前言
以淘宝网为例,简单了解一下大型电商的服务端架构是怎样的。如图所示
最上面的就是安全体系系统,中间的就是业务运营系统,包含各个不同的业务服务,下面是一些共享服务,然后还有一些中间件,其中 ECS 就是云服务器,MQS 是队列服务,OCS 是缓存等等,右侧是一些支撑体系服务。

除图中所示之外还包含一些我们看不到的,比如高可用的体现。淘宝目前已经实现多机房容灾和异地机房单元化部署,为淘宝的业务也提供了稳定、高效和易于维护的基础架构支撑。
这是一个含金量非常高的架构,也是一个非常复杂而庞大的架构,当然这个架构不是一天两天演进成这样的,也不是一开始就设计并开发成这样的,对于初创公司而言,很难在初期就预估到未来流量千倍、万倍的网站架构会是怎样的状况,同时如果初期就设计成千万级并发的流量架构,也很难去支撑这个成本。
因此一个大型服务系统,都是从小一步一步走过来的,在每个阶段找到对应该阶段网站架构所面临的问题,然后不断解决这些问题,在这个过程中,整个架构会一直演进,同时内含的代码也就会演进,大到架构、小到代码都是在不断演进和优化的。所以说高大上的项目技术架构和开发设计实现不是一蹴而就的,这是所谓的万丈高楼平地起。

单机架构
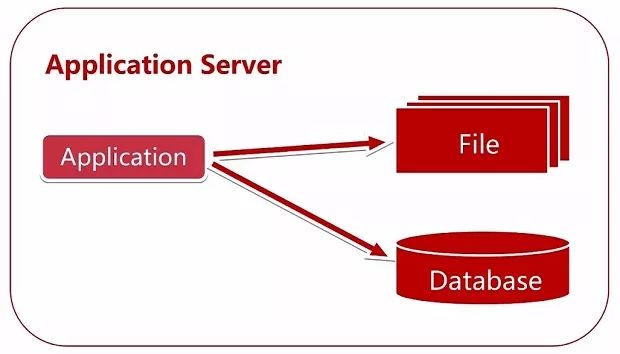
从一个小网站说起,一般来说初始一台服务器就够了,文件服务器、数据库以及应用都部署在一台机器上。也就是俗称的 allinone 架构。
多机部署
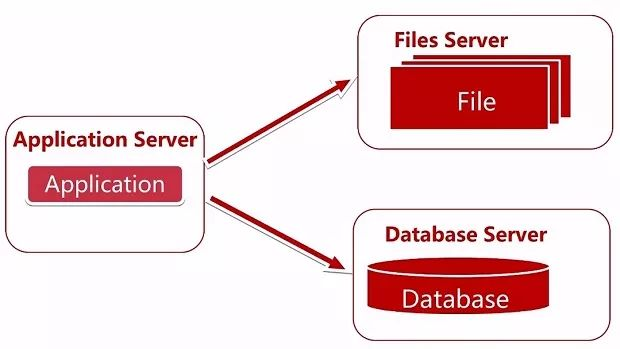
随着网站用户逐渐增多,访问量越来越大,硬盘、cpu、内存等开始吃紧,一台服务器难以支撑。看一下演进过程,我们将数据服务和应用服务进行分离,给应用服务器配置更好的 cpu、内存等等,而给数据服务器配置更好、更快的大的硬盘,如图所示用了三台服务器进行部署,能提高一定的性能和可用性。
分布式缓存
随着访问的并发越来越高,为了降低接口的访问时间提高服务性能,继续对架构进行演进。
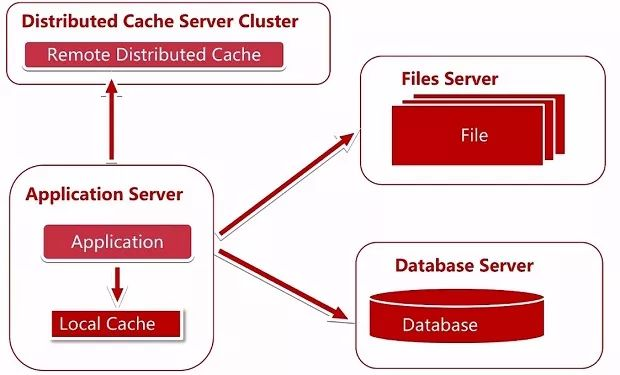
我们发现有很多业务数据不需要每次都从数据库中获取,于是我们使用了缓存,因为 80% 的业务访问都集中在 20% 的数据上 (二八原则),如果能将这部分数据缓存下来,性能就能提高很多,缓存又分两种,一种是 Application 中的本地缓存,还有远程缓存,远程缓存又分为远程的单机式缓存和分布式缓存 (图所示的是分布式缓存集群)。
