参考美团文档:https://tech.meituan.com/2017/04/21/mt-leaf.html
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统中不同机器产生的id必须不同。
性能测试数据:
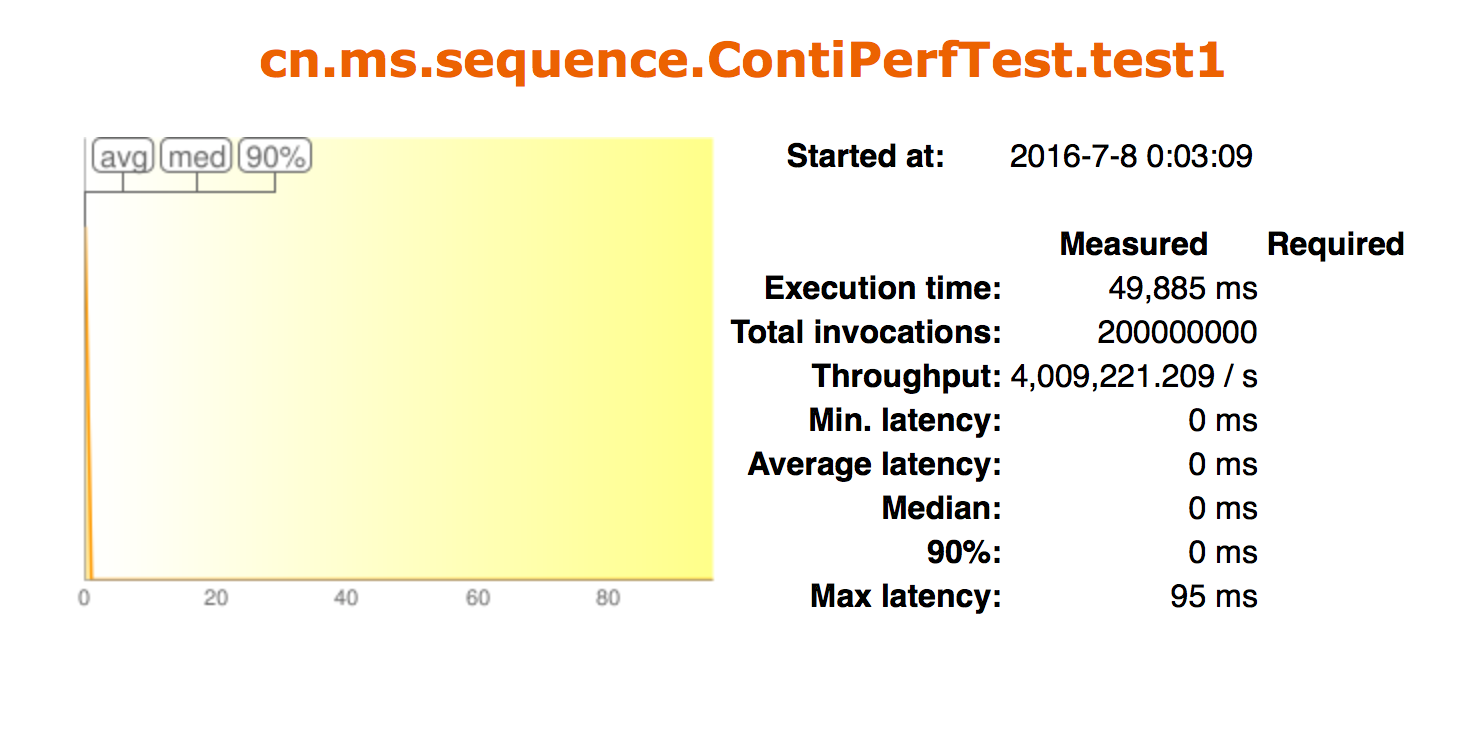
Snowflake算法核心
把时间戳,工作机器id,序列号组合在一起。
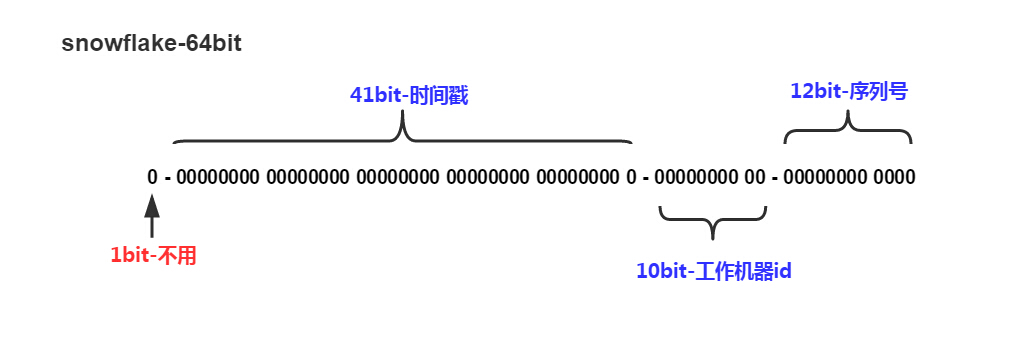
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
package cn.ms.sequence; /** * 基于Twitter的Snowflake算法实现分布式高效有序ID生产黑科技(sequence) * * <br> * SnowFlake的结构如下(每部分用-分开):<br> * <br> * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br> * <br> * 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br> * <br> * 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截) * 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br> * <br> * 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br> * <br> * 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br> * <br> * <br> * 加起来刚好64位,为一个Long型。<br> * SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。 * * @author lry */ public class Sequence { /** 起始时间戳,用于用当前时间戳减去这个时间戳,算出偏移量 **/ private final long startTime = 1519740777809L; /** workerId占用的位数5(表示只允许workId的范围为:0-1023)**/ private final long workerIdBits = 5L; /** dataCenterId占用的位数:5 **/ private final long dataCenterIdBits = 5L; /** 序列号占用的位数:12(表示只允许workId的范围为:0-4095)**/ private final long sequenceBits = 12L; /** workerId可以使用的最大数值:31 **/ private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** dataCenterId可以使用的最大数值:31 **/ private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits); private final long workerIdShift = sequenceBits; private final long dataCenterIdShift = sequenceBits + workerIdBits; private final long timestampLeftShift = sequenceBits + workerIdBits + dataCenterIdBits; /** 用mask防止溢出:位与运算保证计算的结果范围始终是 0-4095 **/ private final long sequenceMask = -1L ^ (-1L << sequenceBits); private long workerId; private long dataCenterId; private long sequence = 0L; private long lastTimestamp = -1L; private boolean isClock = false; /** * 基于Snowflake创建分布式ID生成器 * <p> * 注:sequence * * @param workerId 工作机器ID,数据范围为0~31 * @param dataCenterId 数据中心ID,数据范围为0~31 */ public Sequence(long workerId, long dataCenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (dataCenterId > maxDataCenterId || dataCenterId < 0) { throw new IllegalArgumentException(String.format("dataCenter