1.table api特点:
使得多声明的数据处理起来更为容易,扩展标准sql更为容易
enviroment:

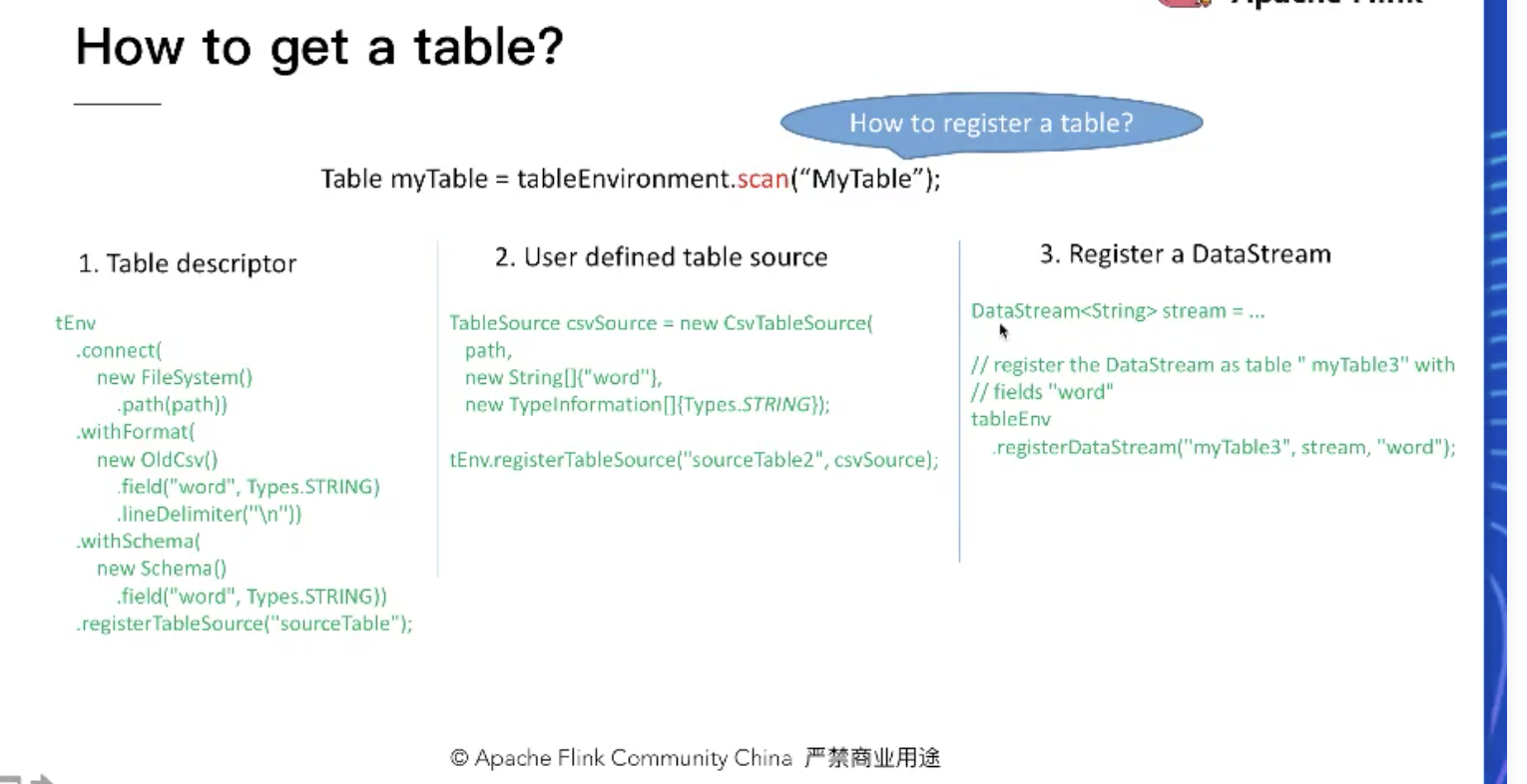
如何得到一个表:
1.自己写table的描述信息
2.通过自定义tablesouce注册到env中
