一、数据库拆分
1. 为什么要做数据库拆分
单机数据库存在的问题?
从容量、性能、可用性和运维成本上难以满足海量数据的场景。
- 性能方面,数据量超过一定阈值,B+树索引慎独增加导致磁盘访问的IO次数增加,进而导致查询性能的下降。
- 容量方面,单机能存储的数据量有限
- 可用性方面,大量的查询落到单一的数据库节点或者简单的主从架构上,数据库很难承担。
- 运维方面,数据量达到一定阈值,主从同步延迟高、增加字段索引、备份这些都会很慢,影响业务系统。
主从结构解决了高可用、读扩展。但是单机容量不变,单机写性能无法解决。
为了解决这些问题,我们需要采用分库分表,将数据库拆分开。降低单个节点的写压力,提升整个系统的数据容量上限。
扩展立体方
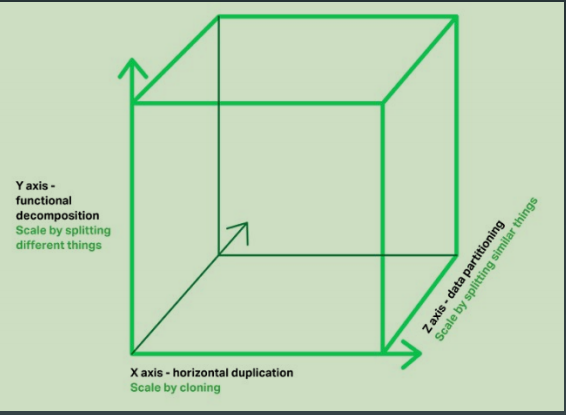
- X轴:通过clone整个系统复制,集群
- Y轴:通过解耦不同功能复制,业务拆分
- Z轴:通过拆分不同数据扩展,数据分片
2. 垂直拆分
垂直拆分,按照业务纬度分库分表。
垂直拆库
将一个数据库,拆分为多个提供不同业务数据处理能力的数据库。如:将一个电商的单独库拆为用户库、订单库、商品库。
垂直拆表
如果单表数据量过大,还需要对单表进行拆分。如:一个200列的订单主表,拆分为十几个子表:订单表、订单详情表、订单收件信息表等。
垂直拆分的优缺点:
优点:
- 单库(单表)变小,便于管理
- 对性能和容量有提升
- 拆分后,系统和数据复杂度降低
- 可以作为微服务改造的基础
缺点:
- 库变多,管理变复杂
- 对业务系统有较强的侵入性
- 改造过程复杂,容易出故障
- 拆分到一定程度就无法继续拆分
3. 水平拆分
水平拆分就是直接对数据进行分片,有分库和分表两个具体方式。不改变数据本身的结构,只是降低单个节点数据量。这样对业务系统本身的代码来说不需要做特别大的改动,甚至可以基于一些中间件做到透明。
比如把一个10亿条记录的订单的单库单表。按用户id除以32取模,将单库拆分为32个库;再按订单id除以32取模,每个库再拆为32个表。这样就是32*32=1024个表,单个表数据量就只有不到百万条了。
水平分库分表
一般来说我们我们的数据都是有创建时间的,可以按时间拆分,按照年、季度、月、天都可以。
或者根据用户拆分、甚至可以根据一些自定义的复杂的逻辑来拆分。
为什么有时候不建议分表,只建议分库?
因为分表不能解决容量问题,如果瓶颈在IO(磁盘IO、网络IO)上,分表也解决不了,因为分表还是在同一个机器,而分库可以在两个机器上。
分库还是分表,如何选择?
