作者:谦虚的小K
来源:www.juejin.cn/post/6957696820621344775
导读
当我们交友平台在线上运行一段时间后,为了给平台用户在搜索好友时,在搜索结果中推荐并置顶他感兴趣的好友,这时候,我们会对用户的行为做数据分析,根据分析结果给他推荐其感兴趣的好友。
这里,我采用最简单的SQL分析法:对用户过去查看好友的性别和年龄进行统计,按照年龄进行分组得到统计结果。依据该结果,给用户推荐计数最高的某个性别及年龄的好友。
那么,假设我们现在有一张用户浏览好友记录的明细表t_user_view,该表的表结构如下:
CREATE TABLE `t_user_view` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户id',
`viewed_user_id` bigint(20) DEFAULT NULL COMMENT '被查看用户id',
`viewed_user_sex` tinyint(1) DEFAULT NULL COMMENT '被查看用户性别',
`viewed_user_age` int(5) DEFAULT NULL COMMENT '被查看用户年龄',
`create_time` datetime(3) DEFAULT CURRENT_TIMESTAMP(3),
`update_time` datetime(3) DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3),
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_viewed_user` (`user_id`,`viewed_user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
为了方便使用SQL统计,见上面的表结构,我冗余了被查看用户的性别和年龄字段。
我们再来看看这张表里的记录:

现在结合上面的表结构和表记录,我以user_id=1的用户为例,分组统计该用户查看的年龄在18 ~ 22之间的女性用户的数量:
SELECT viewed_user_age as age, count(*) as num FROM t_user_view WHERE user_id = 1 AND viewed_user_age BETWEEN 18 AND 22 AND viewed_user_sex = 1 GROUP BY viewed_user_age
得到统计结果如下:

可见:
- 该用户查看年龄为18的女性用户数为2
- 该用户查看年龄为19的女性用户数为1
- 该用户查看年龄为20的女性用户数为3
所以,user_id=1的用户对年龄为20的女性用户更感兴趣,可以更多推荐20岁的女性用户给他。
如果此时,t_user_view这张表的记录数达到千万规模,想必这条SQL的查询效率会直线下降,为什么呢?有什么办法优化呢?
想要知道原因,不得不先看一下这条SQL执行的过程是怎样的?
Explain
我们先用explain看一下这条SQL:
EXPLAIN SELECT viewed_user_age as age, count(*) as num FROM t_user_view WHERE user_id = 1 AND viewed_user_age BETWEEN 18 AND 22 AND viewed_user_sex = 1 GROUP BY viewed_user_age
执行完上面的explain语句,我们得到如下结果:

在Extra这一列中出现了三个Using,这3个Using代表了《导读》中的groupBy语句分别经历了3个执行阶段:
- Using where:通过搜索可能的
idx_user_viewed_user索引树定位到满足部分条件的viewed_user_id,然后,回表继续查找满足其他条件的记录 - Using temporary:使用临时表暂存待
groupBy分组及统计字段信息 - Using filesort:使用
sort_buffer对分组字段进行排序
这3个阶段中出现了一个名词:临时表。这个名词我在《MySQL分表时机:100w?300w?500w?都对也都不对!》一文中有讲到,这是MySQL连接线程可以独立访问和处理的内存区域,那么,这个临时表长什么样呢?
下面我就先讲讲这张MySQL的临时表,然后,结合上面提到的3个阶段,详细讲解《导读》中SQL的执行过程。
临时表
我们还是先看看《导读》中的这条包含groupBy语句的SQL,其中包含一个分组字段viewed_user_age和一个统计字段count(*),这两个字段是这条SQL中统计所需的部分,如果我们要做这样一个统计和分组,并把结果固化下来,肯定是需要一个内存或磁盘区域落下第一次统计的结果,然后,以这个结果做下一次的统计,因此,像这种存储中间结果,并以此结果做进一步处理的区域,MySQL叫它临时表。
刚刚提到既可以将中间结果落在内存,也可以将这个结果落在磁盘,因此,在MySQL中就出现了两种临时表:内存临时表和磁盘临时表。
内存临时表
什么是内存临时表?在早期数据量不是很大的时候,以存储分组及统计字段为例,那么,基本上内存就可以完全存放下分组及统计字段对应的所有值,这个存放大小由tmp_table_size参数决定。这时候,这个存放值的内存区域,MySQL就叫它内存临时表。
此时,或许你已经觉得MySQL将中间结果存放在内存临时表,性能已经有了保障,但是,在《MySQL分表时机:100w?300w?500w?都对也都不对!》中,我提到过内存频繁的存取会产生碎片,为此,MySQL设计了一套新的内存分配和释放机制,可以减少甚至避免临时表内存碎片,提升内存临时表的利用率。
此时,你可能会想,在《为什么我调大了sort_buffer_size,并发量一大,查询排序慢成狗?》一文中,我讲了用户态的内存分配器:ptmalloc和tcmalloc,无论是哪个分配器,它的作用就是避免用户进程频繁向Linux内核申请内存空间,造成CPU在用户态和内核态之间频繁切换,从而影响内存存取的效率。用它们就可以解决内存利用率的问题,为什么MySQL还要自己搞一套?