我们需要思考几点,具有哪种业务特点的数据使用缓存,具有哪种业务特点的数据使用本地缓存,具有哪种业务特点的数据使用远程缓存。分布式缓存在扩容时会遇上什么问题,如何解决,分布式缓存的算法都有哪几种,都有什么优缺点。这些问题都是我们在使用这个架构时需要思考并解决的问题。
关注微信公众号:Java技术栈,在后台回复:架构,可以获取我整理的 N 篇最新架构干货。
服务器集群
这个时候随着访问的 qps 不断提高,假设我们使用的 Application Server 是 tomcat,那么 tomcat 服务器的处理能力就会成为一个瓶颈,虽然我们也可以通过购买更强大的硬件但总会有上限,并且这个成本到后期是呈指数级的增长。
这时候就可以对服务器做一个集群 (cluster),然后添加负载均衡调度器 (LoadBalancer),服务器集群后我们就可以横向扩展我们的服务器了,解决了服务器处理能力的瓶颈。
此时我们又需要思考几个问题, 负载均衡的调度策略都有哪些,各有什么优缺点,各适合什么场景,比如轮询、权重、地址散列,地址散列又分为原 IP 地址散列、目标 IP 地址散列、最小连接、加权最小连接等等。
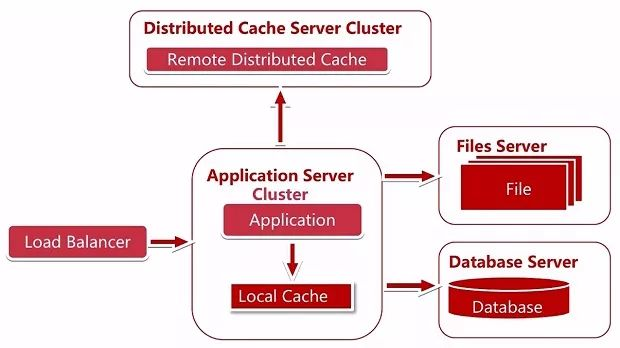
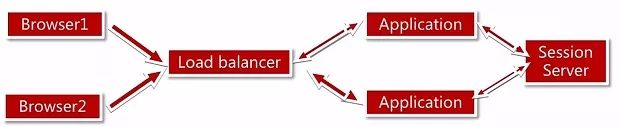
服务器集群后,假设我们登陆了 A 服务器,session 信息存放在 A 服务器上了,如果我们的负载均衡策略是轮询或者最小连接等,下次是有可能访问到 B 服务器,这时候存储在 A 服务器上的 session 信息我们在 B 服务器是读取不到的,所以我们需要解决 session 管理的问题。
Session 共享解决方案
session sticky
我们使用 session sticky这种方式来解决这个问题,它的处理规则是对于同一个连接中的数据包,负载均衡会将其进行 NAT 转换后,转发至后端固定的服务器进行处理,这种方案解决了 session 共享的问题。
如图所示客户端 1 通过负载均衡会固定转发到服务器 1 中。缺点是第一假设有一台服务器重启了,那么该服务器的 session 将全部消失,第二是我们的负载均衡服务器成了一种有状态的服务器,要实现容灾会有麻烦。

session 复制
