | 连接的关键字 | |
|---|---|---|---|
| 分组前筛选 | 原始表 | group by前 | where |
| 分组后筛选 | group by后的结果集 | group by后 | having |
四、连接查询
分类: 按年代分类: sql92标准:仅仅支持内连接 sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接 按功能分类: 内连接: 等值连接 非等值连接 自连接 外连接: 左外连接 右外连接 全外连接 交叉连接 union [all]
七中Join查询
-- 测试数据 CREATE TABLE tbl_dept ( id INT (11) NOT NULL AUTO_INCREMENT, deptName VARCHAR (30) DEFAULT NULL, locadd VARCHAR (40) DEFAULT NULL , PRIMARY KEY(id) ) ENGINE=INNODB AUTO_INCREMENT =1 DEFAULT CHARSET =utf8; CREATE TABLE tbl_emp( id INT(11) NOT NULL AUTO_INCREMENT, NAME VARCHAR(30) DEFAULT NULL, deptid INT(11) DEFAULT NULL, PRIMARY KEY(id), KEY fk_dept_id (deptid ) #CONSTRAINT fk_dept_id FOREIGN KEY (deptid) REFERENCE tbl_dept (id) ) ENGINE=INNODB AUTO_INCREMENT =1 DEFAULT CHARSET =utf8; INSERT INTO tbl_dept(deptname,locadd) VALUES('HD',11); INSERT INTO tbl_dept(deptname,locadd) VALUES('HR',12); INSERT INTO tbl_dept(deptname,locadd) VALUES('MK',13); INSERT INTO tbl_dept(deptname,locadd) VALUES('MIS',14); INSERT INTO tbl_dept(deptname,locadd) VALUES('FD',15); INSERT INTO tbl_emp(NAME,deptid) VALUES('z3',1); INSERT INTO tbl_emp(NAME,deptid) VALUES('z4',1); INSERT INTO tbl_emp(NAME,deptid) VALUES('z5',1); INSERT INTO tbl_emp(NAME,deptid) VALUES('w5',2); INSERT INTO tbl_emp(NAME,deptid) VALUES('w6',2); INSERT INTO tbl_emp(NAME,deptid) VALUES('w7',7);

4.1、A、B表的共有
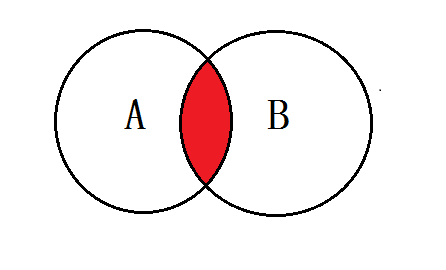
-- 语法:SELECT <selecet_list> FROM tbA A INNER JOIN tbB B ON A.key = B.key SELECT * FROM tbl_emp e INNER JOIN tbl_dept d ON e.`deptid` =d.`id`
4.2、A表的独有加A、B表的共有

-- 语法:SELECT <selecet_list> FROM tbA A LEFT JOIN tbB B ON A.key = B.key SELECT * FROM tbl_emp e LEFT JOIN tbl_dept d ON e.`deptid` =d.`id`
4.3、B表的独有加A、B表的共有
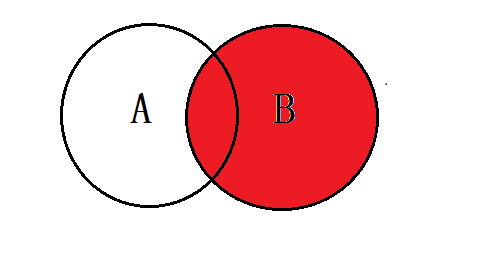
-- 语法:SELECT <selecet_list> FROM tbA A INNER JOIN tbB B ON A.key = B.key SELECT * FROM tbl_emp e RIGHT JOIN tbl_dept d ON e.`deptid` =d.`id`
4.4、A表的独有

-- 语法:SELECT <selecet_list> FROM tbA A LEFT JOIN tbB B ON A.key = B.key WHERE B.key IS NULL SELECT * FROM tbl_emp e LEFT JOIN tbl_dept d ON e.`deptid` =d.`id` WHERE d.`id` IS NULL
4.5、B表的独有

-- 语法:SELECT <selecet_list> FROM tbA A RIGHT JOIN tbB B ON A.key = B.key WHERE A.key IS NULL SELECT * FROM tbl_emp e LEFT JOIN tbl_dept d ON e.deptid = d.id WHERE d.id IS NULL
4.6、A表的独有+B表的独有+A、B表的共有
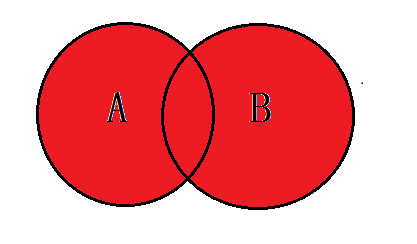
-- 语法:SELECT <selecet_list> FROM tbA A FULL OUTER JOIN tbB B ON A.key = B.key # 默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。 SELECT * FROM tbl_emp e RIGHT JOIN tbl_dept d ON e.`deptid` =d.`id` UNION SELECT * FROM tbl_emp e LEFT JOIN tbl_dept d ON e.`deptid` =d.`id`
4.7、A表的独有+B表的独有
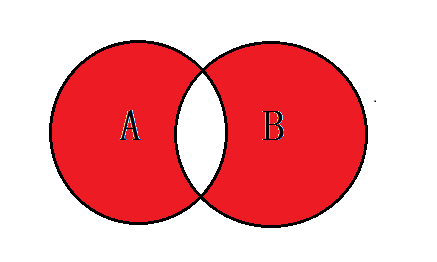
-- 语法:SELECT <selecet_list> FROM tbA A FULL OUTER JOIN tbB B ON A.key = B.key where # A.key IS NULL OR B.key IS NULL SELECT * FROM tbl_emp e LEFT JOIN tbl_dept d ON e.`deptid` =d.`id` WHERE d.`id` IS NULL UNION SELECT * FROM tbl_emp e RIGHT JOIN tbl_dept d ON e.`deptid` =d.`id` WHERE e.`id` IS NULL
五、分页查询
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
-- 语法: SELECT 查询列表 FROM 表 [ JOIN TYPE JOIN 表 2 ON 连接条件 WHERE 筛选条件 GROUP BY 分组字段 HAVING 分组后的筛选 ORDER BY 排序的字段 ] LIMIT [ OFFSET, ] size ;
-
offset要显示条目的起始索引(起始索引从0开始)
-
size 要显示的条目个数
特点:
①limit语句放在查询语句的最后
②公式 要显示的页数 (page-1)*size,每页的条目数size