本篇主要内容如下:
前言
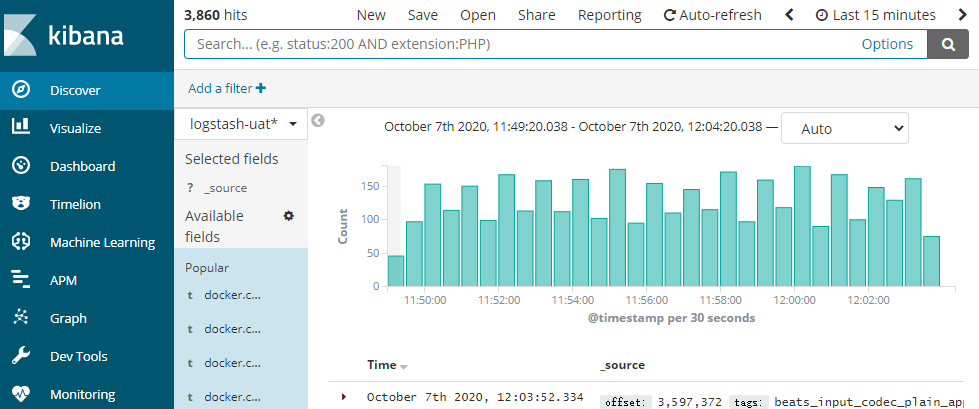
项目中我们总是用 Kibana 界面来搜索测试或生产环境下的日志,来看下有没有异常信息。Kibana 就是 我们常说的 ELK 中的 K。
Kibana 界面如下图所示:
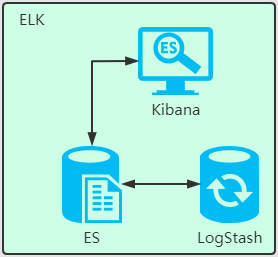
但这些日志检索原理是什么呢?这里就该我们的 Elasticsearch 搜索引擎登场了。
我会分为三篇来讲解 Elasticsearch(简称ES)的原理、实战及部署。
- 上篇: 讲解 ES 的原理、中文分词的配置。
- 中篇: 实战 ES 应用。
- 下篇: ES 的集群部署。
为什么要分成三篇,因为每一篇都很长,而且侧重点不一样,所以分成三篇来讲解。
一、Elasticsearch 简介
1.1 什么是 Elasticsearch?
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。简单来说只要涉及搜索和分析相关的, ES 都可以做。
1.2 Elasticsearch 的用途?
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 比如一个在线网上商店,您可以在其中允许客户搜索您出售的产品。在这种情况下,您可以使用Elasticsearch 存储整个产品目录和库存,并为它们提供搜索和自动完成建议。
- 比如收集日志或交易数据,并且要分析和挖掘此数据以查找趋势,统计信息,摘要或异常。在这种情况下,您可以使用 Logstash(Elasticsearch / Logstash / Kibana堆栈的一部分)来收集,聚合和解析数据,然后让 Logstash 将这些数据提供给 Elasticsearch。数据放入 Elasticsearch 后,您可以运行搜索和聚合以挖掘您感兴趣的任何信息。
1.3 Elasticsearch 的工作原理?
Elasticsearch 是在 Lucene 基础上构建而成的。ES 在 Lucence 上做了很多增强。
Lucene 是apache软件基金会 4 的 jakarta 项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。(来自百度百科)
Elasticsearch 的原始数据从哪里来?
原始数据从多个来源 ( 包括日志、系统指标和网络应用程序 ) 输入到 Elasticsearch 中。
Elasticsearch 的数据是怎么采集的?
数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。这里用到了 Logstash,后面会介绍。
怎么可视化查看想要检索的数据?