或许MySQL的作者觉得无论哪个内存分配器,它的实现都过于复杂,这些复杂性会影响MySQL对于内存处理的性能,因此,MySQL自身又实现了一套内存分配机制:MEM_ROOT。它的内存处理机制相对比较简单,内存临时表的分配就是采用这样一种方式。
下面,我就以《导读》中的SQL为例,详细讲解一下分组统计是如何使用MEM_ROOT内存分配和释放机制的?
MEM_ROOT
我们先看看MEM_ROOT的结构,MEM_ROOT设计比较简单,主要包含这几部分,如下图:
free:一个单向链表,链表中每一个单元叫block,block中存放的是空闲的内存区,每个block包含3个元素:
- left:
block中剩余的内存大小 - size:
block对应内存的大小 - next:指向下一个
block的指针
如上图,free所在的行就是一个free链表,链表中每个箭头相连的部分就是block,block中有left和 size,每个block之间的箭头就是next指针
used:一个单向链表,链表中每一个单元叫block,block中存放已使用的内存区,同样,每个block包含上面3 个元素
min_malloc:控制一个 block 剩余空间还有多少的时候从free链表移除,加入到used链表中
block_size:block对应内存的大小
block_num:MEM_ROOT 管理的block数量
first_block_usage:free链表中第一个block不满足申请空间大小的次数
pre_alloc:当释放整个MEM_ROOT的时候可以通过参数控制,选择保留pre_alloc指向的block
下面我就以《导读》中的分组统计SQL为例,看一下MEM_ROOT是如何分配内存的?
分配
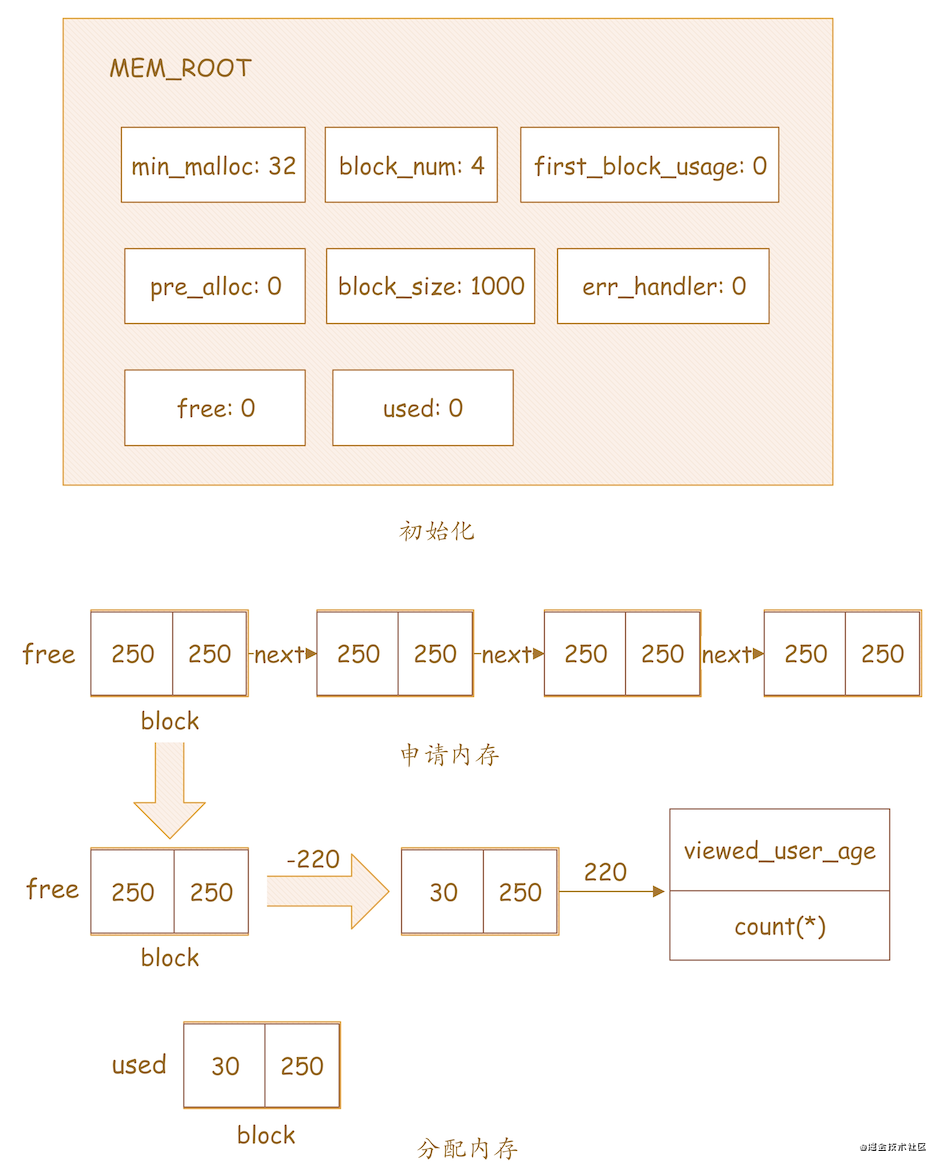
-
初始化
MEM_ROOT,见上图:min_malloc = 32block_num = 4first_block_usage = 0pre_alloc = 0block_size = 1000err_handler = 0free = 0used = 0 -
申请内存,见上图:
由于初始化
MEM_ROOT时,free = 0,说明free链表不存在,故向Linux内核申请4个大小为1000/4=250的block,构造一个free链表,如上图,链表中包含4个block,结合前面free链表结构的说明,每个block中size为250,left也为250 -
分配内存,见上图:
(1) 遍历
free链表,从free链表头部取出第一个block,如上图向下的箭头(2) 从取出的
block中划分220大小的内存区,如上图向右的箭头上面-220,block中的left从250变成30(3) 将划分的
220大小的内存区分配给SQL中的groupby字段viewed_user_age和统计字段count(*),用于后面的统计分组数据收集到该内存区(4) 由于第(2)步中,分配后的
