MySQL源码:Range和Ref优化的成本评估
在开始介绍index merge/ROR优化之前,打算先介绍MySQL是如何对range/ref做成本评估的。MySQL是基于成本(cost)模型选择执行计划,在多个range,全表扫描,ref之间会选择成本最小的作为最终的执行计划。仍然强烈建议先阅读登博的slide:《查询优化浅析》,文中较为详细的介绍MySQL在range优化时成本的计算。
本文将继续介绍range/ref执行计划选择的一些不容忽略的细节。希望看客能够通过此文能够了解更多细节。
0. 成本计算的总原则
MySQL的一个执行计划,有两部分成本,CPU成本(CPU COST)和IO成本(IO COST)。
总成本 = CPU COST + IO COST
补充说明:(1) IO成本计算不考虑缓存的影响。因为在优化器本身是无法预知需要的数据到底在内存中还是磁盘上。
1. range成本的计算与分析
MySQL使用一颗SEL_ARG的树形结构描述了WHERE条件中的range,如果有多个range,则使用递归的方式遍历SEL_ARG结构,在前面详细的介绍range的红黑树结构,以及MySQL如何遍历之。
接上文,这里将看看,遍历到最后,MySQL如何计算一个简单range的成本。
1.1 range返回的记录数
MySQL首先计算range需要返回都少纪录,通过函数check_quick_select返回对某个索引做range查询大约命中多少条纪录。
found_records= check_quick_select(param, idx, *key, update_tbl_stats);
1.2 CPU COST
#define TIME_FOR_COMPARE 5 // 5 compares == one read
double cpu_cost= (double) found_records / TIME_FOR_COMPARE;
1.3 IO COST
对于InnoDB的二级索引,且不是覆盖扫描:
found_read_time := number of ranges + found_records
这里,found_records是主要部分,number of ranges表示一共有多少个range,这是一个修正值,表示IO COST不小于range的个数。
1.4 全表扫描的成本
具体的,对于InnoDB表,我们来看:
read_time= number of total page + (records / TIME_FOR_COMPARE + 1) + 1.1;
对于InnoDB取值为:主键索引(数据)所使用的page数量(stat_clustered_index_size)
对于MyISAM取值为:stats.data_file_length/IO_SIZE + file->tables
1.5 关于range执行计划的分析
这里来看看,range的选择度(selectivty)大概为多少的时候,会放弃range优化,而选择全表扫描。下面时一个定量的分析:
(1) 假设总记录数为R;range需要返回的纪录数为r
(2) 假设该表的总页面数(IO COST)为P;单个页面纪录数为c
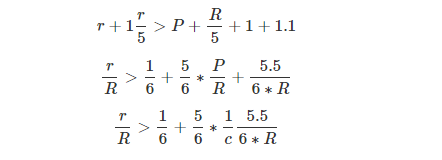
在我的测试案例中,P=4,R=1016 ,有
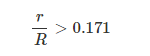
也就是说这个案例中,如果选择度(selectivity)高于17.1%就会放弃range优化,而走全表扫描。这里纪录数超过1016*0.171=173时将放弃range优化。
1.6 验证
MySQL通过函数check_quick_select返回range可能扫描的记录数,所以,这里通过对该函数设置断点,并手动设置返回值,通过此来验证上面对selectivity的计算,详细地:
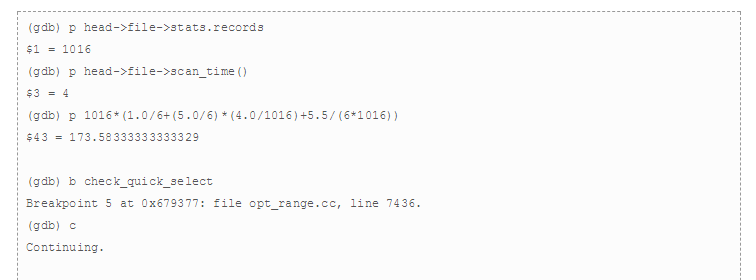
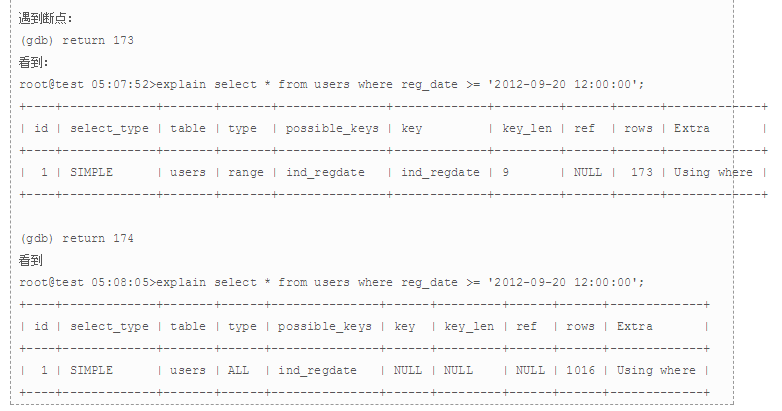
上面可以看到,如果range命中的记录数超过173的时候,就会放弃range,选择全表扫描。
1.7 一些限制
(1) 无论时InnoDB还是MyISAM的scan_time,range返回的记录数都不是精确值,而且对于InnoDB,总记录数也不是精确值,所以上面只是一个High level的预估。
(2) 上面案例中,条纪录很短,所以看到总page很少,实际情况,单条纪录更大,也就是上面的单个页面纪录数为c更小,所以通常选择度更高的时候,才会选择全表扫描。
2. ref成本的计算与分析
2.1 ref返回的记录数
