1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表

3、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和 from A group by 类别 order by sum(数量) desc
返回结果如下表
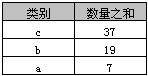
4、Group By中Select指定的字段限制
示例3
select 类别, sum(数量) as 数量之和, 摘要 from A group by 类别 order by 类别 desc
示例3执行后会提示错误。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
5、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
6、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A group by 类别 having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A where 数量 gt;8 group by 类别 having SUM(数量) gt; 10
本文转载自:http://www.cnblogs.com/rainman/archive/2013/05/01/3053703.html