图数据库
在如今数据库群雄逐鹿的时代中,非关系型数据库(NoSQL)已经占据了半壁江山,而图数据库(Graph Database)更是攻城略地,成为其中的佼佼者。
所谓图数据库,它应用图理论(Graph Theory)可以存储实体的相关属性以及它们之间的关系信息。最常见例子就是社会网络中人与人之间的关系。相比于关系型数据库(比如MySQL等),图数据库更能胜任这方面的任务。
图数据库现已涌现出许多出众的软件,比如笔者写过的文章Neo4j入门之中国电影票房排行浅析中的Neo4j,Twitter为进行关系数据分析而构建的FlockDB,高度可扩展的分布式图数据库JanusGraph以及Google的开源图数据库Cayley等。
本文将具体介绍Cayley图数据库。
Cayley图数据库的简介
Cayley图数据库是 Google 的一个开源图(Graph)数据库,其灵感来自于 Freebase 和 Google 的知识图谱背后的图数据库。它采用Go语言编写而成,运行命令简单,一般只需要3到4个命令即可。同时,它拥有RESTful API,内建查询编辑器和可视化界面,支持多种查询语言,比如JavaScript,MQL等。另外,它还能支持多种后端数据库储存,比如MySQL,MongoDB, LevelDB等,性能良好,测试覆盖率也OK,功能十分丰富且强大。
当然,对于我们而言,最重要的特性应该是开源。Cayley图数据库的官方Github地址为:https://github.com/cayleygraph/cayley 。
下面将具体介绍如何安装及使用Cayley图数据库。
安装及说明
关于Cayley图数据库的安装,不同的操作系统的安装方式不一样。下载的网址为:https://github.com/cayleygraph/cayley/releases, 截图如下:
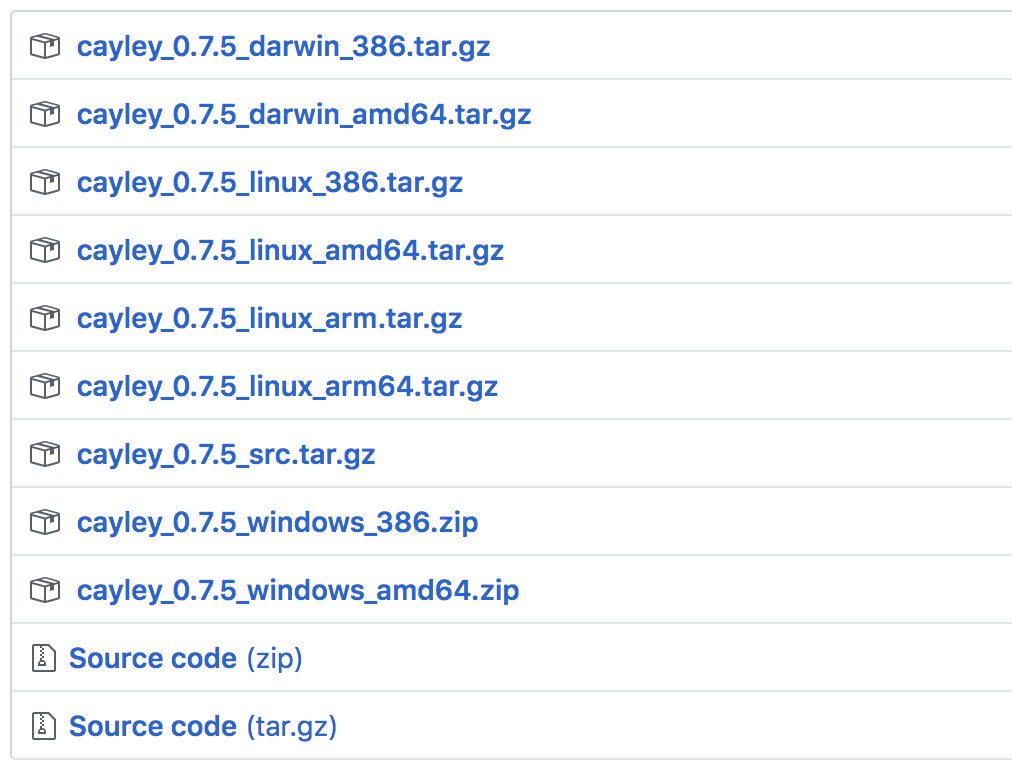
读者可依据自己的电脑系统下载相应的文件,笔者的电脑为Mac,因此选择cayley_0.7.5_darwin_amd64.tar.gz文件。同时你的电脑上需要安装一款Cayley用来储存后台数据的数据库,笔者选择了MongoDB数据库。
当然,Cayley还为你提供了完整的使用说明文档,可以参考网址:https://github.com/cayleygraph/cayley/blob/master/docs/Quickstart-As-Application.md, 它能帮你快速熟悉Cayley的操作,助你快快上手。笔者会用更简单的方式帮你熟悉该图数据库。
So, let's begin!
