VPP是什么?
Vector Packet Processing (VPP) ,详细概念可参考网站https://wiki.fd.io/view/VPP,这里仅为了学习效果记录关键点,并便于日后复习。
根据该英文网站内容的中文翻译可参考网站https://www.pianshen.com/article/65971780497/
为什么叫做向量包处理呢?怎样理解向量处理?
我们提出或者研究一项新的网络处理技术都是希望它能够更快的处理数据包(更快、更高、更强是人类的永恒追求),那么向量包处理也正是这个目的。众所周知,我们一般都是通过提高并发处理量来提高包处理效率。并行计算将要解决的问题分解为很多小问题,每个小问题可以被同时独立的进行计算。通过这种方式,问题分发给不同的处理元素,每个处理元素同步的执行其中一个子问题,会显著的增加计算的速度。如何通过这种方式处理事件呢?两个很好的方案分别是多核处理器,和本文提到的向量处理器。
什么是多核处理器?一个多核处理器是一个独立计算组件,通过使用多个串行处理器来执行并行计算,每个串行处理器执行一个不同的计算,这些计算同步进行。也就是说,一个大问题的每个子问题都由一个独立的处理器去计算以达到并行的效果。就像多个人执行一个大项目,每个人处理一个不同的任务,但都同时为同一个项目在作出贡献。这一点可能需要其他的组织来实现,不过项目的整体速度是加快了。
什么是向量处理器?向量处理器计算指令的方式与串行处理器一致,但是串行处理器只能处理单一数据集,而向量处理器可以直接操作一维数组(向量)指令集。其基本思路是,如果你正在一个程序中反复多次的做同一件事,每次使用不同的数据集,通常思路是对每个数据集执行一个独立的指令,向量处理器是对所有数据集只执行一次指令即可。SIMD(单指令多数据)通常用于表示指令按照这种方式工作。
多核处理器和向量处理器有何不同?这里通过一个例子来说明,可以忘记上面描述的一切,记住这个例子即可。假设我们想要将四个大石头滚到马路的另一边,平均滚动每个石头需要花费1分钟。串行处理器会逐一的滚动每个石头,将花费4分钟时间。拥有两个核的多核处理器让两个人去滚石头,即每人滚两个,最终花费2分钟。向量处理器找一根长木板,放到四个大石头后面,推木板即可同时滚动四个石头,最终只需要1分钟。多核处理器相当于拥有多个工人,而向量处理器拥有一种方法,可以同时对多件事进行相同的操作。
VPP技术特色
由于向量报文中的第一个报文packet-1为I-cache进行了热身,向量报文中剩下报文的处理性能可以直接达到极限,I-cache 缺失的固定开销平摊到了整个向量处理中,使单个报文的处理开销显著降低。由此可见,向量报文处理解决了标量处理的主要性能缺陷,和并行计算相比有具有如下优点:
- 解决了I-cache抖动问题
- 向量报文进行预取缓解了读时延问题,高性能并且更加稳定
服务的易插件化
VPP平台的图节点graph node组织方式,使用户可以根据需求,通过plugin方式插入新的图节点或者重新排列图节点,扩展非常方便,也不会影响原有核心处理流程。
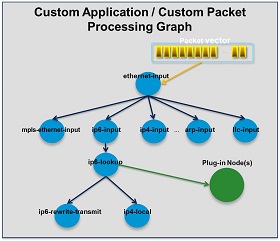
VPP怎么用?
VPP平台可以用于作为虚拟路由器或者虚拟交换机来使用。它支持很多标准的网络功能(L2 switching, L3 routing, NAT, encapsulations),并便于使用插件来进行扩展。 VPP平台使您可以通过命令行界面(CLI)管理这些应用程序的某些功能和配置。并和本地的程序、远程程序或者通过本地ODL和外部进行协作。如果是VDP与DPDK集成在一起,需要选择一定型号的NIC设备即网卡并在特定的OS架构上进行。我用的centos7.8+intel ixgbe网卡(X-540T2)
它不仅可以支持单个应用,还可以用于opendaylight等VNF(virtaul network function)场景和云计算网络环境。更多VPP的使用场景可以参考https://fd.io/overview/usecases/
VPP性能
VPP平台已显示提供以下近似性能指标:
- 来自单个x86_64内核的多个MPPS
- 单个物理主机上> 100Gbps全双工
- 多核扩展基准测试示例(在UCS-C240 M3上,3.5 gHz,转发了所有内存通道,简单的ipv4转发):
- 1个核心:9 MPPS进出
- 2核:13.4 MPPS进出
- 4核:20.0 MPPS进出
和OVSDPDK的路由转发性能相比,当路由条数从10条上升到1K条再到100K、2M条时VPP的转发性能并不会想OVSDPSK一样下降,而是基本保持线性水平。