快速开始一个flinksql程序:
表环境准备
//注册表环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val tableEnv: StreamTableEnvironment = TableEnvironment.getTableEnvironment(env)
注册表
stu_row_stream:就是一条输入流,我这里是row类型的输入流(我把默认readtextfile的string流转换为了row流)
//获得table的两种方式,两种方式都需要导入api隐式转换 import org.apache.flink.table.api.scala._ //这个依赖是为了fromdatastream这个方法服务 import org.apache.flink.streaming.api.scala._//这个以来是为了后续把table转换datastream流服务 // // 方式一:通过注册表的方式将把注册到tableEnv中 // tableEnv.registerDataStream("stu_table",stu_row_stream,'id,'name) // //再次扫描表获得表名 // val student_table: Table = tableEnv.scan("stu_table") //方式二:直接从流中转换得到表 val student_table: Table = tableEnv.fromDataStream(stu_row_stream,'id,'name)
执行sql语句
这里我用的是scala 的语法
//定义sql语句 val sql= s""" |select name,count(*) as cnt from ${student_table} |group by name """.stripMargin val result_table: Table = tableEnv.sqlQuery(sql)
转换为datastream
//最后我把table转为了stream,由于我用了聚合的算子所以使用toRetractStream,如果没有用聚合算子就使用toAppendStream
val result_stream: DataStream[(Boolean, Row)] = result_table
.toRetractStream[Row]
result_stream.print()
env.execute()
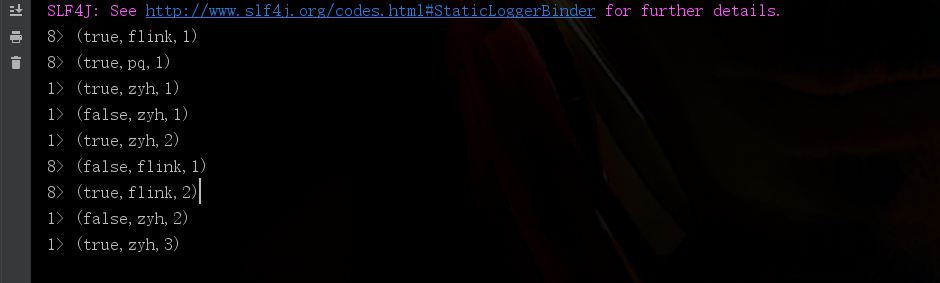
结果解读:
true代表在状态中这条数据没有更改,false代表在状态中这条数据已经丢弃(因为count的结果需要叠加)
基础知识
table转换为datastream流:
1.追加模式 toappendstream
2.撤回模式 retractstream 添加/删除
3.更新插入流 upsert
upsert中包含upsert信息和delete信息
修改/删除,可以
两种模式主要是看是否会用到聚合的情况。

动态表Dynamic Tables:
动态表是随着时间变化的
持续查询:连续查询永远不会停止,并会生成另一个动态表,查询不断的更新动态的结果。
每条流数据其实可以理解为对结果表的插入操作。
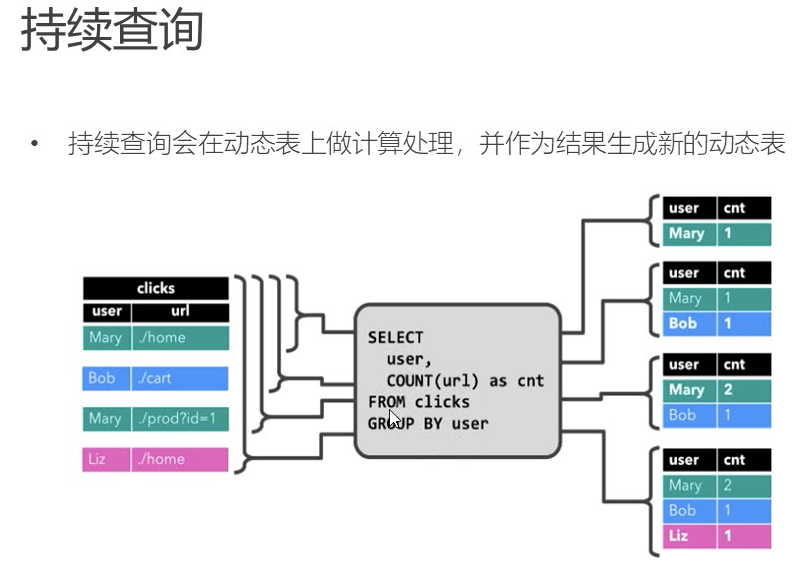
每条流数据来了只会输出有改变的数据。
时间特性 time attributes:
时间属性可以是每个表schema的一部分,定义了时间属性就可以作为一个字段引用,就是常规的时间戳,可以访问并且计算。
定义处理时间:processing time
.proctime
只需要在注册表时最后一个字段加上proctime即可。注意:最后一个字段不是原有的字段,而是在方法中自己添加的字段,因为是处理时间。

定义事件时间:event time
事件时间和水位线需要在流式数据上进行设置。
你可以追加一个事件时间字段,或者使用原来时间字段作为事件时间
.rowtime

窗口:
时间语义需要配合窗口操作才能发挥作用
gruop windows 分组窗口:(整张表)
根据时间或行数据,把数据聚合到组中。

滚动窗口:tumbling windows
可以通过时间开窗,也可以通过行数开窗,之所以行数也要时间字段是因为需要对数据进行排序
滑动窗口:sliding windows
会话窗口:session window
over windows 开窗函数:(针对某行)
针对每个输入行,计算附近行范围的聚合。
适应需求:针对当前行,它之前之后固定范围要做的事情。但是目前还不支持之后的数据,只支持之前的数据。