数据准备
为了能够更好地了解Cayley图数据库,我们应该从数据开始一步步地来构建图数据库,并实现查询功能。本文的数据来源于文章Neo4j入门之中国电影票房排行浅析, 其中爬取了中国电影票房信息,如下:

以及每部电影中的主演信息,如下:
得到了两个表格文件movies.csv和actor.csv,文件的内容如下:
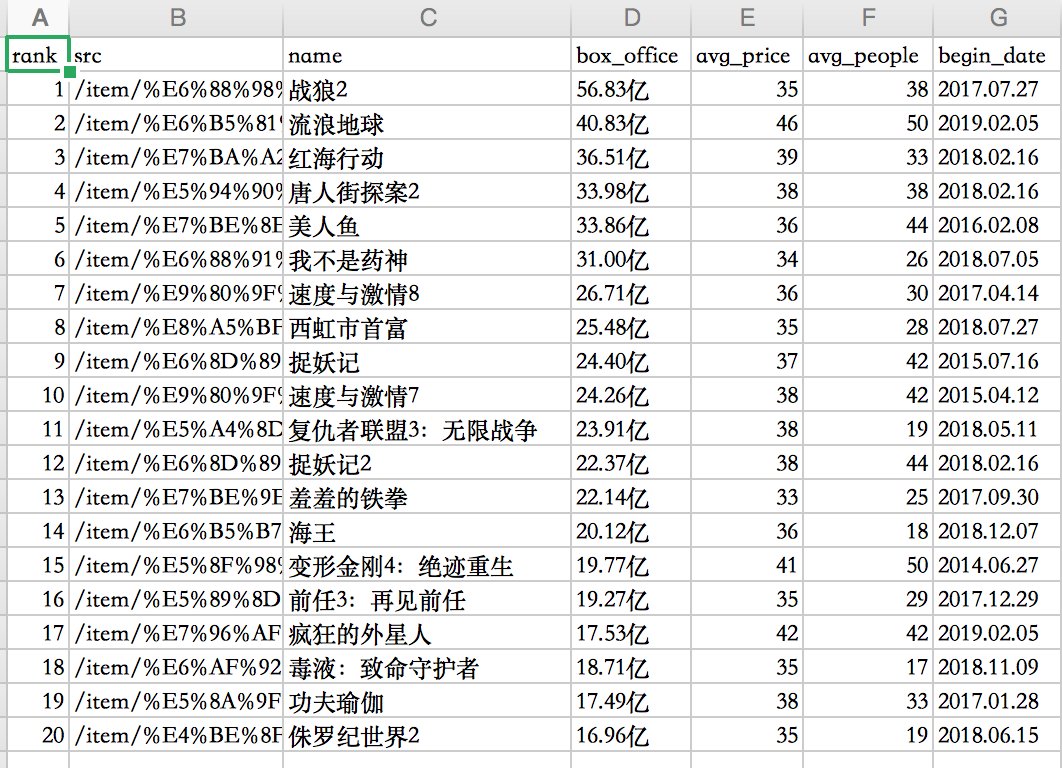

数据准备完毕。如读者需要下载该数据,可以参考网址:https://github.com/percent4/Neo4j_movie_demo 。
三元组文件
Cayley数据库支持三元组文件导入,所谓三元组,指的是主语subject,谓语predicate 以及宾语object,每个三元组为一行。
Cayley数据库支持的三元组文件以nq为后缀,每个三元组为一行,主语、谓语、宾语中间用空格分开,同时还需要注意一下事项(笔者亲自踩坑的经历):
- 注意空格,空格是划分实体的标志;
- 注意","是关键字,也不能在实体中出现;
- 不能在实体中出现换行符(比如 );
- 不能出现重复的数据(实体重复、三元组重复都不行)。
接着我们利用Python程序将movies.csv和actors.csv文件处理成三元组。我们抽取的原则如下:
- 电影名,演员名为实体;
- 电影名与电影的关系为ISA,即电影名 ISA Movie;
- 演员名与电影名的关系为ACT_IN,即演员名 ACT_IN 电影名;
- 电影名的其余为属性对,即电影名 属性 属性名, 比如战狼2 rank 1.
实现的Python程序如下:
# -*- coding: utf-8 -*-
import pandas as pd
# 读取文件
movies = pd.read_csv('movies.csv')
actors = pd.read_csv('actors.csv')
# print(movies.head())
# 处理电影数据为三元组,抽取的三运组如下:
# 电影名 ISA Movie
# 电影名 属性 属性值
with open('China_Movie.nq', 'w') as f:
name_df = movies['name']
for i in range(name_df.shape[0]):
f.write('<%s> <ISA> <Movie> .