ref优化的时候,计算返回的记录数从代码上来看要复杂很多,但是思想很简单。
思路:在range优化阶段,任何等值都会当作范围条件(参考1,参考2)。
对于kp1 = const and kp2 = const这类ref,MySQL将直接使用range优化时返回的结果,这个结果是通过存储引擎接口records_in_range返回。
还有一类较为特殊的ref,kp1 = const and kp2 > const,对于此类ref,range优化的时候,会使用两个索引列,但是ref只能用一个索引列。这时,ref首先根据索引统计信息(show index from users中Cardinality的值)预估。因为这里有range优化的值,还会做一次修正,因为range使用了更多的索引字段。修正逻辑为:如果发现索引统计信息太过保守(例如数据分布不均匀时,遇到一个热点),这时会用range优化的值修正。
所以,返回的纪录数,使用如下代码获取:
records= keyinfo->rec_per_key[max_key_part-1]
if(records < (double)table->quick_rows[key]...)
records= (double)table->quick_rows[key];
2.2 CPU COST
CPU COST := records/(double) TIME_FOR_COMPARE;
2.3 IO COST
ref在做IO成本评估的时候,基本同range相同,ref命中多少纪录则需要多少个IO COST。但是跟range优化打不同的是,这里做了一个修正(range优化并没有做),也是IO COST最坏不会超过全表扫描IO消耗的3倍(或者总记录数除以10),有下面的代码:
s->worst_seeks= min((double) s->found_records / 10,
(double) s->read_time*3);
IO COST := record_count*min(tmp,s->worst_seeks);
这里record_count是前一次关联后的记录数。tmp是当前ref命中的记录数。这个修正的逻辑是很好理解的:即使加上索引扫描其io cost仍然是有限度的。因为range的评估并没有加上这个修正,所以就导致了一些奇怪的事情发生了,后面我们再详细分析这一点。
2.4 全表扫描的成本
简单版本(不考虑多表关联):
scan_time() + s->records/TIME_FOR_COMPARE
scan_time()为存储引擎返回的全表扫描IO次数;s->records为存储引擎维护的单表总纪录数。
复杂版本(有多表关联):
假设前面关联后的纪录数为record_count,当前表的where条件将过滤后剩余3/4的纪录(不满足where条件的为1/4),并将这个值记为rnd_records。
(s->records - rnd_records)/TIME_FOR_COMPARE + record_count * (rnd_records/TIME_FOR_COMPARE)
这里假设将过滤1/4数据,实际代码中还将做一次修正,如果有range计算,假设其命中q条纪录,那么就认为将过滤s->records-q条纪录。
2.5 关于ref执行计划的分析
上面的分析,可以看到,ref成本有一部分是取min函数的,为了分析ref和全表扫描的临界条件,为了简化做下面的假设:
(1) scan_time()*3 < s->records / 10
(2) scan_time()*3 < r
第一个条件表示约30条纪录一个page;第二个条件是ref命中的记录数为总页面的3倍。
那么放弃ref全表扫描的条件是:
scan_time()*3 + r/5 > scan_time() + R/5
即:
scan_time()*2 > (R-r)/5
scan_time() > (R-r)/10
具体的:
(1) 假设总记录数为R;ref需要返回的纪录数为r
(2) 假设该表的总页面数(IO COST)为P;单个页面纪录数为c
那么range的代价超过全表扫描代价,则有:
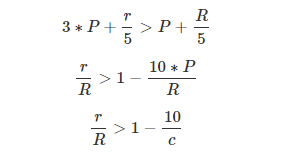
在我的测试案例中,P=6.4,R=900 ,有
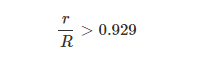
对于具体的案例,由于取整的问题,会和上面有小小的偏差:
3*((int)6.39) + r/5 > 6.39453125 + 900/5
r > 841.97
2.6 验证
这里再通过gdb修改r的值来验证,因为ref命中纪录的预估是取range的计算值,所以:
gdb) set s->table->quick_rows[1]=841
