本課主題
- DataSet 实战
DataSet 实战
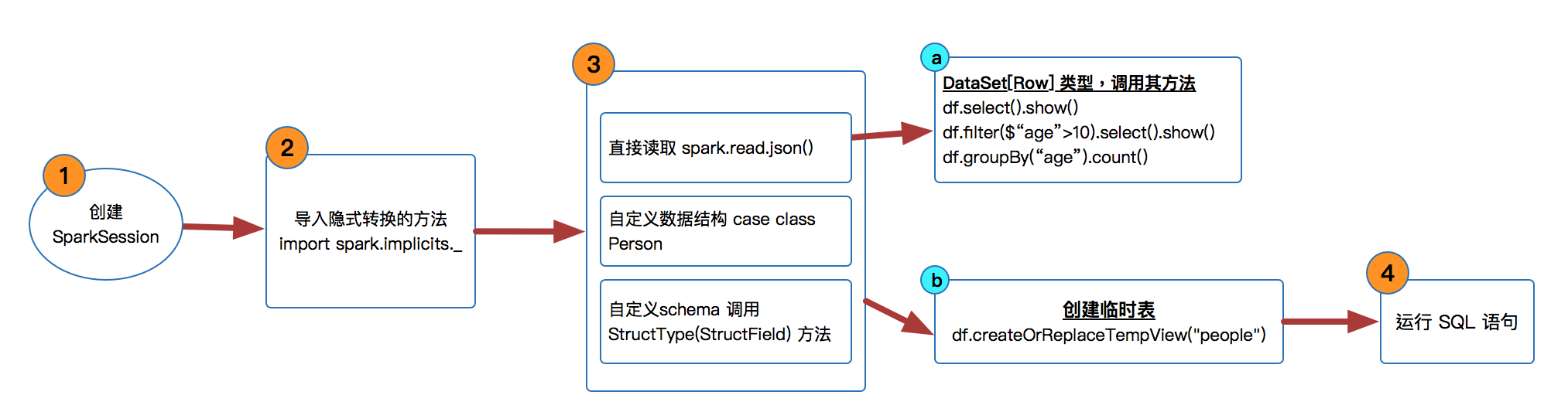
SparkSession 是 SparkSQL 的入口,然后可以基于 sparkSession 来获取或者是读取源数据来生存 DataFrameReader,在 Spark 2.x 版本中已经没有 DataFrame 的 API,它变成了 DataSet[Row] 类型的数据。
- 创建 SparkSession
val spark = SparkSession .builder() .master("local") .appName("Spark SQL Basic Examples") .getOrCreate() - 导入隐式转换的方法
import spark.implicits._ import org.apache.spark.sql.types._ // 自定义schema时导入
-
创建 DataFrame 即 DataSet[Row] 类型数据。
val df = spark.read.json("src/main/resources/general/people.json")- 可以直接调用 DataFrame 很多很好用的方法,比如 select( ),filter( ),groupBy( )
df.show() //打印数据,默认是前20条数据 df.printSchema() df.select("name").show() //提取column是name的数据 df.select($"name",$"age" + 1).show() //提取column是name和age+1的数据 df.filter($"age" > 25).select("name").show() df.groupBy($"age").count().show()
- 可以直接调用 DataFrame 很多很好用的方法,比如 select( ),filter( ),groupBy( )
- 也可以自定义 case class 来创建 DataSet[Row] 类型
val personDF = sc.textFile("src/main/resources/general/people.txt") //personRDD .map(x => x.split(",")) //Array[String] = Array(name, age) .map(attr => Person(attr(0),attr(1).trim().toInt)) .toDF() - 或者用自定义 schema 的方式
val schemaString = "name,age" val fields = schemaString.split(",").map(fieldName => StructField(fieldName, StringType, nullable = true)) val schema = StructType(fields) val personRDD = sc.textFile("src/main/resources/general/people.txt") //personRDD val rowRDD = personRDD.map(_.split(",")).map(attr => Row(attr(0),attr(1).trim())) val personDF = spark.createDataFrame(rowRDD,schema) -
或者是调用 createOrReplaceTempView 方法来创建临时表运行 SQL
personDF.createOrReplaceTempView("people") val sqlDF = spark.sql("SELECT * FROM people") sqlDF.map(people => "Name: " + people(0)).show()
參考資料
资料来源来至 Spark 官方网站