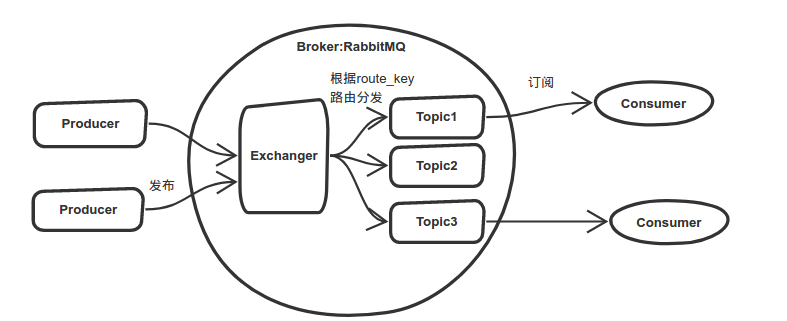
RabbitMQ和Kafka一样,都是消息中间件。RabbitMQ中有多个队列,每个队列称之为一个Topic。生产者Producer首先需要连接到RabbitMQ中的指定队列,即在连接的时候指明消息发送到哪个Topic中。消费者Consumer也需要连接到RabbitMQ,并指定订阅哪个Topic,即从哪个队列拉取消息进行消费。在Consumer中有一个回调函数,用于说明消费完这个消息之后该做什么事,通常就是向RabbitMQ发送一个ACK信号,表示消息已经被成功消费,可以从队列中删除了。如果消费者在处理消息的时候突然宕机了,那么RabbitMQ中的队列依然存在,可以继续发送给其他消费者进行处理。
只要消费者一直不断运行着(监听),那么生产者只要一发送消息到RabbitMQ中,就会被立即分发到对应的消费者中进行消费。此外,RabbitMQ中的消息还可以持久化到磁盘中。
在Ubuntu中安装RabbitMQ: sudo apt-get install rabbitmq-server
python程序要连接到RabbitMQ中,需要import pika,pika是AMQP协议的开源python实现:
sudo pip install pika
在RabbitMQ中,可以通过 sudo rabbitmqctl list_queues 命令查看到当前RabbitMQ中的队列及其对应的消息个数,<"Topic",num>,数据结构类似于Map。
消息发送端:
#!/usr/bin/env python
#coding=utf8
import sys
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
channel.queue_declare(queue='libi',durable=True)
message = ' '.join(sys.argv[1:]) or "bili111111111"
channel.basic_publish(exchange='', routing_key='libi', body=message,properties=pika.BasicProperties(delivery_mode = 2,))
print "Sent %r" % (message,)
connection.close()
消息消费端:
# !/usr/bin/env python
# coding=utf8
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
channel.queue_declare(queue='libi')
def callback(ch, method, properties, body):
print "Received %r" % (body,)
time.sleep(5)
print "done"
channel.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, queue='libi', no_ack=False)
channel.start_consuming()