Id can't be greater than %d or less than 0", maxDataCenterId)); } this.workerId = workerId; this.dataCenterId = dataCenterId; } public void setClock(boolean clock) { isClock = clock; } /** * 获取ID * * @return */ public synchronized Long nextId() { long timestamp = this.timeGen(); // 闰秒:如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < lastTimestamp) { long offset = lastTimestamp - timestamp; if (offset <= 5) { try { this.wait(offset << 1); timestamp = this.timeGen(); if (timestamp < lastTimestamp) { throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset)); } } catch (Exception e) { throw new RuntimeException(e); } } else { throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", offset)); } } // 解决跨毫秒生成ID序列号始终为偶数的缺陷:如果是同一时间生成的,则进行毫秒内序列 if (lastTimestamp == timestamp) { // 通过位与运算保证计算的结果范围始终是 0-4095 sequence = (sequence + 1) & sequenceMask; if (sequence == 0) { timestamp = this.tilNextMillis(lastTimestamp); } } else { // 时间戳改变,毫秒内序列重置 sequence = 0L; } lastTimestamp = timestamp; /* * 1.左移运算是为了将数值移动到对应的段(41、5、5,12那段因为本来就在最右,因此不用左移) * 2.然后对每个左移后的值(la、lb、lc、sequence)做位或运算,是为了把各个短的数据合并起来,合并成一个二进制数 * 3.最后转换成10进制,就是最终生成的id */ return ((timestamp - startTime) << timestampLeftShift) | (dataCenterId << dataCenterIdShift) | (workerId << workerIdShift) | sequence; } /** * 保证返回的毫秒数在参数之后(阻塞到下一个毫秒,直到获得新的时间戳) * * @param lastTimestamp * @return */ private long tilNextMillis(long lastTimestamp) { long timestamp = this.timeGen(); while (timestamp <= lastTimestamp) { timestamp = this.timeGen(); } return timestamp; } /** * 获得系统当前毫秒数 * * @return timestamp */ private long timeGen() { if (isClock) { // 解决高并发下获取时间戳的性能问题 return SystemClock.now(); } else { return System.currentTimeMillis(); } } }
package cn.ms.sequence; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicLong; /** * 高并发场景下System.currentTimeMillis()的性能问题的优化 * <p><p> * System.currentTimeMillis()的调用比new一个普通对象要耗时的多(具体耗时高出多少我还没测试过,有人说是100倍左右)<p> * System.currentTimeMillis()之所以慢是因为去跟系统打了一次交道<p> * 后台定时更新时钟,JVM退出时,线程自动回收<p> * 10亿:43410,206,210.72815533980582%<p> * 1亿:4699,29,162.0344827586207%<p> * 1000万:480,12,40.0%<p> * 100万:50,10,5.0%<p> * * @author lry */ public class SystemClock { private final long period; private final AtomicLong