一般情况下,如果数据本身读写压力较大,磁盘IO已经成为瓶颈,那么分库比分表要好。而使用不同的库,可以并行提升整个集群的并行数据处理能力。
相反的情况下,可以尽量考虑分表,降低单表的数据量。
水平分库分表的优缺点:
优点:
- 解决容量问题
- 比垂直拆分对系统影响小
- 部分提升性能和稳定性
缺点:
- 集群规模大,管理复杂
- 复杂SQL支持问题
- 数据迁移问题
- 一致性问题
4. 数据的分类管理
数据的分类管理是指通过对数据进行分类提升数据管理能力。
随着对业务系统、对数据的分析了解发现,很多数据对质量的要求是不一样的。
如订单数据,肯定一致性要求最高,不能丢失。而一些日志数据,中间数据,则没有那么高的一致性。丢了就丢了。
另外,同一张表里的订单数据也可以采用不同策略,无效订单比较多,我们可以定期转移或清除。(一些交易系统里80%以上的是下单后取消的无意义订单,所以可以清理它)
如果没有无效订单,也可以考虑:
- 最近一周下单但是未支付的订单,被查询和支付的可能性较大。而再以前一点的,可以直接取消掉。
- 最近3个月下单的数据,被在线重复查询和系统统计的可能性最大。
- 3个月以前-3年以内的数据,查询的可能性小,可以不提供在线查询
- 3年以上的数据,可以直接不提供任何方式的查询。
这样的话,我们就可以根据分类采用一定的手段去优化系统:
- 定义一周内下单但未支付的数据为热数据,同时放到数据库和内存
- 定义3个月内的数据为温数据,放到数据库,提供正常的查询操作
- 定义3个月到3年的数据为冷数据,从数据库删除,归档到一些便宜的磁盘,用压缩的方式(比如MySQL的tokuDB引擎)存储,用户需要查询的话提工单来查询
- 定义3年以上的数据为冰数据,备份到磁带之类的介质上,不提供任何查询操作。
5. 数据库中间件
数据库中间件的技术演进
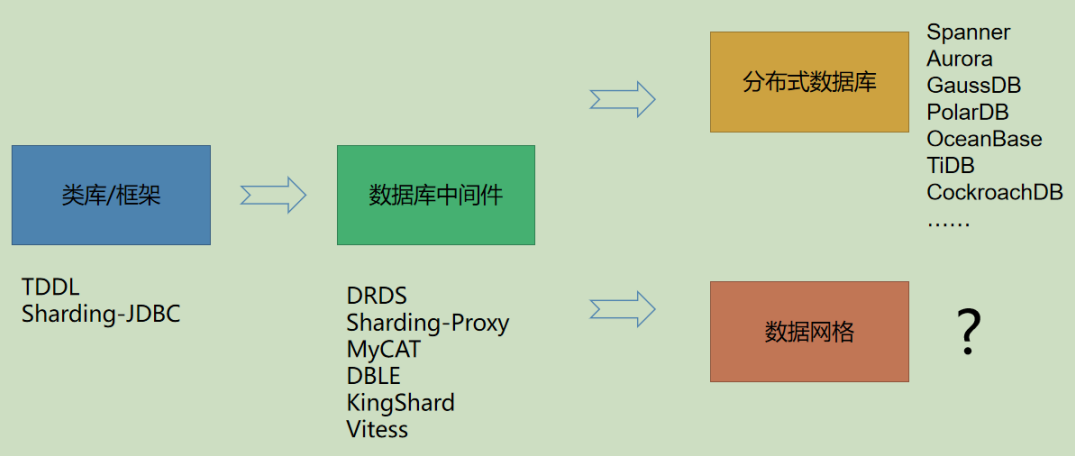
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由JDBC、Proxy和Sidecar(规划中)这3款相互独立,又能混合部署配合使用的产品组成。它们均提供数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构、云原生等各种多样化的应用场景。
ShardingSphere-JDBC
框架ShardingSphere-JDBC,可以直接在业务代码使用,支持常见的数据库和JDBC。只适用于Java语言。
使用实例:
- 读写分离:https://github.com/mmcLine/sharding/
- 分库分表:https://gitee.com/mmcLine/shardingjdbc-database-example
二、数据迁移
方案一:全量
- 业务系统停机
- 数据库迁移,校验一致性
- 业务系统升级,接入新数据库
如果新数据库结构一样,可以dump后全量导入。如果是异构的话,需要用程序处理。
方案二:全量+增量
依赖于数据本身的时间戳
- 先同步数据到最近的某个时间戳(如前一天)
- 然后再发布升级时停机维护
- 再同步最后一段时间的变化数据
- 最后升级业务系统,接入新数据库。
方案三:binlog+全量+增量
- 通过主库或从库的binlog来解析和重新构造数据,实现复制。
- 一般需要中间件工具的支持。
可以实现多线程,断点续传,全量或增量的数据同步。
继而可以做到:
- 实现自定义复杂异构数据结构
- 实现自动扩容和缩容,比如分库分表到单库单表、单库单表到分库分表、分4个库到分8个库等等。
下面介绍一个迁移工具:
ShardingSphere-scaling