3.datastream也可以通过注册得到一个表
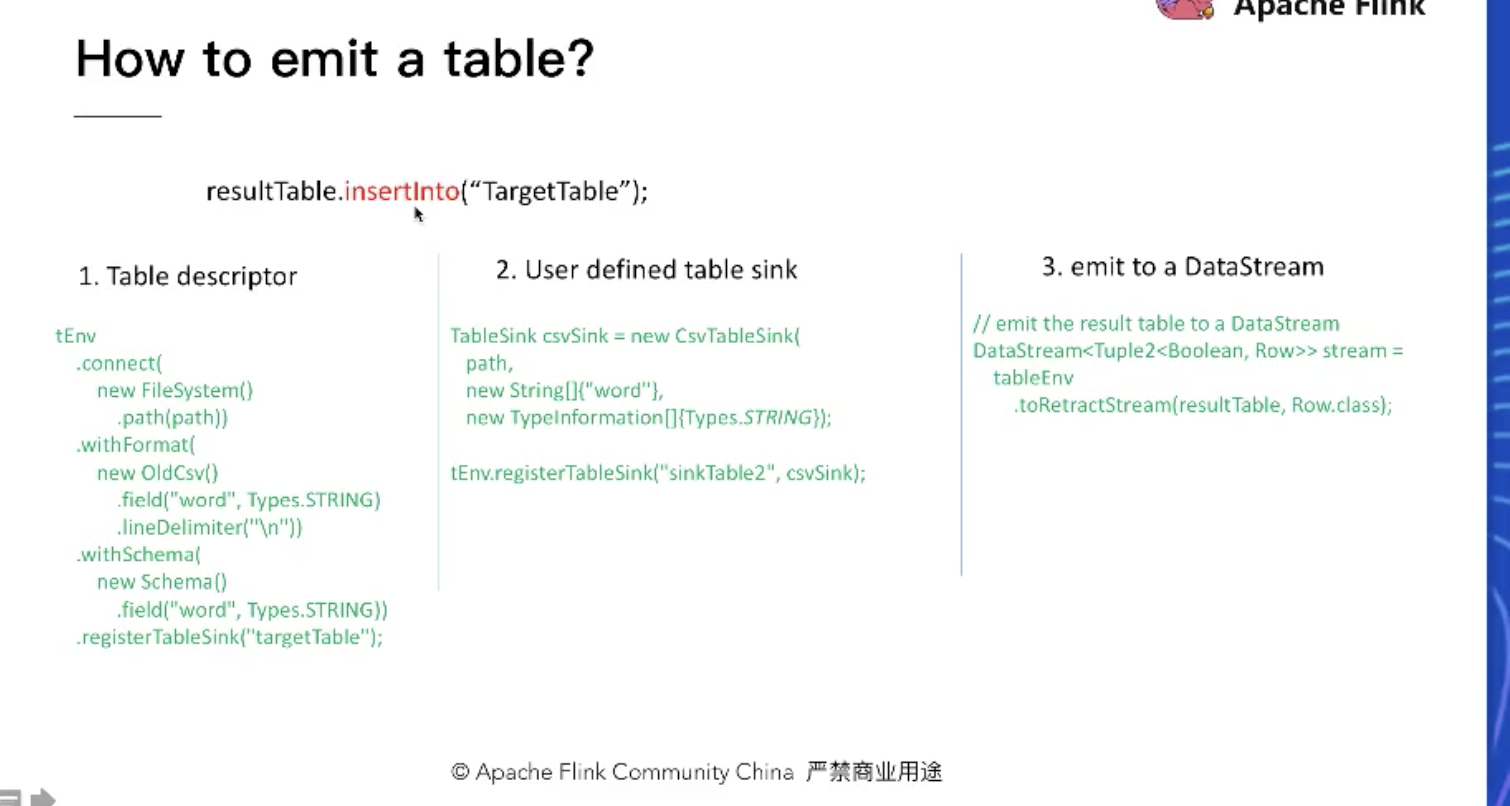
如何输出一个table:
和输入的三种方式是一致的
如何查询一个表:
对列上一些函数:
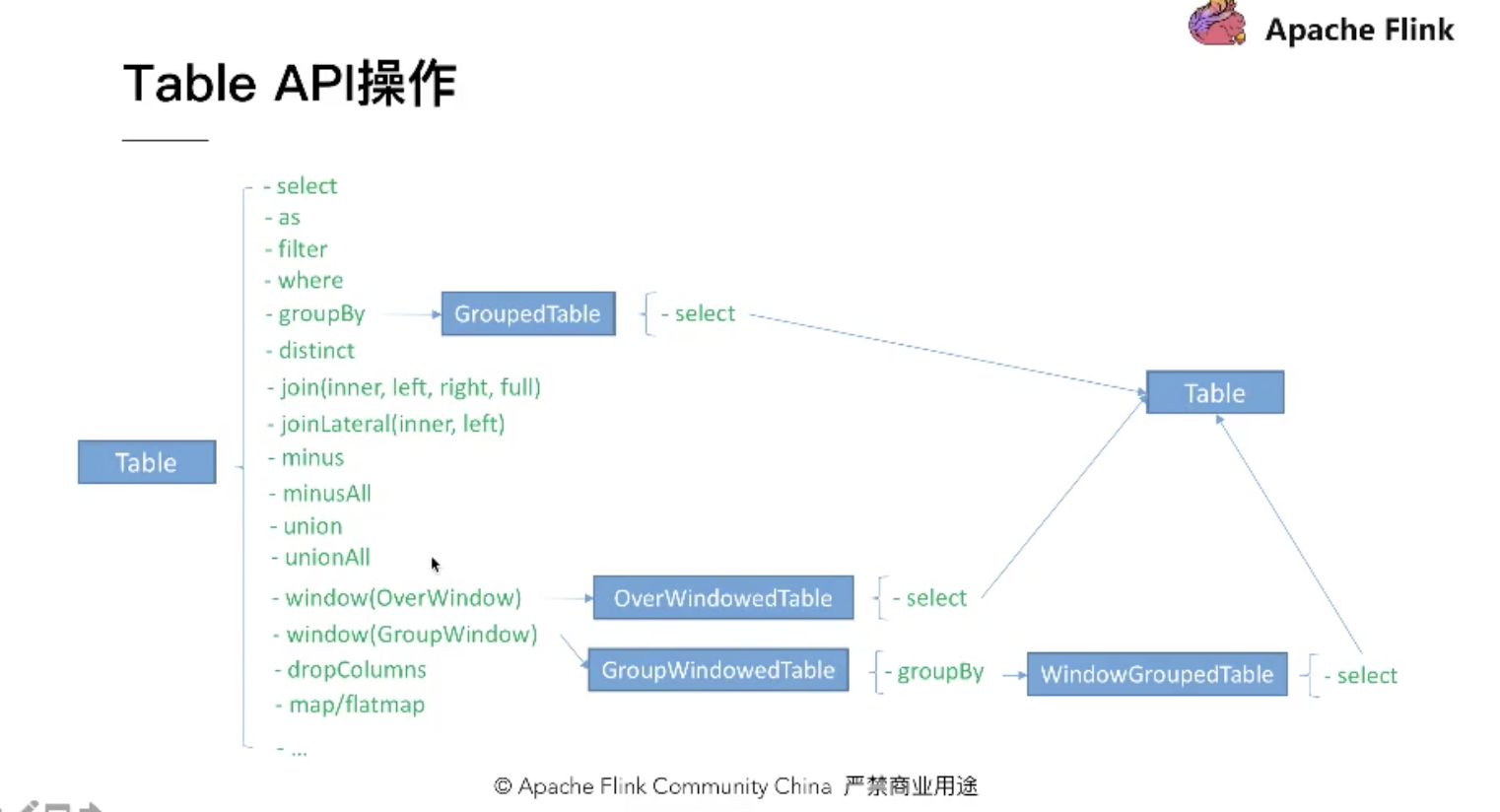
对列上的一些操作:
addcolumns添加,addorreplacecolumns添加并且覆盖,renamecolumns重命名,dropcolumns删除
withcolumns选择指定的列,withoutcolumns反选指定的列
cloumns使用的语法:

可以是字段名,下标,默认下标是从1开始计算的
row-based operation:
map-operation的好处:
比如需要对这个表中的每一列都做一些udf的操作,比如if,cocat这种,
你就需要对每列都写一个udf,但是如果在table上使用map算子就会非常方便

flatmap-opreation:
输入一行-输出多行

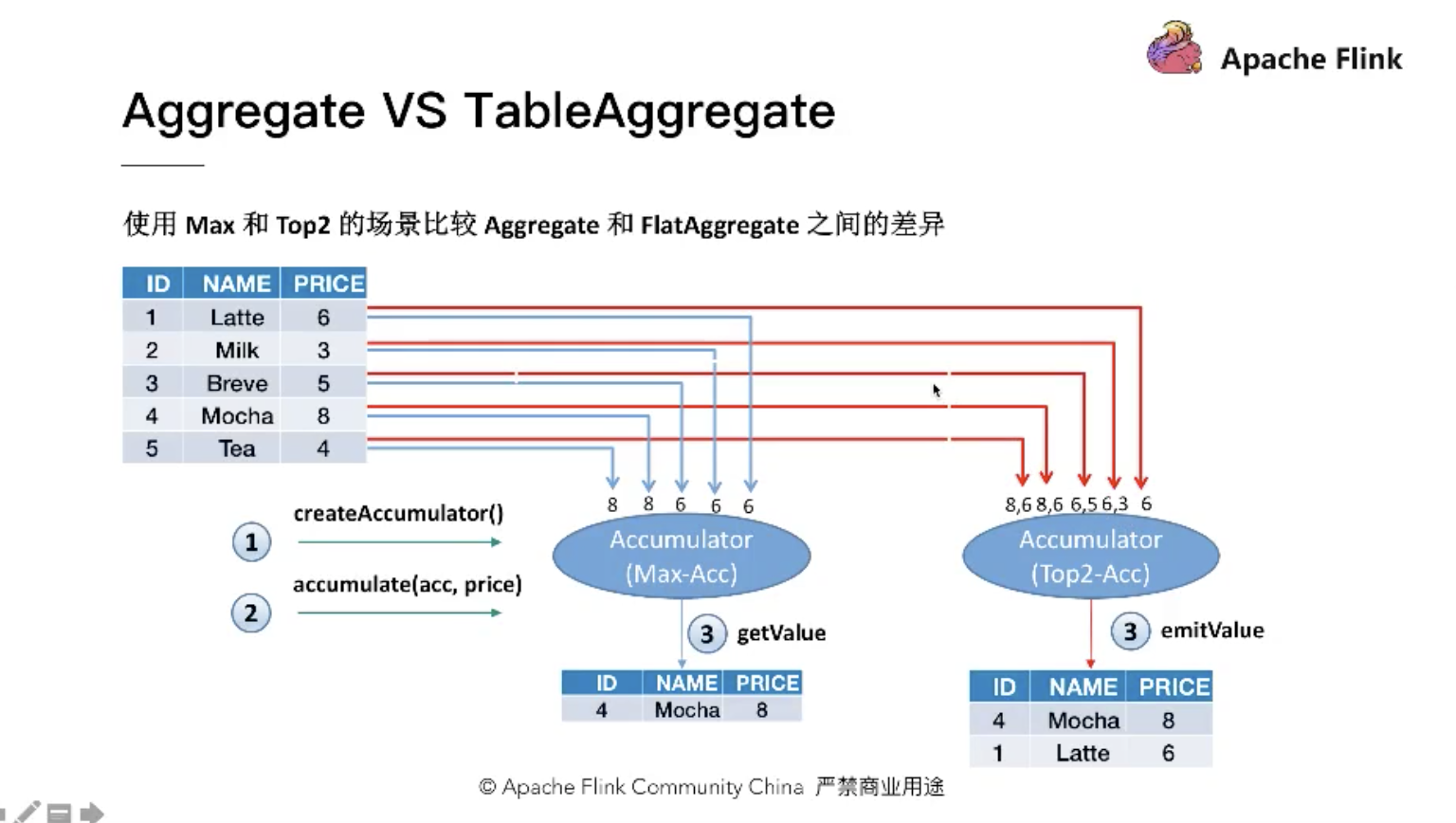
aggregate-operation:
输入多行-输出一行

输入多行-输出多行:topn
flataggregate-operation:

aggregate vs tableaggregate:
窗口:
时间语义需要配合窗口操作才能发挥作用
gruop windows 分组窗口:(整张表)
根据时间或行数据,把数据聚合到组中。
滚动窗口:tumbling windows
可以通过时间开窗,也可以通过行数开窗,之所以行数也要时间字段是因为需要对数据进行排序来取。

