PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。Google的创始人拉里·佩奇和谢尔盖·布林于1998年在斯坦福大学发明了这项技术。
1.算法原理
对于某个互联网网页A来说,该网页PageRank的计算基于以下两个基本假设:
数量假设:在Web图模型中,如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
质量假设:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
2. PageRank计算公式
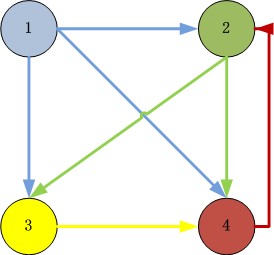
假设一个由4个页面组成的小团体:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
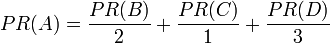
换句话说,根据链出总数平分一个页面的PR值。
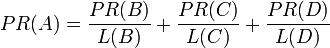
最后,所有这些被换算为一个百分比再乘上一个系数 。由于“没有向外链接的页面”传递出去的PageRank会是0,所以,Google通过数学系统给了每个页面一个最小值
。由于“没有向外链接的页面”传递出去的PageRank会是0,所以,Google通过数学系统给了每个页面一个最小值 :
:
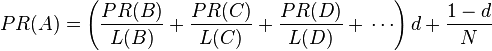
完整的
这个方程式引入了随机浏览的概念,即有人上网无聊随机打开一些页面,点一些链接。一个页面的PageRank值也影响了它被随机浏览的概率。为了便于理解,这里假设上网者不断点网页上的链接,最终到了一个没有任何链出页面的网页,这时候上网者会随机到另外的网页开始浏览。
为了处理那些“没有向外链接的页面”(这些页面就像“黑洞”会吞噬掉用户继续向下浏览的概率)带来的问题,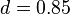 (这里的被称为阻尼系数(damping
factor),其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率。
(这里的被称为阻尼系数(damping
factor),其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率。 就是用户停止点击,随机跳到新URL的概率)的算法被用到了所有页面上,估算页面可能被上网者放入书签的概率。
就是用户停止点击,随机跳到新URL的概率)的算法被用到了所有页面上,估算页面可能被上网者放入书签的概率。
所以,这个等式如下:

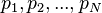 是被研究的页面,
是被研究的页面,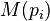 是链入
是链入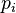 页面的集合,
页面的集合, 是
是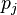 链出页面的数量,而
链出页面的数量,而 是所有页面的数量。
是所有页面的数量。
PageRank值是一个特殊矩阵中的特征向量。这个特征向量为

R是等式的答案
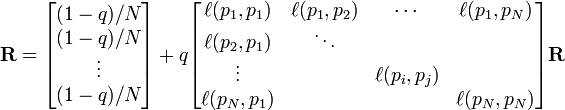
3. 利用幂法求矩阵的最大特征值和特征向量
链接源页面 链接目标页面
1 2,3,4
2 3,4
3 4
4 21,3
1,4
2,3
2,4
3,4
4,2
pages<-read.csv("page.csv",header=FALSE);
#构造邻接矩阵(方阵):
mrow<-max(pages)
A<-matrix(0,nrow=4,ncol=4);
cols=length(pages[1,]);
rows=length(pages[,1]);
for(i in 1:rows){
p1<-pages[i,1];
p2<-pages[i,2];
A[p2,p1]<-1;
}
#转换为概率矩阵(转移矩阵)
csum<-colSums(A);
csum[csum==0] <- 1;
Arow=nrow(A);
for(i in 1:Arow){
A[i,]<-A[i,]/csum;
}
#利用幂法求解特征向量
x <- rep(1,Arow);
for (i in 1:10) x <- A %*% x4. R代码的解析:
一、 P概率转移矩阵的计算过程:
先建立一个网页间的链接关系的模型,即我们需要合适的数据结构表示页面间的连接关系。
1) 首先我们使用图的形式来表述网页之间关系:
现在假设只有四张网页集合:A、B、C,其抽象结构如下图1:

图1 网页间的链接关系
显然这个图是强连通的(从任一节点出发都可以到达另外任何一个节点)。
2)我们用矩阵表示连通图:
用邻接矩阵 P表示这个图中顶点关系 ,如果顶(页面)i向顶点(页面)j有链接情况 ,则pij = 1 ,否则pij = 0 。如图2所示。如果网页文件总数为N , 那么这个网页链接矩阵就是一个N x N 的矩 阵 。
3)网页链接概率矩阵
然后将每一行除以该行非零数字之和,即(每行非0数之和就是链接网个数)则得到新矩阵P’,如图3所示。 这个矩阵记录了 每个网页跳转到其他网页的概率,即其中i行j列的值表示用户从页面i 转到页面j的概率。图1 中A页面链向B、C,所以一个用户从A跳转到B、C的概率各为1/2。
4)概率转移矩阵P
采用P’ 的转置矩 阵进行计算, 也就是上面提到的概率转移矩阵P 。 如图4所示:




图4 P’ 的转置矩 阵
二、 A矩阵计算过程。
1)P概率转移矩阵 :

2) /N 为:
/N 为:

3)A矩阵为:q × P + ( 1 一 q) * /N = 0.85 × P + 0.15 * /N

初始每个网页的 PageRank值均为1 , 即X~t = ( 1 , 1 , 1 ) 。
三、 循环迭代计算PageRank的过程
第一步:

因为X 与R的差别较大。 继续迭代。
第二步:

继续迭代这个过程...
直到最后两次的结果近似或者相同,即R最终收敛,R 约等于X,此时计算停止。最终的R 就是各个页面的 PageRank 值。
用幂法计算PageRank 值总是收敛的,即计算的次数是有限的。
Larry Page和Sergey Brin 两人从理论上证明了不论初始值如何选取,这种算法都保证了网页排名的估计值能收敛到他们的真实值。
由于互联网上网页的数量是巨大的,上面提到的二维矩阵从理论上讲有网页数目平方之多个元素。如果我们假定有十亿个网页,那么这个矩阵 就有一百亿亿个元素。这样大的矩阵相乘,计算量是非常大的。Larry Page和Sergey Brin两人利用稀疏矩阵计算的技巧,大大的简化了计算量。
为什么递归几次就求得特征向量呢,请参考
《利用幂法求矩阵的最大特征值和特征向量》
http://blog.csdn.net/luckisok/article/details/1602266
本文参考了以下文章:
R语言实现
http://blog.fens.me/algorithm-pagerank-r/
数学角度分析PageRank
http://blog.csdn.net/hguisu/article/details/7996185
wiki
http://zh.wikipedia.org/wiki/PageRank
版权声明:本文为博主原创文章,未经博主允许不得转载。