now; private SystemClock(long period) { this.period = period; this.now = new AtomicLong(System.currentTimeMillis()); scheduleClockUpdating(); } private static class InstanceHolder { public static final SystemClock INSTANCE = new SystemClock(1); } private static SystemClock instance() { return InstanceHolder.INSTANCE; } private void scheduleClockUpdating() { ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(runnable -> { Thread thread = new Thread(runnable, "system-clock"); thread.setDaemon(true); return thread; }); scheduler.scheduleAtFixedRate(() -> now.set(System.currentTimeMillis()), period, period, TimeUnit.MILLISECONDS); } private long currentTimeMillis() { return now.get(); } public static long now() { return instance().currentTimeMillis(); } public static String nowDate() { return String.valueOf(now()); } }
测试类:
package cn.ms.sequence; import org.databene.contiperf.PerfTest; import org.databene.contiperf.junit.ContiPerfRule; import org.junit.Rule; import org.junit.Test; /** * 性能测试 * * @author lry */ public class ContiPerfTest { @Rule public ContiPerfRule i = new ContiPerfRule(); Sequence sequence = new Sequence(0, 0); @Test @PerfTest(invocations = 500, threads = 100) public void test1() throws Exception { System.out.println(sequence.nextId()); } }
测试结果如下:
弱依赖ZooKeeper
除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。一定程度上提高了SLA
解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。
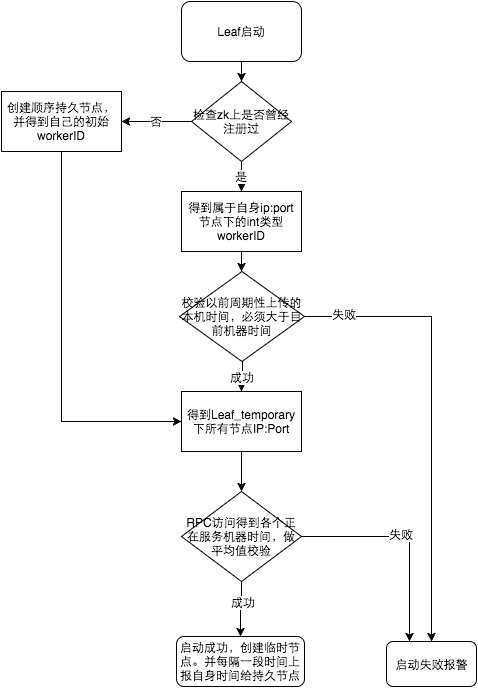
参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
- 若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
- 若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
- 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。
- 否则认为本机系统时间发生大步长偏移,启动失败并报警。
- 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警,如下:
//发生了回拨,此刻时间小于上次发号时间 if (timestamp < lastTimestamp) { long offset = lastTimestamp - timestamp; if (offset <= 5) { try { //时间偏差大小小于5ms,则等待两倍时间 wait(offset << 1);//wait timestamp = timeGen(); if (timestamp < lastTimestamp) { //还是小于,抛异常并上报 throwClockBackwardsEx(timestamp); } } catch (InterruptedException e) { throw e; } } else { //throw throwClockBackwardsEx(timestamp); } } //分配ID
从上线情况来看,在2017年闰秒出现那一次出现过部分机器回拨,由于Leaf-snowflake的策略保证,成功避免了对业务造成的影响。