滑动窗口:sliding windows

会话窗口:session window
over windows 开窗函数:(针对某行)
针对每个输入行,计算附近行范围的聚合。

无界窗口:over windows

有界over windows:
目前flink只支持preceding 到current row,因为如果要支持following需要等待。

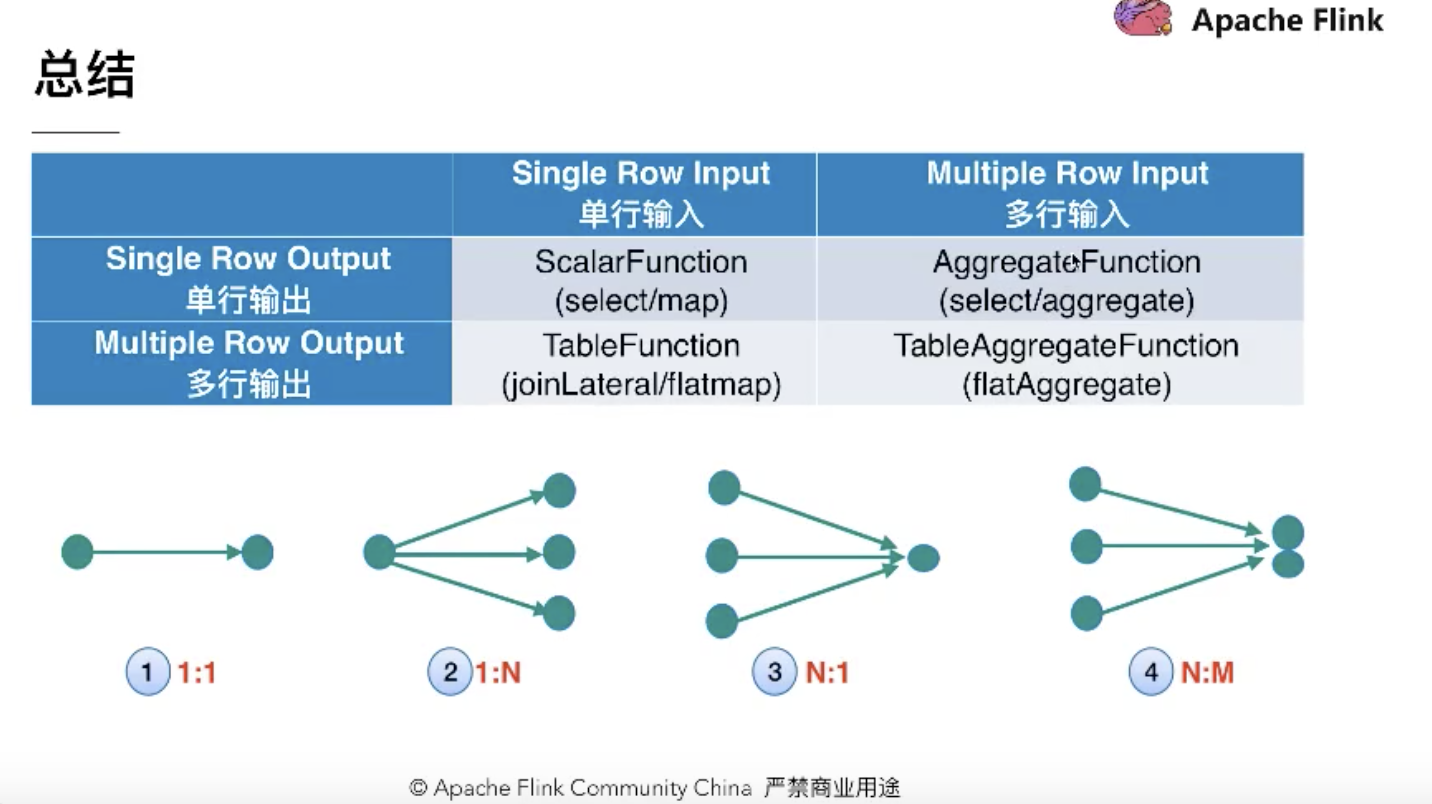
总结: