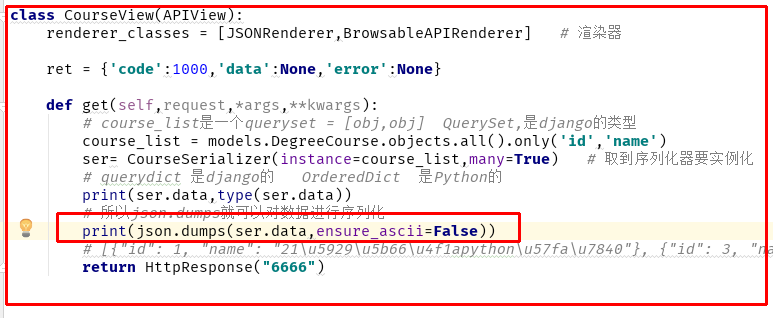
# 获取课程的视图 from django.shortcuts import HttpResponse from rest_framework.views import APIView from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer from api import models from api.serializers.course import CourseSerializer # 导入序列化插件 import json class CourseView(APIView): renderer_classes = [JSONRenderer,BrowsableAPIRenderer] # 渲染器 ret = {'code':1000,'data':None,'error':None} def get(self,request,*args,**kwargs): # course_list是一个queryset = [obj,obj] QuerySet,是django的类型 course_list = models.DegreeCourse.objects.all().only('id','name') ser= CourseSerializer(instance=course_list,many=True) # 取到序列化器要实例化 # querydict 是django的 OrderedDict 是Python的 print(ser.data,type(ser.data)) # 所以json.dumps就可以对数据进行序列化 print(json.dumps(ser.data)) # [{"id": 1, "name": "21u5929u5b66u4f1apythonu57fau7840"}, {"id": 3, "name": "javau9879u76ee"}, {"id": 2, "name": "pythonu67b6u6784"}] return HttpResponse("6666")
当打印数据出现乱码,可添加ensure_ascii=False
注意点
querydict 是django的 OrderedDict 是Python的
from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer # 渲染器 + BrowsableAPIRenderer 是用框架提供的模板
分页
源码
关于ser = CourseDetailSerializer(instance=obj,many=False)的many=false执行了什么内容?
从ModelSerializer 找到 BaseSerializer class BaseSerializer(Field): def __init__(self, instance=None, data=empty, **kwargs): self.instance = instance if data is not empty: self.initial_data = data self.partial = kwargs.pop('partial', False) self._context = kwargs.pop('context', {}) kwargs.pop('many', None) super(BaseSerializer, self).__init__(**kwargs) def __new__(cls, *args, **kwargs): # We override this method in order to automagically create # `ListSerializer` classes instead when `many=True` is set. # 如果没有mang即为False if kwargs.pop('many', False): return cls.many_init(*args, **kwargs) # ---> True return super(BaseSerializer, cls).__new__(cls, *args, **kwargs) # --> False # obj = CourseDetailSerializer.__new__ # obj.__init__ # many=False, # obj= CourseDetailSerializer的对象来进行序列化数据。 # obj.__init__ # many=True # obj = ListSerializer() 的对象来进行序列化数据。 # obj.__init__
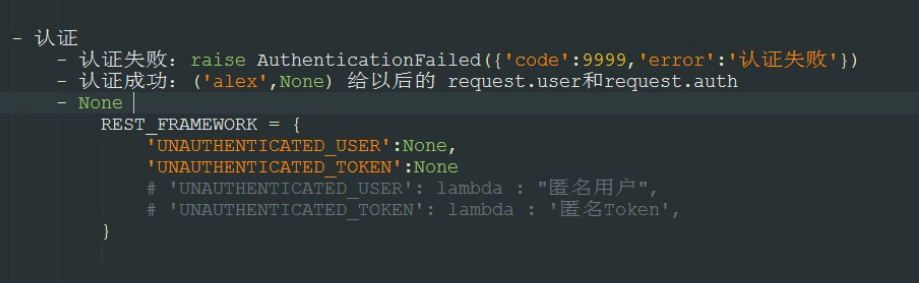
认证
配置版本
源码解析
当把url(r'^(?P<version>w+)')写成匹配任意版本型号 1:导入这个看关于版本的源码流程 from rest_framework.versioning import URLPathVersioning # 关于url版本 2:查看是否为规定版本 class URLPathVersioning(BaseVersioning): invalid_version_message = _('Invalid version in URL path.') # version --> 版本 def determine_version(self, request, *args, **kwargs): version = kwargs.get(self.version_param, self.default_version) if not self.is_allowed_version(version): # 判断是否为规定的版本 raise exceptions.NotFound(self.invalid_version_message) return version 3 def is_allowed_version(self, version): if not self.allowed_versions: ----> 当有的返回True return True return ((version is not None and version == self.default_version) or (version in self.allowed_versions)) 4:如果上没有,这里还有一层验证 class BaseVersioning(object): default_version = api_settings.DEFAULT_VERSION # 默认的版本 allowed_versions = api_settings.ALLOWED_VERSIONS
基于url版本的配置参数(需要配置的参数)
class BaseVersioning(object): default_version = api_settings.DEFAULT_VERSION # 默认的版本 allowed_versions = api_settings.ALLOWED_VERSIONS # 允许的版本 version_param = api_settings.VERSION_PARAM # 参数
将全部的api配置版本
设计url urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^api/(?P<version>[v1|v2]+)/', include('api.urls')), # url("login/$",login.LoginView.as_view()) ] 配置全局文件 # 配置版本相关 基于url的版本 , 最后三个参数看源码 'DEFAULT_VERSIONING_CLASS':'rest_framework.versioning.URLPathVersioning', 'DEFAULT_VERSION':'v1', 'ALLOWED_VERSIONS':['v1','v2'], 'VERSION_PARAM':'version'
关于继承GenericAPIView的queryset

印象深刻的事: 由于原来对于继承关系不太清楚,写接口 APIView/泛指GenericAPIView不太关注queryset 没有设置渲染器:默认 [JSONRenderer,BrowsableAPIRenderer] BrowsableAPIRenderer,内部检查当前视图函数是否有 get_queryset,如有则会调用。未设置,则断言异常。
关于每个视图需要设置renderer_classes = [JSONRenderer,]
所有视图都有功能:添加到配置文件
# 设置全局配置 REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES':['rest_framework.parsers.JSONParser'], # 解析器 'DEFAULT_RENDERER_CLASSES':['rest_framework.renderers.JSONRenderer'], # 渲染器
.html
url(r'^course/(?P<pk>d+).html$',course.CourseView.as_view({'get':'retrive'})),
加.html可以加重类似百度爬虫收录的显示权重
面试
django的orm操作怎么设置id不等于5
--->exclude排除
# 排除专题课 course_list = models.DegreeCourse.objects.all().only('id','name').exclude(course_type=3).order_by('-id')
# course_list是一个queryset = [obj,obj] QuerySet,是django的类型 # 获取url参数course_type # course_type = request.query_params.get("course_type") # 过滤专题课 # course_list = models.DegreeCourse.objects.all().only('id','name').filter(course_type=course_type).order_by('-id') # 有或的要求-->多个过滤条件 getlist取多个值 course_type = request.query_params.getlist('course_type') course_list = models.Course.objects.all().filter(course_type__in=course_type).only('id','name').order_by( '-id')
source
- 简单:fk/o2o/choice -> source - 复杂:m2m/gfk -> SerializerMethodField class CourseSerializer(ModelSerializer): category = serializers.CharField(source='sub_category.name') # 一对多的 xx = serializers.CharField(source='get_course_type_display') # 取课程类型 price_policy = serializers.SerializerMethodField() class Meta: model = models.Course fields = ['id', 'name','category','xx','price_policy'] def get_price_policy(self, obj): price_policy_list = obj.degreecourse_price_policy.all() return [{'id': row.id, 'price': row.price, 'period': row.get_valid_period_display()} for row in price_policy_list]
ajax
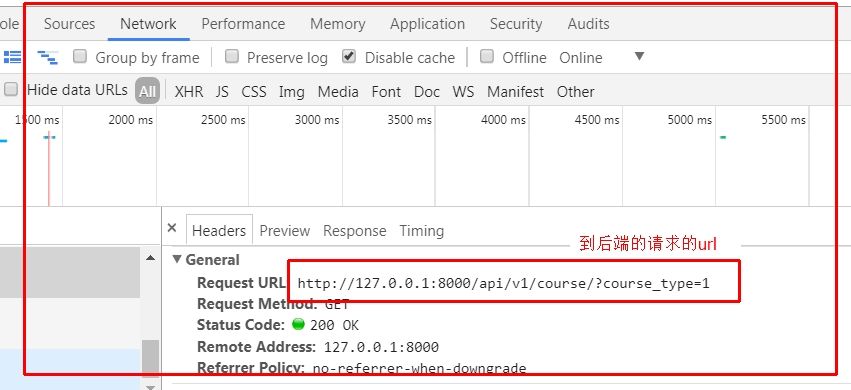
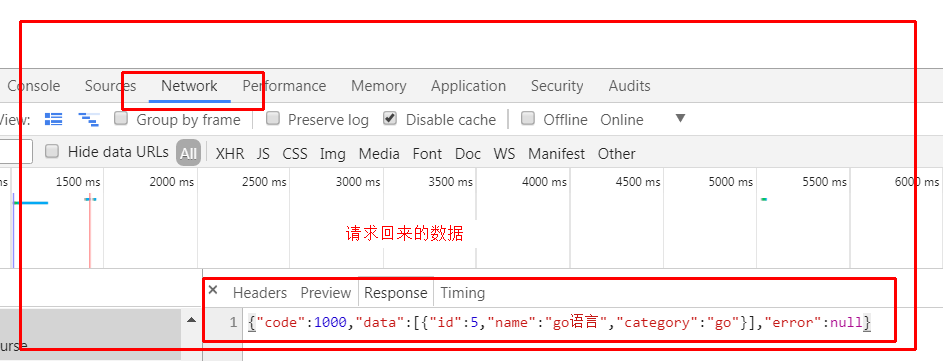
application/json作为请求content-type,告诉服务器请求的主题内容是json格式的字符串,
服务器端会对json字符串进行解析,这种方式的好处就是前端人员不需要关心数据结构的复杂度,
只要是标准的json格式就能提交成功
设置全局的请求头
// 在main.js // 设置全局的请求头 axios.defaults.headers['Content-Type'] = 'application/json'