从单机到集群
随着数据量增加,读写并发的增加,系统可用性要求的提升,单机MySQL存在着一些问题:
- 容量有限,难以扩容
- 读写压力、QPS过大,特别是分析类需求会影响到业务事务
- 可用性不足,单点故障

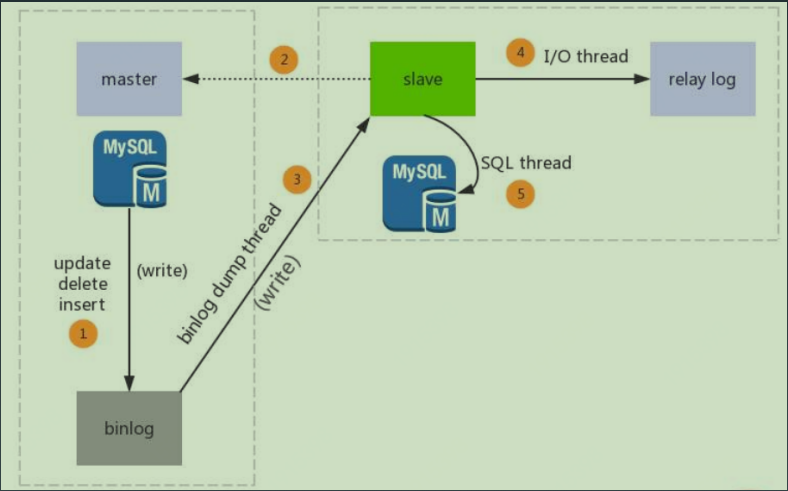
1 主从复制
核心流程是:
- 主库写binlog
- 从库拉取binlog写入relay log
binlog格式
- Row
这个模式存的是哪条记录被修改,修改成什么样.缺点是日志内容大。
- Statement
存的是sql语句,日志量少。缺点是一些函数、触发器同步可能有障碍。
- Mixed
两种模式的结合,根据执行的sql语句来区分对待记录的日志形式。
查看binlog命令,进入mysql的bin目录下执行。
mysqlbinlog --no-defaults ../data/binlog.000116
修改binlog模式
- 先查看binlog格式
SHOW VARIABLES LIKE "%binlog_format%";
- 在线修改
set global binlog_format='MIXED';
- 使用配置修改
配置文件my.ini中加入
binlog_format="MIXED" #开启MIXED模式
修改后重启mysql服务
主从复制方案
- 异步复制
传统的主从复制,网络或机器故障,会导致数据不一致

- 半同步复制
保证Source和Replica最终一致性
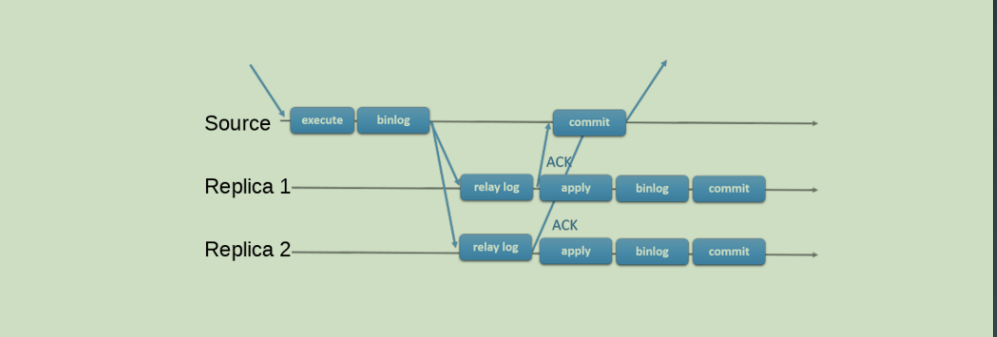
- 组复制 (Mysql Group Replication)
简称MGR,基于分布式协议Paxos实现,保证数据一致性

主从复制实战
异步复制
- 准备两个mysql实例
- 修改master的那个mysql实例的my.cnf配置文件,增加如下内容,并重启mysql
server-id=1
log-bin=mysql-bin
- 登入master的mysql,创建一个同步数据的用户
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
- 修改slave的那个mysql实例的my.cnf配置文件,增加如下内容,并重启mysql
server-id=2
log-bin=mysql-bin
- 登入master的mysql,执行
show master status;
记录下File和Position

- 登入slave的mysql,配置从库
change master to master_host='192.168.161.21', master_user='slave', master_password='123456', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos= 837, master_connect_retry=30;
master_log_file和master_log_pos就是上面记录下的File和Position。
执行完后继续执行下面的命令,开启主从复制
start slave
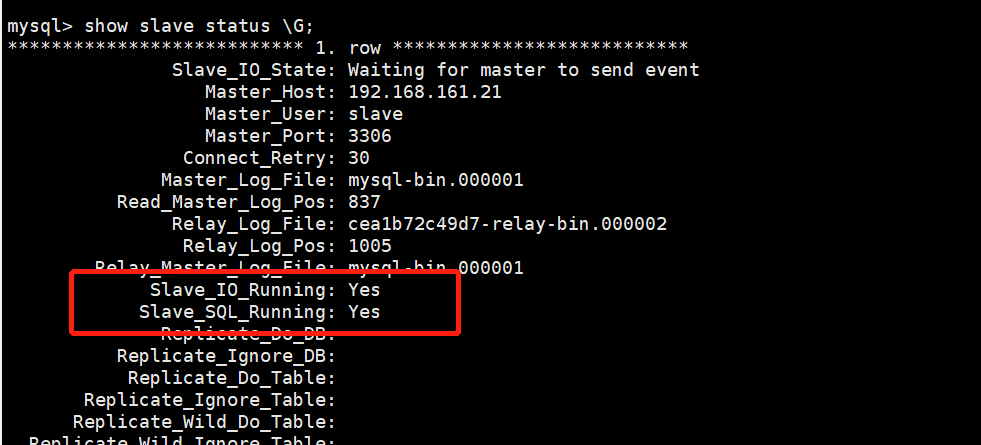
- 查看主从复制是否生效
show slave status G;
两个都是YES,说明成功
- 测试,在主库上新建数据库,新建表,插入数据,然后查看从库的数据情况即可。
主从复制的局限性
- 主从延迟问题
- 应用端需要配合读写分离框架
- 不解决高可用的问题
2 读写分离
方案1:
基于Spring提供的路由数据源AbstractRoutingDataSource以及AOP
缺点:
- 代码侵入性强
- 同一个service中有“写完读”数据不一致问题
具体实现:https://www.cnblogs.com/cjsblog/p/9712457.html
方案2:
ShardingSphere-jdbc 的 Master-Slave 功能
缺点:
- 对业务系统还是有侵入
- 对已存在的旧系统改造不友好
具体操作:https://www.cnblogs.com/javammc/p/12470838.html
方案3:
使用MyCat/ShardingSphere-Proxy的Master-Slave功能
部署中间件,规则配置在中间件中,业务系统无侵入。
3 MySQL高可用
什么是高可用?
高可用代表着更少的不可服务的时间。一般互联网公司要求达到4个9,即一年不能服务的时间不超过52.6分钟
99.9 = 8760 * 0.1% = 8760 * 0.001 = 8.76小时
99.99 = 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟
数据库要实现高可用,需要做到
- 读写分离,提高读的处理能力
- 故障转移,灾难恢复
常见的一些策略有:
- 多个实例不在一个主机上
- 跨机房部署
- 两地三中心容灾高可用方案
3.1 MySQL高可用方案
方案1:主从手动切换
如果主节点挂掉了,将某个从改为主。然后配置其他从节点。应用侧需要修改数据源配置。
缺点:
- 可能数据不一致
- 需要人工操作
- 代码和配置的侵入性
方案2:主从手动切换2
用LVS+Keepalived实现多个节点的探活+请求路由
,配置VIP或DNS实现应用侧配置不变更
缺点:
- 也需要手工操作
- 大量的配置和脚本定义
方案3:MHA
MHA(Master High Availability)目前在 MySQL 高可用方面是一个相对成熟的解决方案,它由日本 DeNA 公司的 youshimaton(现就职于 Facebook 公司)开发,是一套优秀的作为 MySQL 高可用性环境下故障切换和主从提升的高可用软件。
基于Perl语言开发,一般能在30S内实现主从切换。切换时通过SSh复制主节点的日志。
缺点:
- 需要配置SSH信息
- 至少3台机器
方案4:MGR
Mysql Group Replication(MGR)
MGR的特点:
- 高一致性:基于分布式协议Paxos实现组复制,保证数据一致性
- 高容错性:自动检测机制,只要不是大多数节点宕机都可以继续工作
- 高扩展性:节点的的增加与移除会自动更新组成员信息。新节点加入后,自动从其他节点通过增量数据,直到与其他节点数据一致
- 高灵活性:提高单主模式和多主模式,单主模式在主库宕机后自动选主,多主模式支持多节点写入。
如果主节点挂掉,将自动选择某个从改为主。无需人工干预,基于组复制,保证数据一致性。
缺点:
- 外部获得状态变更需要读取数据库
- 外部需要使用LVS/VIP配置
方案5:Mysql Cluster
MySQL InnoDB Cluster是一个高可用的框架,它由下面这几个组件构成:
- MySQL Group Replication :提供DB的扩展、自动故障转移
- MySQL Router:轻量级中间件,提供应用程序负载均衡和应用连接的故障转移
- MySQL Shell:新的MySQL客户端,多种接口模式
方案6:orchestrator
一款MySQL高可用和复制拓扑管理工具,支持自动故障转移和手动主从切换等。通过Web界面操作可以更改Mysql实例的复制关系和部分配置信息,同时提供命令行和API接口,方便运维管理。