block中的left变成30,30 < 32,即小于第(1)步中初始化的min_malloc,所以,结合上面min_malloc的含义的讲解,该block将插入used链表尾部,如上图底部,由于used链表在第(1)步初始化时为0,所以,该block插入used链表的尾部,即插入头部
释放
下面还是以《导读》中的分组统计为例,我们再来看一下MEM_ROOT是如何释放内存的?
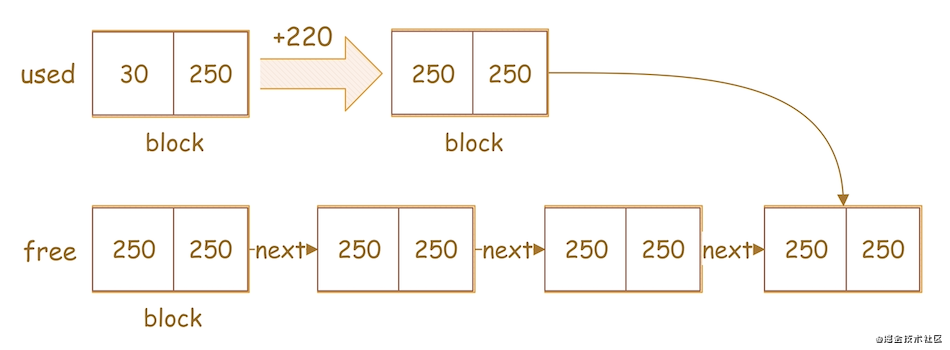 image-20210323233158459.png
image-20210323233158459.png
如上图,MEM_ROOT释放内存的过程如下:
- 遍历
used链表中,找到需要释放的block,如上图,block(30,250)为之前已分配给分组统计用的block - 将
block(30,250)中的left + 220,即30 + 220 = 250,释放该block已使用的220大小的内存区,得到释放后的block(250,250) - 将
block(250,250)插入free链表尾部,如上图曲线箭头部分
通过MEM_ROOT内存分配和释放的讲解,我们发现MEM_ROOT的内存管理方式是在每个Block上连续分配,内部碎片基本在每个Block的尾部,由min_malloc成员变量控制,但是min_malloc的值是在代码中写死的,有点不够灵活。所以,对一个block来说,当left小于min_malloc,从其申请的内存越大,那么block中的left值越小,那么,该block的内存利用率越高,碎片越少,反之,碎片越多。这个写死是MySQL的内存分配的一个缺陷。
磁盘临时表
当分组及统计字段对应的所有值大小超过tmp_table_size决定的值,那么,MySQL将使用磁盘来存储这些值。这个存放值的磁盘区域,MySQL叫它磁盘临时表。
我们都知道磁盘存取的性能一定比内存存取的性能差很多,因为会产生磁盘IO,所以,一旦分组及统计字段不得不写入磁盘,那性能相对是很差的,所以,我们尽量调大参数tmp_table_size,使得组及统计字段可以在内存临时表中处理。
执行过程
无论是使用内存临时表,还是磁盘临时表,临时表对组及统计字段的处理的方式都是一样的。《导读》中我提到想要优化《导读》中的那条SQL,就需要知道SQL执行的原理,所以,下面我就结合上面讲解的临时表的概念,详细讲讲这条SQL的执行过程,见下图:
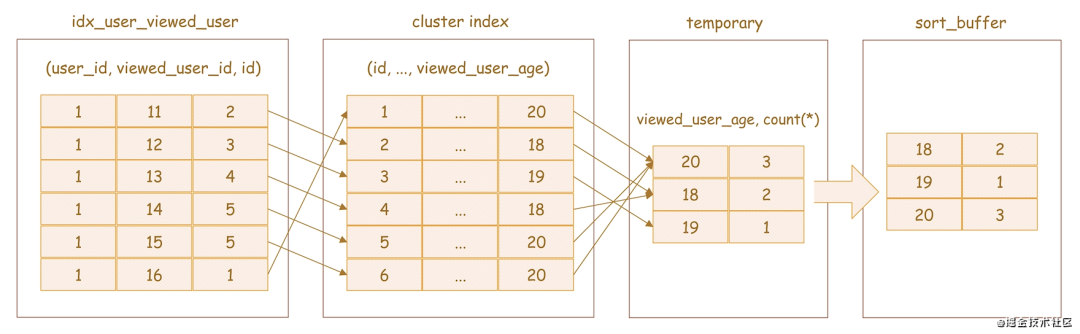
-
创建临时表
temporary,表里有两个字段viewed_user_age和count(*),主键是viewed_user_age,如上图,倒数第二个框temporary表示临时表,框中包含两个字段viewed_user_age和count(*),框内就是这两个字段对应的值,其中viewed_user_age就是这张临时表的主键 -
扫描表辅助索引树
idx_user_viewed_user,依次取出叶子节点上的id值,即从索引树叶子节点中取到表的主键id。如上图中的idx_user_viewed_user框就是索引树,框右侧的箭头表示取到表的主键id -
根据主键id到聚簇索引
