https://www.kuaidaili.com/free/
代码如下:
import requests from bs4 import BeautifulSoup # 获取网站数据 def get_data(url): headers = { 'user-agent': 'Mozilla/5.0' } html = requests.get(url, headers) html.encoding = 'utf-8' return html.text # 解析网站数据 def parse_dara(html): soup = BeautifulSoup(html, 'html.parser') ''' protocol = soup.find_all(attrs={'data-title': '类型'}) ip = soup.find_all(attrs={'data-title': 'IP'}) port = soup.find_all(attrs={'data-title': 'PORT'}) ''' # 协议 地址 端口 protocol = soup.select('#list > table > tbody > tr > td:nth-child(4)') ip = soup.select('#list > table > tbody > tr > td:nth-child(1)') port = soup.select('#list > table > tbody > tr > td:nth-child(2)') data = [] # 存放代理链接 for i in range(0, len(ip)): # 要求len(ip), len(port) len(protocol)的值一样 temp = protocol[i].get_text()+'://'+ip[i].get_text()+':'+port[i].get_text() # 拼接成url data.append(temp) # 拼接后的数据,加入到列表 return data # 保存数据 def save_data(data): for item in data: with open('output\'+proxy, 'a+') as f: f.write(item) f.write(' ') if __name__=='__main__': proxy = 'proxy.txt' url = 'https://www.kuaidaili.com/free/inha/1' html = get_data(url) data = parse_dara(html) save_data(data) print('爬虫结束')
结果:
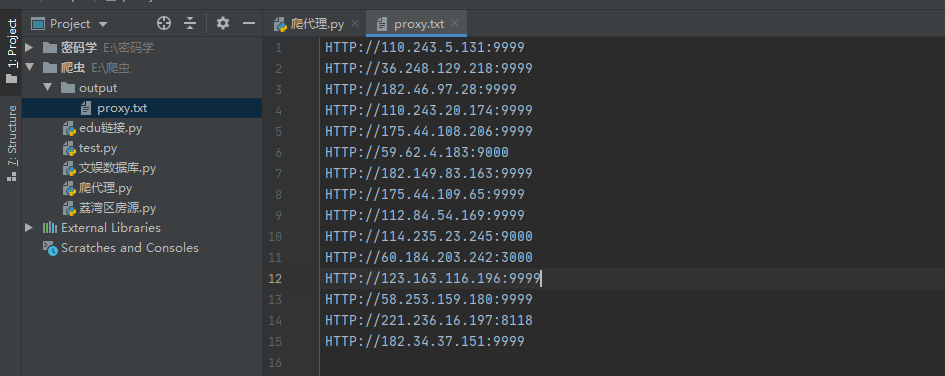
只爬了第一页的代理,其他几页,加个循环就解决了。