session 复制,即当 browser1 经过负载均衡服务器把 session 存到 application1 中,会同时把 session 复制到 application2 中,所以多台服务器都保存着相同的 session 信息。
缺点是应用服务器的带宽问题,服务器之间要不断同步 session 信息,当大量用户在线时,服务器占用内存会过多,不适合大规则集群,适合机器不多情况。

基于 cookie
基于 cookie,也就是说我们每次都用携带 session 信息的 cookie 去访问应用服务器。缺点是 cookie 的长度是有限制的,cookie 保存在浏览器上安全性也是一个问题。

session 服务器
把 session 做成了一个 session 服务器,比如可以使用 redis 实现。这样每个用户访问到应用服务器,其 session 信息最终都存到 session server 中,应用服务器也是从 session server 中去获取 session。
要考虑以下几个问题,在当前架构中 session server 是一个单点的,如何解决单点,保证它的可用性,当然也可以将 session server 做成一个集群,这种方式适用于 session 数量及 web 服务器数量大的情况,同时改成这种架构后,在写应用时,也要调整存储 session 的业务逻辑。
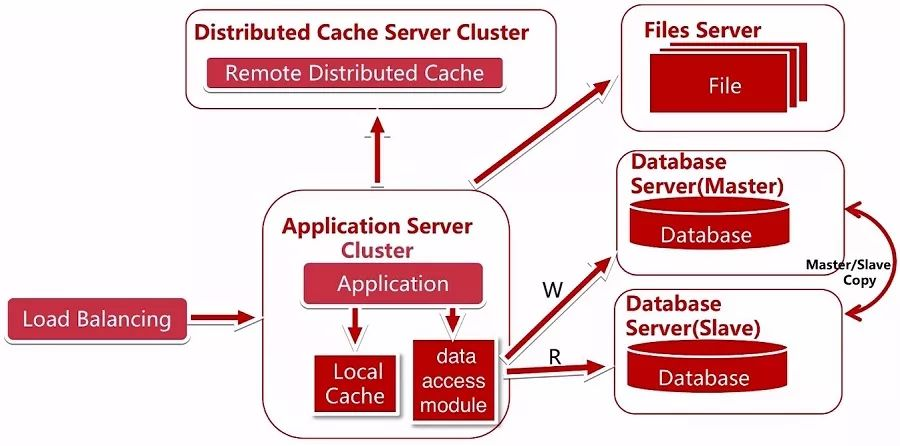
数据库读写分离
在解决了服务器横向扩展之后,继续看数据库,数据库的读与写操作都需要经过数据库,当用户量达到一定量时,数据库性能又成为了一个瓶颈,我们继续演进。
我们可以使用数据库的读写分离,同时应用要接入多数据源。通过统一的数据访问模型进行访问。数据库的读写分离是将所有的写操作引入到主库中 (master),将读操作引入到从库中 (slave),此时应用程序也要做出相应的变化,我们实现了一个数据访问模块 (data accessmodule),使上层写代码的人不知道读写分离的存在,这样多数据源的读写对业务代码就没有侵入,这就是代码层面的演变。
如何支持多数据源,如何封装对业务没有侵入,如何使用目前业务使用的 ORM 框架完成主从的读写分离,是否需要更换 ORM,各有什么优缺点,如何取舍都是当前这个架构需要考虑的问题。
当访问量过大时候,也就是说数据库的 IO 非常大,我们的数据库读写分离又会遇到以下问题?