这里就要用到 Kibana 了,用户可以基于自己的数据进行搜索、查看数据视图等。
1.4 Elasticsearch 索引是什么?
Elasticsearch 索引指相互关联的文档集合。Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键 ( 字段或属性的名称 ) 和它们对应的值 ( 字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据 ) 之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
1.5 Logstash 的用途是什么?
Logstash 就是 ELK 中的 L。
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
1.6 Kibana 的用途是什么?
Kibana 是一款适用于 Elasticsearch 的数据可视化和管理工具,可以提供实时的直方图、线性图等。
1.7 为什么使用 Elasticsearch
- ES 很快,近实时的搜索平台。
- ES 具有分布式的本质特质。
- ES 包含一系列广泛的功能,比如数据汇总和索引生命周期管理。
官方文档:https://www.elastic.co/cn/what-is/elasticsearch
二、ES 基本概念
2.1 Index ( 索引 )
动词:相当于 Mysql 中的 insert
名词:相当于 Mysql 中的 database
与 mysql 的对比
| 序号 | Mysql | Elasticsearch |
|---|---|---|
| 1 | Mysql 服务 | ES 集群服务 |
| 2 | 数据库 Database | 索引 Index |
| 3 | 表 Table | 类型 Type |
| 4 | 记录 Records ( 一行行记录 ) | 文档 Document ( JSON 格式 ) |
2.2 倒排索引
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
假如数据库有如下电影记录:
1-大话西游
2-大话西游外传
3-解析大话西游
4-西游降魔外传
5-梦幻西游独家解析
分词:将整句分拆为单词
| 序号 | 保存到 ES 的词 | 对应的电影记录序号 |
|---|---|---|
| A | 西游 | 1,2, 3,4, 5 |
| B | 大话 | 1,2, 3 |
| C | 外传 | 2,4, 5 |
| D | 解析 | 3,5 |
| E | 降魔 | 4 |
| F | 梦幻 | 5 |
| G | 独家 | 5 |
检索:独家大话西游
将 独家大话西游 解析拆分成 独家、大话、西游
ES 中 A、B、G 记录 都有这三个词的其中一种, 所以 1,2, 3,4, 5 号记录都有相关的词被命中。
1 号记录命中 2 次, A、B 中都有 ( 命中 2 次 ) ,而且 1 号记录有 2 个词,相关性得分:2 次/2 个词=1
2 号记录命中 2 个词 A、B 中的都有 ( 命中 2 次 ) ,而且 2 号记录有 2 个词,相关性得分:2 次/3 个词= 0.67
3 号记录命中 2 个词 A、B 中的都有 ( 命中 2 次 ) ,而且 3 号记录有 2 个词,相关性得分:2 次/3 个词= 0.67
4 号记录命中 2 个词 A 中有 ( 命中 1 次 ) ,而且 4 号记录有 2 个词,相关性得分:1 次/3 个词= 0.33
5 号记录命中 2 个词 A 中有 ( 命中 2 次 ) ,而且 4 号记录有 4 个词,相关性得分:2 次/4 个词= 0.5
所以检索出来的记录顺序如下:
1-大话西游 ( 想关性得分:1 )
2-大话西游外传 ( 想关性得分:0.67 )
3-解析大话西游 ( 想关性得分:0.67 )
5-梦幻西游独家解析 ( 想关性得分:0.5 )
4-西游降魔 ( 想关性得分:0.33 )
三、Docker 搭建环境
3.1. 搭建 Elasticsearch 环境
搭建虚拟机环境和安装 docker 可以参照之前写的文档:
1 ) 下载镜像文件
docker pull elasticsearch:7.4.2
2 ) 创建实例
-
- 映射配置文件
配置映射文件夹
mkdir -p /mydata/elasticsearch/config
配置映射文件夹
mkdir -p /mydata/elasticsearch/data
设置文件夹权限任何用户可读可写
