计算机容量:
在ASSIC中 每一个字符统一都需要8个bit来存储

1位 = 1bit
8bit = 1byte = 1字节
1024bytes = 1kbytes =1KB 1024个字符
1024KB = 1Million Bytes = 1MB = 1兆
1024MB = 1G
1024GB = 1TB
1024TB = 1PB
字符编码:
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- unicode 万国码 支持所有国家和地区的编码,2-4字节,汉字一般2个字节
- UTF-8 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- 总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
Python3的执行过程:
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成Unicode(自动转成Unicode)
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
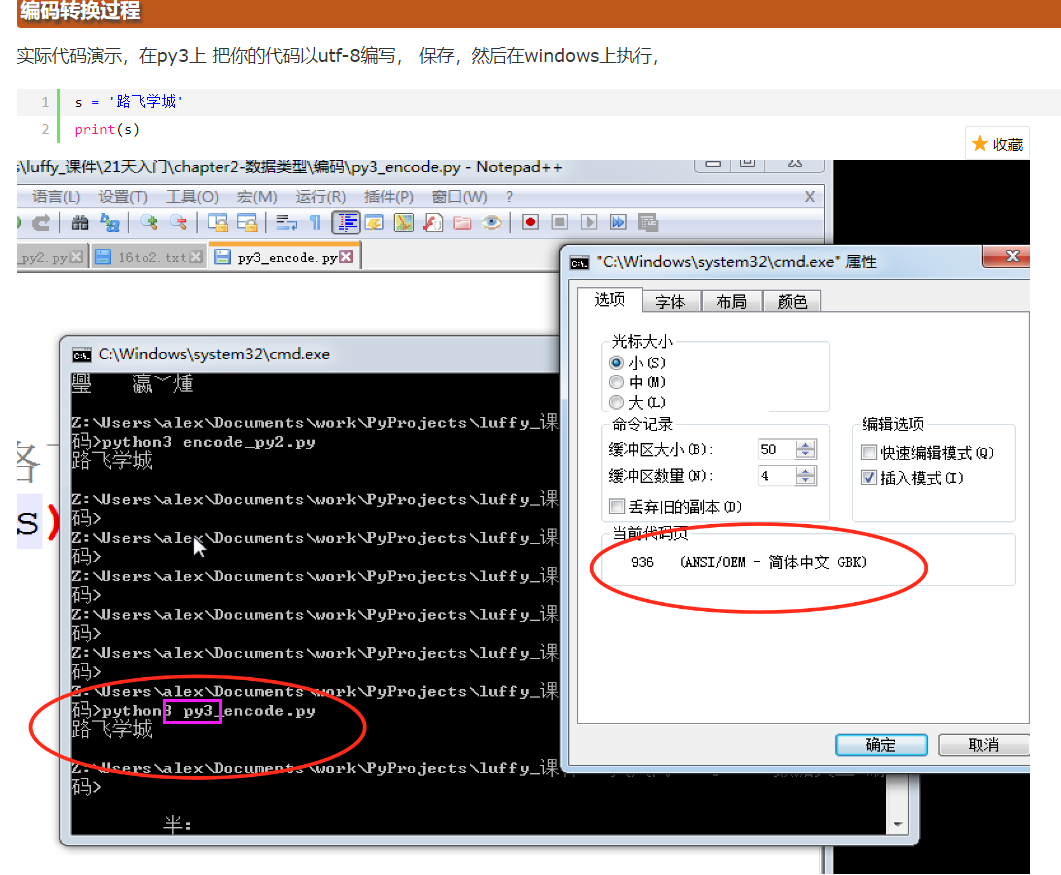
上面的utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode , 但是这只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如 万恶的python2 就不是, 它的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味着什么你知道么?。。。意味着,你以utf-8编码的文件,在windows是乱码。
Python2中默认的字符串编码是ASCII码,加载到内存中不会自动转成Unicode。
因为只有2种情况 ,在windows上显示才不会乱
- 字符串以GBK格式显示
- 字符串是unicode编码
这就需要用到encode(转码)和decode(解码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8 ..
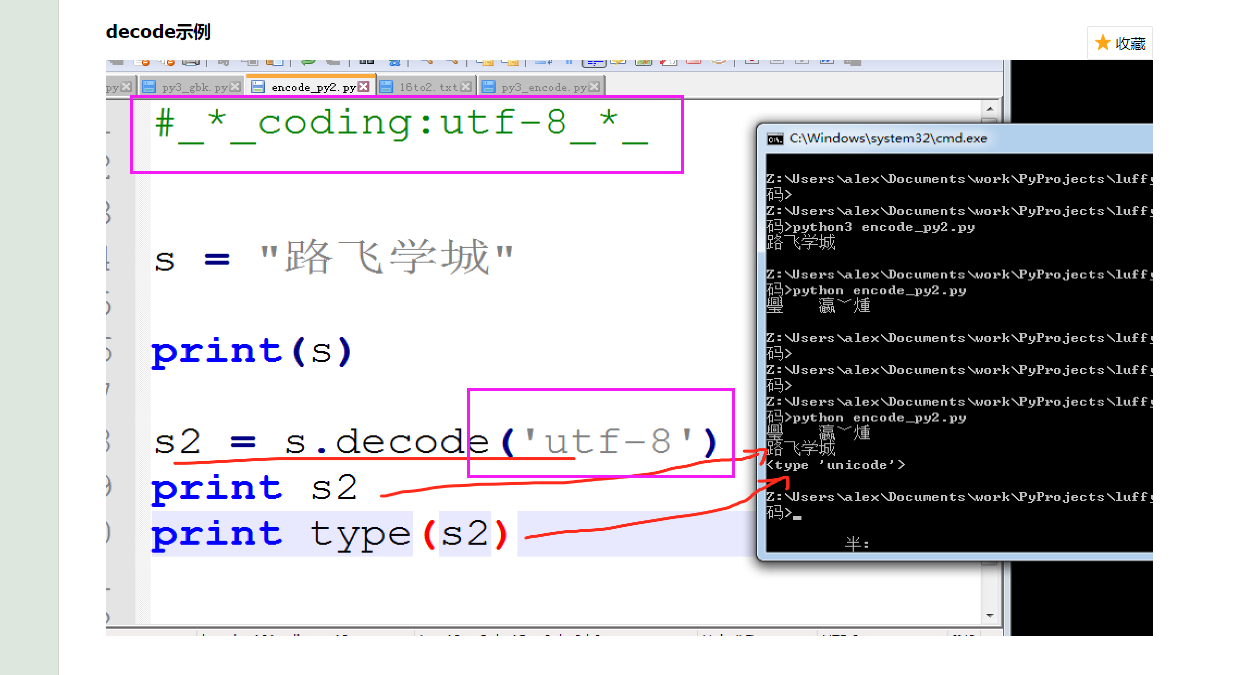
先decode()成Unicode,括号中加的编码就是文件头编码,告诉python2这是用什么编码写的程序。

