上次我博客上,发表一篇有关性能测试的博客. http://www.cnblogs.com/jake1/archive/2013/04/23/3039101.html. 当时有些网友说我那数据量大少,没多少可对比性.其实我当时做的性能测试数据也是10万多的. 做出来的性能.
为了,获取更准确的数据,于是我数据加到100多万. 然后就感觉插入相当慢,查询和修改 倒不会发现性能上有很大差别.后来一想,才知道,因为我是用guid 作为主键的.所以会出现这种情况. 关于guid和自增id 在现在数据库中是经常使用的.至于他们的优缺点,我就不在这里讨论了.
我在这里只想说的是,如果你选择了guid作为你的主键,尤其是你的表数据量比较大的话,要考虑用顺序的guid,这样才能在插入数据上,就会获得比较大的性能提升.关于这这里性能数据,请看我的压力测试结果.
没有顺序guid的
方法[sqlDB_add ]: 成功数3940 ,失败数6060 ,完成数10000 ,平均时间19373.24毫秒,[]
方法[sqlDB_add ]: 成功数7539 ,失败数2461 ,完成数10000 ,平均时间11449.45毫秒,[]
方法[sqlDB_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间3041.29毫秒,[]
方法[sqlDB_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间1867.23毫秒,[]
方法[sqlDB_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间1222.81毫秒,[]
方法[sqlDB_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间452.04 毫秒,[]
方法[sqlDB_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间576.00 毫秒,[]
方法[entityFramework_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间2678.54毫秒,[]
方法[entityFramework_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间642.82 毫秒,[]
方法[entityFramework_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间737.68 毫秒,[]
有顺序guid 的.
方法[sqlDB_add ]: 成功数10000 ,失败数0 ,完成数10000 ,平均时间22.62 毫秒,[]
方法[sqlDB_add ]: 成功数10000 ,失败数0 ,完成数10000 ,平均时间4.77 毫秒,[]
方法[sqlDB_add ]: 成功数10000 ,失败数0 ,完成数10000 ,平均时间25.20 毫秒,[]
方法[entityFramework_add ]: 成功数10000 ,失败数0 ,完成数10000 ,平均时间737.95 毫秒,[]
方法[entityFramework_add ]: 成功数10000 ,失败数0 ,完成数10000 ,平均时间276.65 毫秒,[]
方法[entityFramework_add ]: 成功数10000 ,失败数0 ,完成数10000 ,平均时间243.29 毫秒,[]
方法[entityFramework_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间169.56 毫秒,[]
方法[entityFramework_add ]: 成功数1000 ,失败数0 ,完成数1000 ,平均时间167.05 毫秒,[]
从测试数据上看,有序guid 的性能上会比没有顺序会快很多.我想这其中的原理,就不用我说了.主要是当用无序的guid 在插入数据时,会产生数据移动,造成性能上会有一定的损耗,尤其是数据量越大,损耗就越多.至于为什么 用ef框架在使用有序guid时,会比.net慢好多,我将在下面会做解释.
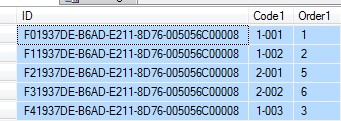
让我先说说,怎样做有序的guid,那就是在数据库里的字段里设置默认函数是NEWSEQUENTIALID(),利用NEWSEQUENTIALID()新生成的值大于上一次生成的值,就可实现有序的的id。
CREATE TABLE GUID_SORT_TABLEA( ID uniqueidentifier default NEWSEQUENTIALID(), Code1 nvarchar(10), Order1 smallint) GO
exec sp_executesql N'declare @generated_keys table([ID] uniqueidentifier) insert [dbo].[testTable]([MonthlyDataID], [AccountCode], [AccountName], [Amount], [Year], [Month], [Class], [Appendix], [DealerCode], [DataStatus], [Memo], [IsPercent], [UploadStatus], [Status], [CreationUser], [CreationDate], [ModificaitonUser], [ModificationDate]) output inserted.[ID] into @generated_keys values (@0, null, null, null, @1, @2, null, null, null, null, @3, @4, null, @5, null, null, @6, @7) select t.[ID] from @generated_keys as g join [dbo].[BMW_MonthlyDataDetail] as t on g.[ID] = t.[ID] where @@ROWCOUNT > 0',N'@0 uniqueidentifier,@1 int,@2 int,@3 nvarchar(500),@4 bit,@5 smallint,@6 varchar(50),@7 datetime2(7)',@0='D88C7815-748D-43E5-9599-F37B0CD88CB3',@1=2012,@2=11,@3=N'hsdgsg',@4=1,@5=1,@6='jake',@7='2013-04-26 21:33:45.6696389'
它是先插入数据,然后再连表查出新生成的guid.所以性能上肯定会慢.
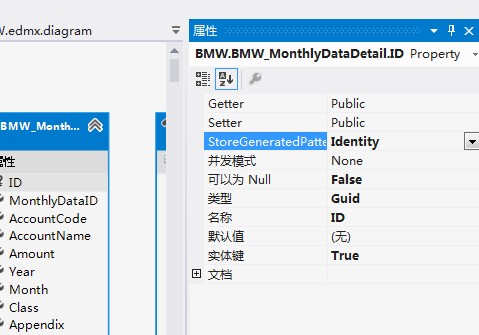
在这里我也想补充一点.就是用ef 框架,要使用默认的函数,作为它的id,必须要设置idIdentity 为Identity,.具体设置如图
好,上面就是我对有序guid的一些研究,希望对家有帮助.