'%name_df[i])
for col in movies.columns:
if col != 'name':
f.write('<%s> <%s> "%s" .
'%(name_df[i], col, movies[col][i]))
# 处理演员数据为三元组,抽取的三运组如下:
# 演员名 ISA Actor
# 演员名 ACT_IN 电影名
with open('China_Movie.nq', 'a') as f:
for i in range(actors.shape[0]):
for actor in actors['actors'][i].split(','):
f.write('<%s> <ACT_IN> <%s> .
' % (actor, actors['name'][i]))
在China_Movie.nq中,共有276个三元组,文件的前几行如下:
<战狼2>
.
<战狼2>"1" .
<战狼2>"/item/%E6%88%98%E7%8B%BC2" .
<战狼2> <box_office> "56.83亿" .
<战狼2> <avg_price> "35" .
<战狼2> <avg_people> "38" .
<战狼2> <begin_date> "2017.07.27" .
<流浪地球>.
<流浪地球>"2" .
<流浪地球>"/item/%E6%B5%81%E6%B5%AA%E5%9C%B0%E7%90%83" .
<流浪地球> <box_office> "40.83亿" .
<流浪地球> <avg_price> "46" .
<流浪地球> <avg_people> "50" .
<流浪地球> <begin_date> "2019.02.05" .
<红海行动>.
导入数据
将China_Movie.nq文件移动至Cayley的data目录下,同时配置cayley_example.yml文件,内容如下:
store:
# backend to use
backend: mongo
# address or path for the database
address: "localhost:27017"
# open database in read-only mode
read_only: false
# backend-specific options
options:
nosync: false
query:
timeout: 30s
load:
ignore_duplicates: false
ignore_missing: false
batch: 10000
在该配置文件中,声明了Cayley的后台数据库为MongoDB,同时制定了ip及端口。
接着运行命令:
./cayley load -c cayley_example.yml -i data/China_Movie.nq
等待数据导入,接着前往MongoDB中查看,如发现MongoDB中存在cayley数据库,则表明数据导入成功。
使用查询语句
接着再输入命令:
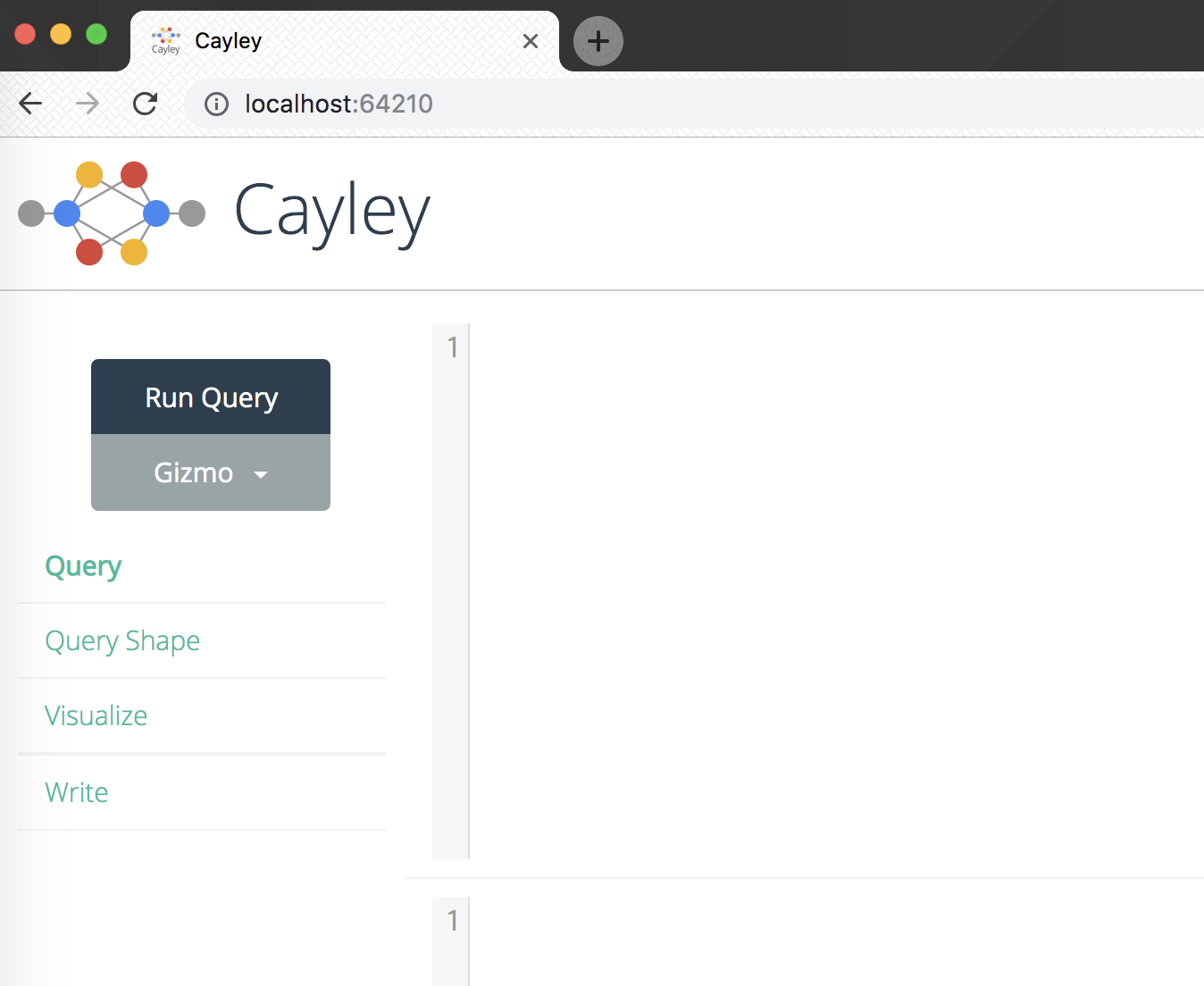
./cayley http -i ./data/China_Movie.nq -d memstore --host=:64210
这样就支持在浏览器中进行查询了,只需要在浏览器中输入http://localhost:64210/ 即可,界面如下:
关于查询语句,它是图数据库的精华所在,而对于Cayley而言,它的查询语句相对来说就比较简单且好理解,具体的查询语句命令可以参考官网: https://github.com/cayleygraph/cayley/blob/master/docs/GizmoAPI.md
,本文将通过几个简单的查询语句来说明怎样对Cayley图数据库进行查询。