把Unicode编码成GBK,这样就可以显示中文了。
总结:
1、python3文件编码默认是utf-8,字符串编码默认是Unicode,默认支持中文,加载到内存中是字符串,编码是Unicode,自动转成GBK显示。
2、pyrhon2文件编码和字符串编码默认都是ASCII码,默认不支持中文,需要在文件头上加上或者进行解码和编码:
# -*- coding: UTF-8 -*- 
#coding=utf-8
3、保存的文件是什么编码就需要用什么编码打开否则会乱码。
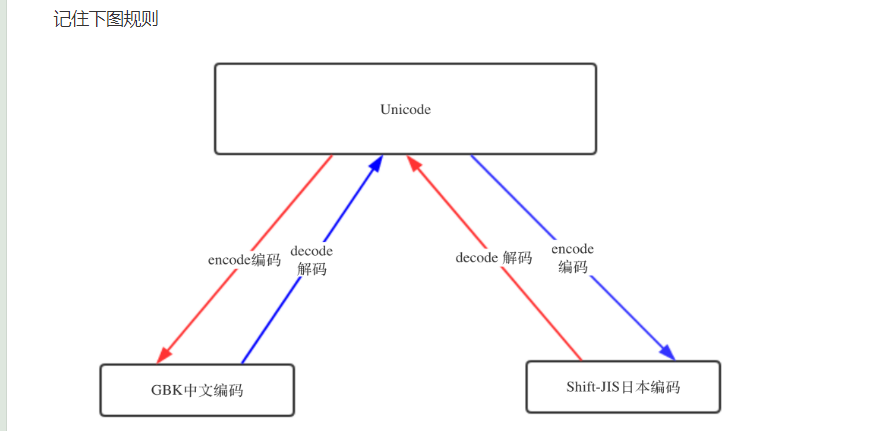
Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有:
- Python解释器的默认编码
- Python源文件文件编码
- Terminal使用的编码
- 操作系统的语言设置
python3

py3中中文的bytes类型表示不出来,需要编码成其他(utf-8、gbk)编码方式才能显示出来
