㈠ 分区表技术概述
⑴ Range 分区
① 例子
create table t
(...列定义...)
partition by range (week_num)
(partition p1 values less than (4)tablespace data0,
partition p2 values less than (5)tablespace data1,
....
);
② 适用场景
Range 分区一般比较适合按时间周期进行数据的存储
③ 优点
用户知道具体数据落在哪个分区
因此、通过分区可以有效实施各种大批量的数据管理操作
比如、删除指定时间段的历史数据管理、对指定分区进行备份恢复或导入导出
④ 缺点
● 分区的数据可能不均匀
● Range分区与记录值相关、实施难度和可维护性相对较差
⑵ List分区
① 例子
create table t
(...列定义...)
partition by list(city)
(partition p1 values ('北京') tablespace data0,
partition p2 values ('上海') tablespace data1,
....
);
Range 和 List 的区别在于、前者是连续、而后者是离散
因此、在优缺点及适用场景方面、大抵相去无几
这里不赘述了
⑶ HASH 分区
① 例子
create table t
(...列的定义..)
partition by hash (customer_no)
partition 8 store in
(data0,data1);
友情提醒哦:Oracle建议HASH分区数一般是2的幂
② 适用场景
HASH分区适合于静态数据
何谓静态数据?
指此类数据一般永远存储在数据库中、不需要进行历史数据迁移
例如:用户资料表、账户信息等
而这类信息的访问大部分通过用户ID或者账号进行
如果按这些字段进行HASH分区、并建立本地前缀分区索引、访问效率相当高哦
③ 优点
● 数据均匀分布
● 实施非常简单
④ 缺点
用户不知道某条记录具体会落在哪个分区
因此、HASH分区不适合大批量数据管理操作
例如、历史数据清理、大批量数据导入导出等
⑷ 组合分区
Oracle组合分区某种程度上讲是一种把优点集中的表现
例如、大多数情况下、第一维按时间字段进行分区、
这样在分区级适合于进行大批量数据管理操作
第二维的HASH或List可进一步提高访问性能或者降低实施难度
11g之前只有:Range-HASH 或 Range-List
㈡ 分区索引技术概述
生产环境中、有时我们会遇到:
已经做了分区表了、怎么性能没有提高啊?甚至更慢啊?
其原因之一或者是没有合理甚至根本没有设计分区索引
先总体认识一下表和索引在分区上的关系:
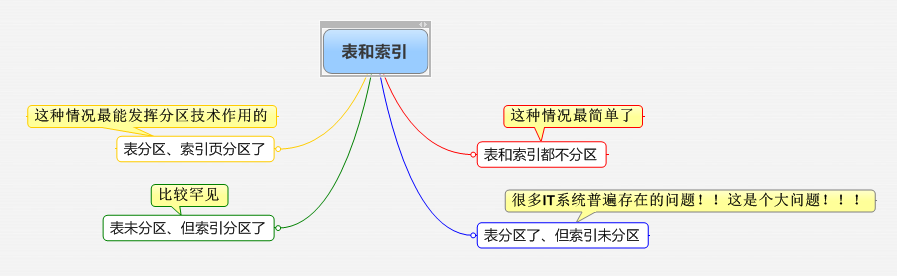
⑴ 本地前缀分区索引
假设分区表为一个交易流水表t、且按交易日期date进行Range分区
如果欲创建date字段上的索引、我们可以:
create index idx_t on t (date) local;
idx_t 就叫做本地前缀索引
所谓本地、指索引的分区方法与对应表的分区方法一样
所谓前缀、指分区字段是索引字段的前缀
优势
● 提高查询性能
● 当某个分区进行drop 或 merge后、Oracle自动对所对应的索引分区进行相同的操作、
整个本地前缀分区索引依然有效、无须rebuild
这样大大保证了表的可用性
⑵ 本地非前缀分区索引
假设我们需要在t表的area字段建立分区索引、我们可以:
create index idx_t_area on t (area) local;
idx_t_area就叫做本地非前缀分区索引
非前缀要按照索引扫描所有的分区、性能可能更低
不过、它能够保证按索引访问的可用性
适用场景:
如果历史数据整理非常频繁、而且不能承受全局分区索引重建的长时间带来的索引不可用
同时、日常交易性能尚能接受、则建议设计为本地非前缀分区索引
⑶ 全局分区索引
假设我们需要在t表的area字段建立分区索引、我们可以:
create index idx_t_g_area on t(area)
global partition by range (area)
(partition p1 less than ...);
所谓全局、是指该索引的分区与表的分区无关
10g以后、Oracle提供2种全局分区索引:
● Global Range Partition Index
● Global HASH Partition Index
缺点:
主要体现在数据的高可用性方面
当DROP分区后、全局分区索引则全部INVALID、除非REBULID
但数据量越大、重建索引的时间越长