一:启动流程
[hadoop@hadoop001 spark-2.4.0-bin-2.6.0-cdh5.7.0]$ cd sbin
[hadoop@hadoop001 sbin]$ ./start-thriftserver.sh
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /home/hadoop/app/spark-2.4.0-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop001.out
这是启动日志
[hadoop@hadoop001 sbin]$ cd ../
[hadoop@hadoop001 spark-2.4.0-bin-2.6.0-cdh5.7.0]$ cd bin
去hive启动
[hadoop@hadoop001 hive-1.1.0-cdh5.7.0]$ cd conf
[hadoop@hadoop001 conf]$ tail -200f /home/hadoop/app/spark-2.4.0-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop001.out
去saprk
[hadoop@hadoop001 spark-2.4.0-bin-2.6.0-cdh5.7.0]$ cd bin
[hadoop@hadoop001 bin]$ ./beeline -u jdbc:hive2://localhost:10000 -n hadoop
Connecting to jdbc:hive2://localhost:10000
18/12/28 16:17:52 INFO Utils: Supplied authorities: localhost:10000
18/12/28 16:17:52 INFO Utils: Resolved authority: localhost:10000
18/12/28 16:17:52 INFO HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://localhost:10000
Connected to: Spark SQL (version 2.4.0)
这里注意,有很多,一定要到相应的目录下面去启动
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1.spark2 by Apache Hive
0: jdbc:hive2://localhost:10000>
端口号是:10000默认的
二:注意事项
1,前期的配置一定要没有问题
2,注意一下hive和spark的切换
3,这里注意,有很多,一定要到相应的目录下面去启动
4,端口号是:10000默认的,如果不是默认的要自己查询
5,JDBC 一定要配置server使用
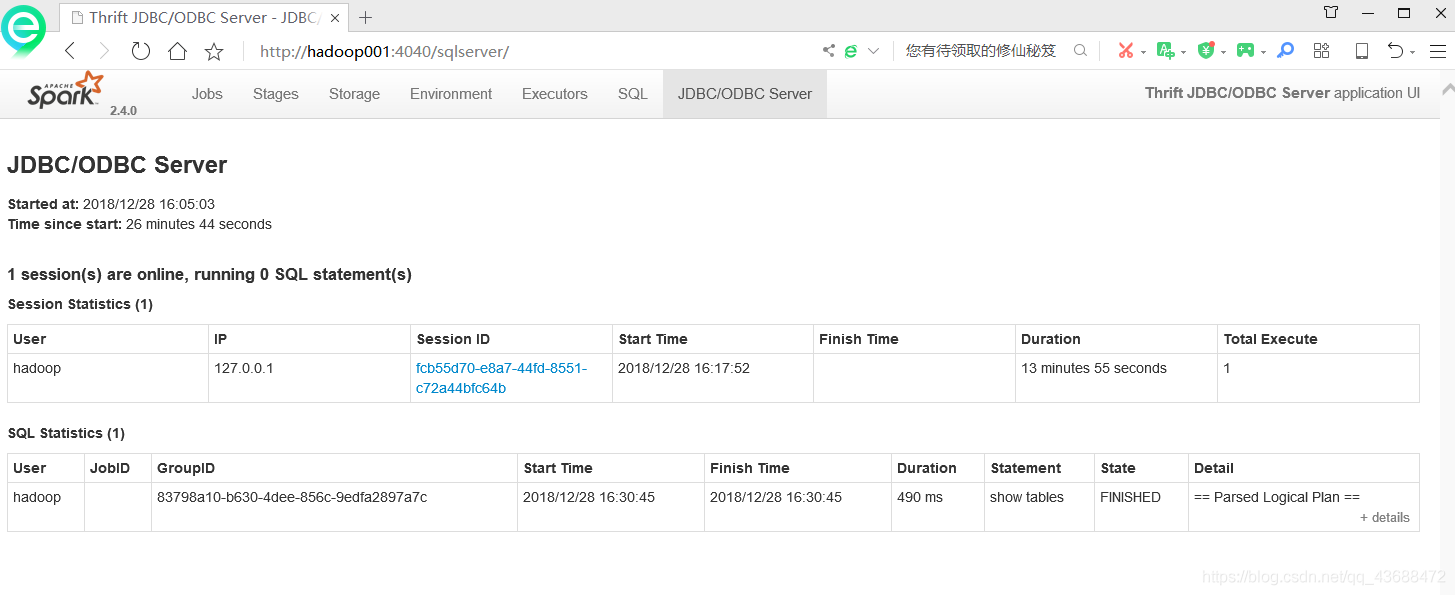
三:运行
————————————————
版权声明:本文为CSDN博主「墨卿风竹」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43688472/article/details/85330157