chmod 777 /mydata/elasticsearch -R
配置 http.host
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
-
- 启动 elasticsearch 容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300
-e "discovery.type"="single-node"
-e ES_JAVA_OPTS="-Xms64m -Xmx128m"
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins
-d elasticsearch:7.4.2
-
- 访问 elasticsearch 服务
返回的 reponse
{
"name" : "8448ec5f3312",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "xC72O3nKSjWavYZ-EPt9Gw",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
访问:http://192.168.56.10:9200/_cat 访问节点信息
127.0.0.1 62 90 0 0.06 0.10 0.05 dilm * 8448ec5f3312
3.2. 搭建 Kibana 环境
docker pull kibana:7.4.2
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
访问 kibana: http://192.168.56.10:5601/
四、初阶检索玩法
4.1._cat 用法
GET /_cat/nodes: 查看所有节点
GET /_cat/health: 查看 es 健康状况
GET /_cat/master: 查看主节点
GET /_cat/indices: 查看所有索引
查询汇总:
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
4.2. 索引一个文档 ( 保存 )
例子:在 customer 索引下的 external 类型下保存标识为 1 的数据。
- 使用 Kibana 的 Dev Tools 来创建
PUT member/external/1
{
"name":"jay huang"
}
Reponse:
{
"_index": "member", //在哪个索引
"_type": "external",//在那个类型
"_id": "2",//记录 id
"_version": 7,//版本号
"result": "updated",//操作类型
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1
}
- 也可以通过 Postman 工具发送请求来创建记录。
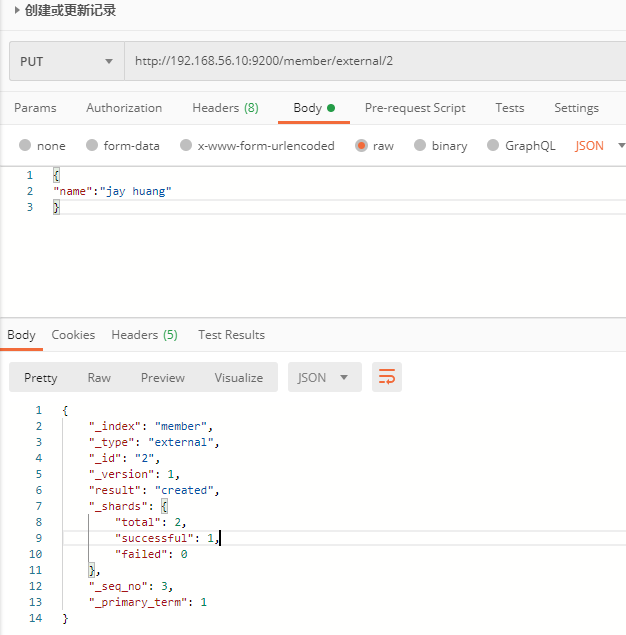
注意:
PUT 和 POST 都可以创建记录。
POST:如果不指定 id,自动生成 id。如果指定 id,则修改这条记录,并新增版本号。
PUT:必须指定 id,如果没有这条记录,则新增,如果有,则更新。
4.3 查询文档
请求:http://192.168.56.10:9200/member/external/2
Reposne:
{
"_index": "member", //在哪个索引
"_type": "external", //在那个类型
"_id": "2", //记录 id
"_version": 7, //版本号
"_seq_no": 9, //并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, //同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": { //真正的内容
"name": "jay huang"
}
}
_seq_no 用作乐观锁
每次更新完数据后,_seq_no 就会+1,所以可以用作并发控制。
当更新记录时,如果_seq_no 与预设的值不一致,则表示记录已经被至少更新了一次,不允许本次更新。
用法如下:
请求更新记录 2: http://192.168.56.10:9200/member/external/2?if_seq_no=9&&if_primary_term=1