(gdb) croot@test 04:37:16>explain select * from users where reg_date = '2012-09-21 12:00:00';
+----+-------------+-------+------+---------------+-------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-------------+---------+-------+------+-------------+
| 1 | SIMPLE | users | ref | IND_REGDATE | IND_REGDATE | 9 | const | 841 | Using where |
+----+-------------+-------+------+---------------+-------------+---------+-------+------+-------------+
1 row in set (47.61 sec)(gdb) set s->table->quick_rows[1]=842
(gdb) croot@test 04:38:46>explain select * from users where reg_date = '2012-09-21 12:00:00';
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | users | ALL | IND_REGDATE | NULL | NULL | NULL | 900 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
另一个结论是,如果当条记录很小,单个页面的记录数很多的话,只有选择度(selectivity)非常高的时候,MySQL才会放弃ref,走全表扫描,这也是,Vadim在2006年吐槽MySQL的一点。
3. 上面计算的局限性
上面的推倒尝试介绍一些通用的情况,但是实际上优化器中计算ref/range的成本时,会有一些不同:
(1) 无论时InnoDB还是MyISAM的scan_time,range返回的记录数都不是精确值,而且对于InnoDB,总记录数也不是精确值,所以上面只是一个High level的预估
(2) 上面案例中,条纪录很短,所以看到总page很少,实际情况,单条纪录更大,也就是上面的单个页面纪录数为c更小,所以通常选择度更高的时候,才会选择全表扫描。
(3) 上面的计算,都不是覆盖扫描的情况,覆盖扫描的时候,成本计算与上面略有不同
(4) 上面都是使用gdb修改某些值的方式来验证。如果想通过创建一个表,够造某个索引的区分度/选制度,因为scan_time和返回的记录数都是预估的,这样的方式是不行的
(5) (update) range的cost计算,最终的公式是:#rows + (#rows/5)*2 + 1 解释如下,
** #rows 为IO成本,因为读取的记录都需要回表查找完整记录,而这些都是离散IO,所以多少条记录,多少个IO
** (#rows/5)*2 是CPU成本,分两部分,第一部分是扫描索引时,确定在查找范围内;第二部分是找到记录后判断是否满足WHERE条件;(这部分成本,在range analysis的时候没有计算)
** 1是一个修正值,防止0成本出现
4. 案例中使用的数据和表
CREATE TABLE `users` (
`id` int(11) NOT NULL, `nick` varchar(32) DEFAULT NULL,
`reg_date` datetime DEFAULT NULL,
KEY `IND_NICK` (`nick`),
KEY `IND_REGDATE` (`reg_date`),
KEY `IND_ID` (`id`) ) ENGINE=MyISAM
for id in `seq 1 886`;
do mysql -uroot test -e
"insert into users values($id,char(round(ord('A') + rand()*(ord('z')-ord('A')))), '2012-09-21 12:00:00')" ;done
for id in `seq 887 900`;
do mysql -uroot test -e
"insert into users values($id,char(round(ord('A') + rand()*(ord('z')-ord('A')))), '2012-09-20 12:00:00')" ;done