例如主库和从库复制有没有延迟,如果我们将主库和从库分机房部署的话,跨机房传输同步数据更是一个问题。另外应用对数据源的路由问题,这些也是需要思考和解决的点。
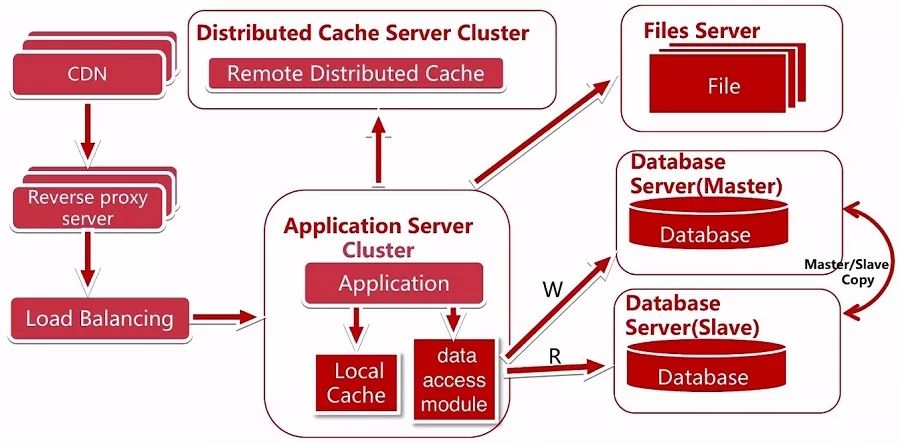
CDN 加速与反向代理
我们继续增加了 CDN和反向代理服务器 (Reverseproxy server),使用 CDN可以很好的解决不同地区访问速度问题,反向代理则在服务器机房中可以缓存用户的资源。
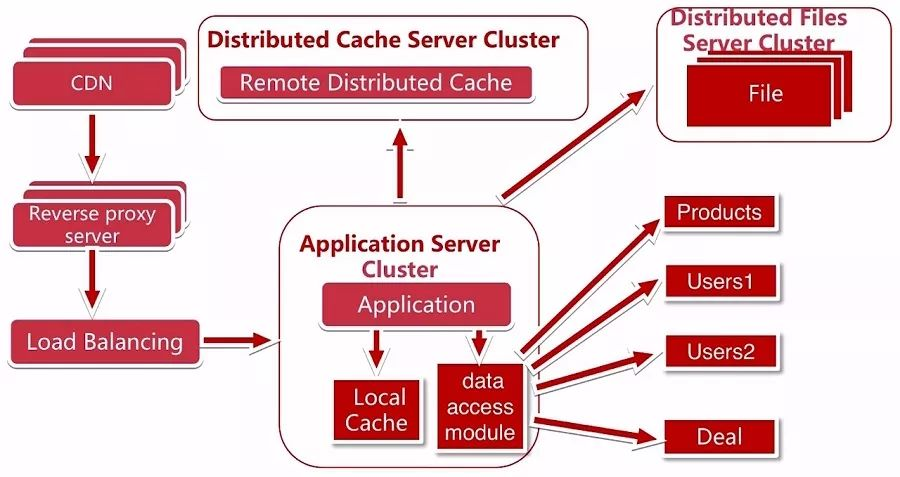
分布式文件服务器
这个时候我们的文件服务器又出现了瓶颈,我们将文件服务器改成了分布式文件服务器集群,在使用分布式文件系统时,需要考虑几个问题,如何不影响部署在线上的应用访问,是否需要业务部门帮忙清洗数据,是否需要备份服务器,是否需要重新做域名解析等等。
数据库分库分表
这个时候我们的数据库又出现了瓶颈,我们选择专库专用的形式,进行数据的垂直拆分,相关的业务独用自己的一个库,我们解决了写数据并发量大的问题。
当我们把这些表分成不同的库,又会带来一些新的问题。例如跨业务和跨库的事务,可以使用分布式事务,或者去掉事务,或者不追求强事务。
随着访问量过大,数据量过大,某个业务的数据库数据量和更新量已经达到了单个数据库的瓶颈了,这个时候就需要进行数据库的水平拆分,例如把 user 拆分成了 user1 和 user2,就是将同一个表的数据拆分到两个数据库当中,这个时候我们解决了单数据库的瓶颈。
水平拆分时候又要注意哪些点,都有哪几种水平拆分的方式。进行了水平拆分后,又会遇到几个问题,第一 sql 路由的问题,假设有一个用户,我们如何知道这个用户信息是存在了 user1 还是 user2 数据库中,由于分库了,我们的主键策略也会有所不同,同时会面临分页的问题,假设我们要查询某月份已经下单的用户明细,而这些用户又分布在 user1 和 user2 库中,我们后台运营管理系统对它进行展示的时候还要进行分页。这些都是我们在使用这个架构时需要解决的问题。