返回结果:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 9,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1
}
_seq_no 等于 10,且_primary_term=1 时更新数据,执行一次请求后,再执行上面的请求则会报错:版本冲突
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, required seqNo [10], primary term [1]. current document has seqNo [11] and primary term [1]",
"index_uuid": "CX6uwPBKRByWpuym9rMuxQ",
"shard": "0",
"index": "member"
}
],
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, required seqNo [10], primary term [1]. current document has seqNo [11] and primary term [1]",
"index_uuid": "CX6uwPBKRByWpuym9rMuxQ",
"shard": "0",
"index": "member"
},
"status": 409
}
4.4 更新文档
- 用法
POST 带 _update 的更新操作,如果原数据没有变化,则 repsonse 中的 result 返回 noop ( 没有任何操作 ) ,version 也不会变化。
请求体中需要用 doc 将请求数据包装起来。
POST 请求:http://192.168.56.10:9200/member/external/2/_update
{
"doc":{
"name":"jay huang"
}
}
响应:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 12,
"result": "noop",
"_shards": {
"total": 0,
"successful": 0,
"failed": 0
},
"_seq_no": 14,
"_primary_term": 1
}
使用场景:对于大并发更新,建议不带 _update。对于大并发查询,少量更新的场景,可以带_update,进行对比更新。
- 更新时增加属性
请求体中增加 age 属性
http://192.168.56.10:9200/member/external/2/_update
request:
{
"doc":{
"name":"jay huang",
"age": 18
}
}
response:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 13,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 15,
"_primary_term": 1
}
4.5 删除文档和索引
- 删除文档
DELETE 请求:http://192.168.56.10:9200/member/external/2
response:
{
"_index": "member",
"_type": "external",
"_id": "2",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
- 删除索引
DELETE 请求:http://192.168.56.10:9200/member
repsonse:
{
"acknowledged": true
}
- 没有删除类型的功能
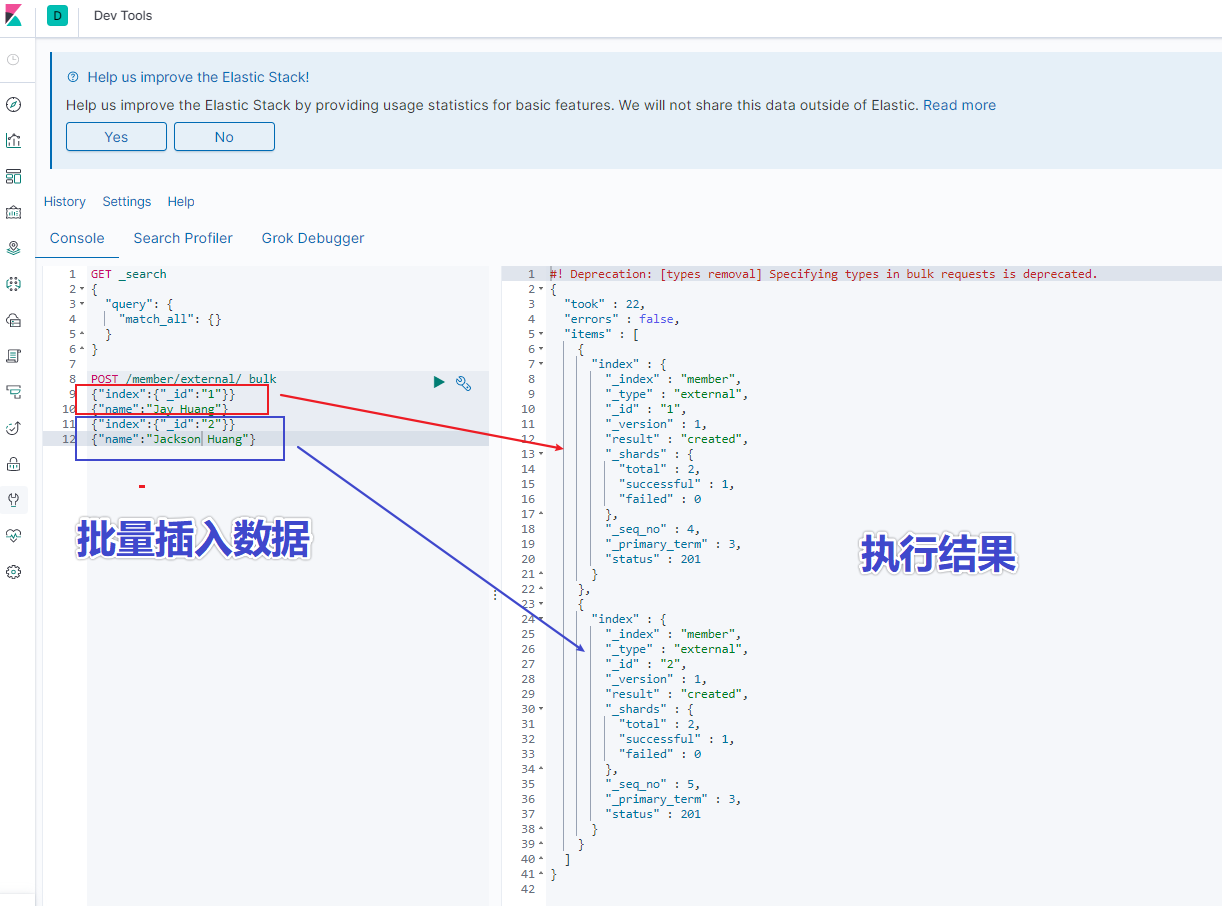
4.6 批量导入数据
使用 kinaba 的 dev tools 工具,输入以下语句
POST /member/external/_bulk
{"index":{"_id":"1"}}
{"name":"Jay Huang"}
{"index":{"_id":"2"}}
{"name":"Jackson Huang"}
执行结果如下图所示:
- 拷贝官方样本数据
https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json

- 在 kibana 中执行脚本
POST /bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
......