cluster_index的叶子节点中查找记录,即扫描cluster_index叶子节点:(1) 得到一条记录,然后取到记录中的
viewed_user_age字段值。如上图,cluster_index框,框中最右边的一列就是viewed_user_age字段的值(2) 如果临时表中没有主键为
viewed_user_age的行,就插入一条记录 (viewed_user_age, 1)。如上图的temporary框,其左侧箭头表示将cluster_index框中的viewed_user_age字段值写入temporary临时表(3) 如果临时表中有主键为
viewed_user_age的行,就将viewed_user_age这一行的count(*)值加 1。如上图的temporary框 -
遍历完成后,再根据字段
viewed_user_age在sort_buffer中做排序,得到结果集返回给客户端。如上图中的最右边的箭头,表示将temporary框中的viewed_user_age和count(*)的值写入sort_buffer,然后,在sort_buffer中按viewed_user_age字段进行排序
通过《导读》中的SQL的执行过程的讲解,我们发现该过程经历了4个部分:idx_user_viewed_user、cluster_index、temporary和sort_buffer,对比上面explain的结果,其中前2个就对应结果中的Using where,temporary对应的是Using temporary,sort_buffer对应的是Using filesort。
优化方案
此时,我们有什么办法优化这条SQL呢?
既然这条SQL执行需要经历4个部分,那么,我们可不可以去掉最后两部分呢,即去掉temporary和sort_buffer?
答案是可以的,我们只要给SQL中的表t_user_view添加如下索引:
ALTER TABLE `t_user_view` ADD INDEX `idx_user_age_sex` (`user_id`, `viewed_user_age`, `viewed_user_sex`);
你可以自己尝试一下哦!用explain康康有什么改变!
小结
本章围绕《导读》中的分组统计SQL,通过explain分析SQL的执行阶段,结合临时表的结构,进一步剖析了SQL的详细执行过程,最后,引出优化方案:新增索引,避免临时表对分组字段的统计,及sort_buffer对分组和统计字段排序。
当然,如果实在无法避免使用临时表,那么,尽量调大tmp_table_size,避免使用磁盘临时表统计分组字段。
思考题
为什么新增了索引idx_user_age_sex可以避免临时表对分组字段的统计,及sort_buffer对分组和统计字段排序?
提示:结合索引查找的原理。
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2021最新版)
2.别在再满屏的 if/ else 了,试试策略模式,真香!!
3.卧槽!Java 中的 xx ≠ null 是什么新语法?
4.Spring Boot 2.5 重磅发布,黑暗模式太炸了!
觉得不错,别忘了随手点赞+转发哦!