大神地址 https://blog.csdn.net/vking_wang/article/details/14166593
数据表结构中
数组:
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表:
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
于是诞生了哈希表,同时使用了链表和数组。
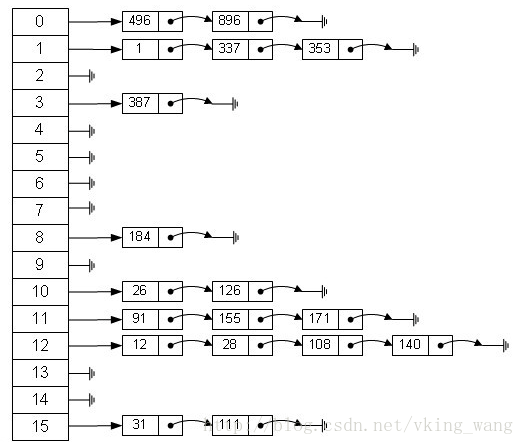
hashMap就是使用了哈希表。
数据占用哪个数组,通过key的hash 前16位与后16位异或得到的值(为了将值分散),再将值与数组长度做与运算(与运算比取模效率更高)
当链表长度大于8时,链表转为红黑树(jdk1.8)
为了更快的查询数据,同时为了减少不必要的浪费空间,当map里的数据个数达到 容量(默认16)*扩容因子(默认0.75) 的个数时,开发扩容,将table的长度扩大一倍(左位移1位)
这是为了查询速度,与尽量不浪费空间的经验值比例