查询一共有多少条数据
命令为:
var n = g.V().Count();
g.Emit(n);
其中g代表图,V代表顶点,g.Emit()会将结果以JSON格式返回。输出的结果如下:
{
"result": [
521
]
}
查询全部电影
命令为:
var movies = g.V('<Movie>').In('<ISA>').ToArray();
g.Emit(movies);
返回的结果如下:
{
"result": [
[
"<战狼2>",
"<流浪地球>",
"<红海行动>",
"<唐人街探案2>",
"<美人鱼>",
"<我不是药神>",
"<速度与激情8>",
"<西虹市首富>",
"<捉妖记>",
"<速度与激情7>",
"<复仇者联盟3:无限战争>",
"<捉妖记2>",
"<羞羞的铁拳>",
"<海王>",
"<变形金刚4:绝迹重生>",
"<前任3:再见前任>",
"<疯狂的外星人>",
"<毒液:致命守护者>",
"<功夫瑜伽>",
"<侏罗纪世界2>"
]
]
}
查询电影《流浪地球》的所有属性值
命令为:
var movie = "<流浪地球>";
var attrs = g.V(movie).OutPredicates().ToArray(); //类型为object,即字典
values = new Array();
for (i in attrs) {
var value = g.V(movie).Out(attrs[i]).ToValue();
values[i] = value;
}
key_val_json = new Object();
for (i in attrs) {
key_val_json[attrs[i]]= values[i];
}
g.Emit(key_val_json)
输出结果如下:
{
"result": [
{
"<ISA>": "<Movie>",
"<avg_people>": "50",
"<avg_price>": "46",
"<begin_date>": "2019.02.05",
"<box_office>": "40.83亿",
"<rank>": "2",
"<src>": "/item/%E6%B5%81%E6%B5%AA%E5%9C%B0%E7%90%83"
}
]
}
查询沈腾主演的电影
命令为:
var movies = g.V('<沈腾>').Out('<ACT_IN>').ToArray();
g.Emit(movies);
输出为:
{
"result": [
[
"<西虹市首富>",
"<羞羞的铁拳>",
"<疯狂的外星人>"
]
]
}
查询《捉妖记》与《捉妖记2》的共同演员
命令为:
var actors1 = g.V('<捉妖记>').In('<ACT_IN>');
var actors2 = g.V('<捉妖记2>').In('<ACT_IN>');
var common_actor = actors2.Intersect(actors1).ToArray();//集合交集
g.Emit(common_actor);
输出为:
{
"result": [
[
"<白百何>",
"<井柏然>",
"<曾志伟>",
"<吴君如>"
]
]
}
总结
在本文中,笔者介绍了一种新的图数据库Cayley,并介绍了它的安装方式,以及如何导入三元组数据,进行查询。希望能够给读者一些参考~
虽然是Google开源的图数据库,但在网上关于Cayley图数据库的介绍并不多,而且都未能深入地讲解,大多是照搬官方文档的讲解,希望笔者的讲解能够带来一些进步,这也是笔者写此文的目的。希望此文能多少帮到读者~
注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~