一个服务端同时可以接受多个客户端的连接,每个连接都是一个SocketChannel(Channel中的一种),这些Channel共同连接到Selector上(服务端仅需要一个选择器),channel会注册感兴趣的事件到Selector中,当调用Select方法返回后,会遍历所有的套接字描述符(服务端进程为每一个socket连接创建一个描述符),一旦某个描述符就绪,就通知应用程序进行相应的读写操作。Selector下面会接一个Buffer缓冲区,所有的数据都会先到达内核的缓冲区中,然后再read(汇聚/发散)到用户态应用程序的内存缓冲区中。
在select中,描述符存放在一个数组中,当调用select()方法的时候,进程会阻塞,直到数组中有某些描述符处于就绪状态,此时select()方法返回,然后遍历该数组,处理这些描述符。select的缺点就是进程可以监视的描述符只有1024个,如果连接数再多的话就不行了。
poll的实现和select非常相似,只是描述fd集合的方式不同。select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
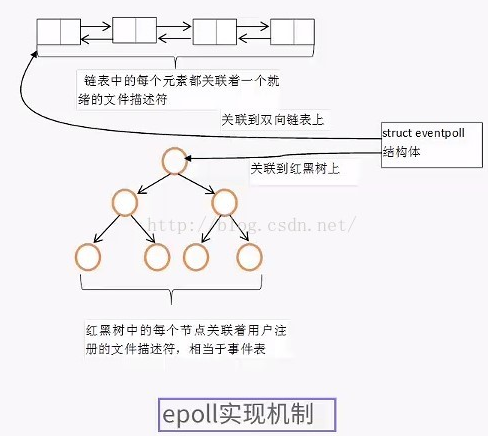
epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄,epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。epoll的优点是不受描述符数量的限制,能够支持非常高的并发请求。epoll方式在每个描述符上定义了一个回调函数,只有当就绪的描述符才会执行回调函数,加入就绪队列中等待应用程序去处理,而不需要每次都遍历fd容器。如果没有大量的idle -connection或者dead-connection,epoll的效率并不会比select/poll高很多,但是当遇到大量的idle-connection,就会发现epoll的效率大大高于select/poll。
epoll高效的原理是利用了就绪队列和红黑树:将注册的事件插入到红黑树中,这样每次操作系统找就绪的事件就比较快,找到后就链到就绪队列的链表中,这样每次epoll_wait 就只处理就绪队列的事件,比起poll和 select每次全部遍历一遍高效的多。
select,poll,epoll都是IO多路复用的机制,该机制可以监视多个描述符,一旦某个描述符就绪,能够通知程序进行相应的读写操作。select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
传统IO中,IO线程和event_process(事件处理)线程是在一起的,也就是来多少socket连接,就要开多少线程去读写IO并处理该请求。如果有很多的长连接,但是大多socket连接处于idle-connection或者dead-connection状态,那么这些线程都需要持续保留,浪费系统资源。
IO多路复用,将IO线程和事件处理线程区分开,事件处理线程放在一个线程池中,而IO线程只有一个,即Selector线程.只有就绪的描述符才会被线程池(事件处理线程)处理掉,其他连接上但是未就绪的描述符,不用专门去开线程维护。