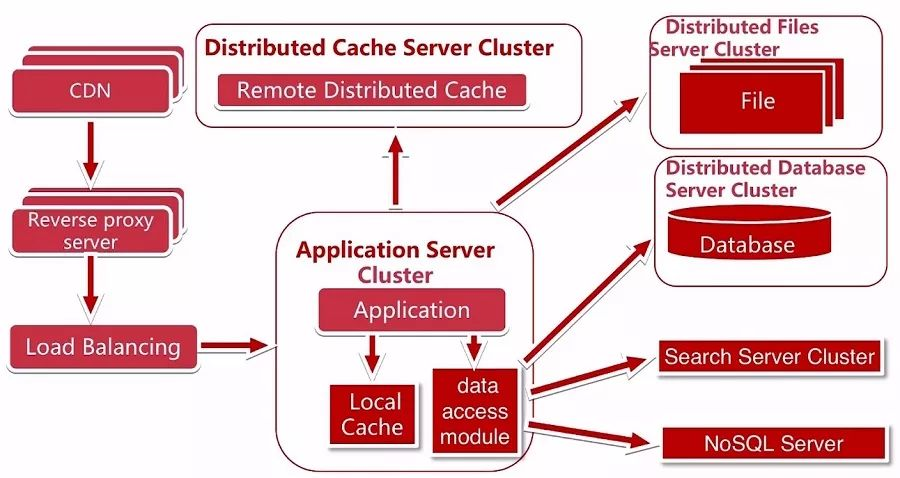
搜索引擎与 NoSQL
在网站发布并进行了大规模的推广后,导致我们应用服务器的搜索量又飙升,我们把应用服务器的搜索功能单独抽取出来做了一个搜索引擎,同时部分场景可以使用 NoSQL来提高性能。同时我们开发一个数据统一的访问模块,同时连着数据库集群、搜索引擎和 NoSQL,解决上层应用开发的数据源问题。
关注微信公众号:Java技术栈,在后台回复:架构,可以获取我整理的 N 篇最新架构干货。
后序
这里只是简单举例,并没有依据什么实际的业务场景。事实上各个服务的架构是要根据实际的业务特点进行优化和演进的,所以这个过程也不是完全相同的。当然这个架构也不是最终形态,还存在很多要提升的地方。
例如负载均衡服务器目前是一个单点的,如果负载均衡服务器访问不了,那么后续的包括服务器集群等也就无法访问了。所以可以将负载均衡服务器做成集群,然后做一些主从的双机热备,同时做一个自动切换的解决方案。
在整个架构的演进过程中,其实还包含更多需要关注的内容,比如安全性、数据分析、监控、反作弊......
针对一些特定的场景例如交易、充值、流计算等使用消息队列、任务调度......
整个架构继续发展下去,做成 SOA 架构、服务化 (微服务)、多机房......
最后,我想说高大上的项目技术架构和开发设计实现绝不是一僦而就的。
推荐去我的博客阅读更多:
2.Spring MVC、Spring Boot、Spring Cloud 系列教程
3.Maven、Git、Eclipse、Intellij IDEA 系列工具教程
生活很美好,明天见~