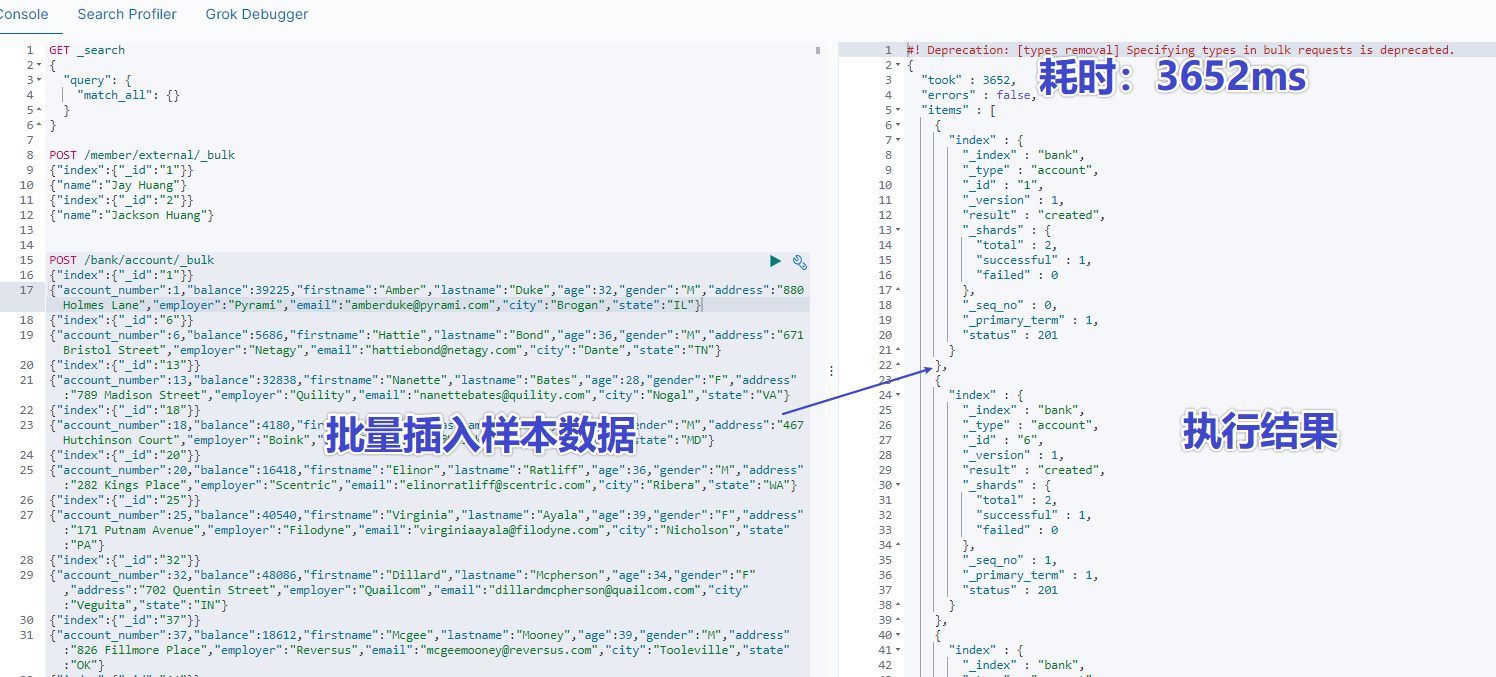
- 查看所有索引
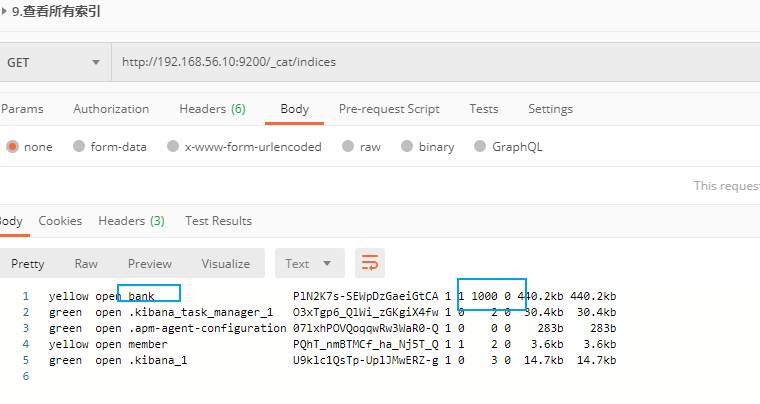
可以从返回结果中看到 bank 索引有 1000 条数据,占用了 440.2kb 存储空间。
五、高阶检索玩法
5.1 两种查询方式
5.1.1 URL 后接参数
GET bank/_search?q=*&sort=account_number: asc
```/_search?q=*&sort=account_number: asc`
查询出所有数据,共 1000 条数据,耗时 1ms,只展示 10 条数据 ( ES 分页 )
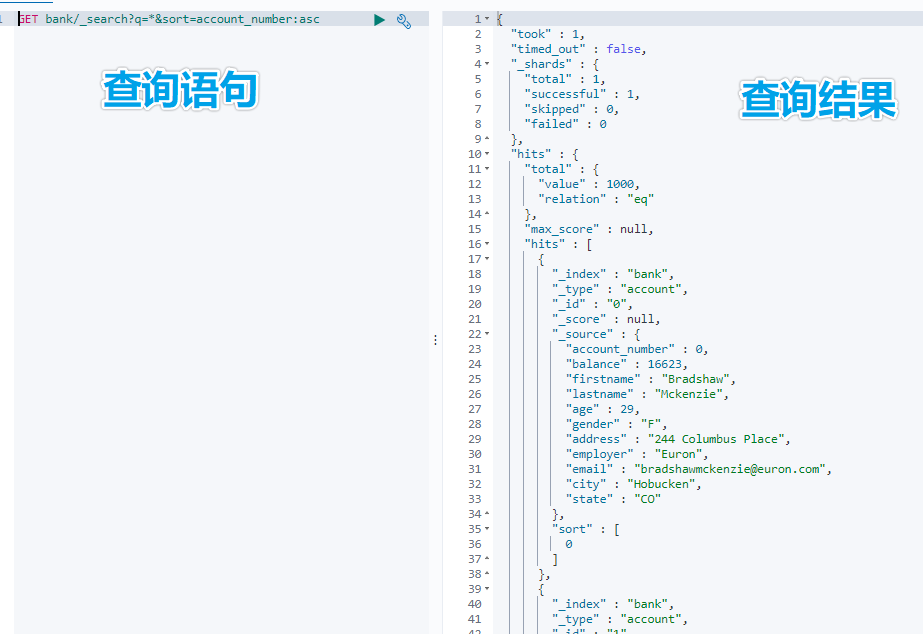
属性值说明:
took – ES 执行搜索的时间 ( 毫秒 )
timed_out – ES 是否超时
_shards – 有多少个分片被搜索了,以及统计了成功/失败/跳过的搜索的分片
max_score – 最高得分
hits.total.value - 命中多少条记录
hits.sort - 结果的排序 key 键,没有则按 score 排序
hits._score - 相关性得分
参考文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-search.html
5.1.2 URL 加请求体进行检索 ( QueryDSL )
请求体中写查询条件
语法:
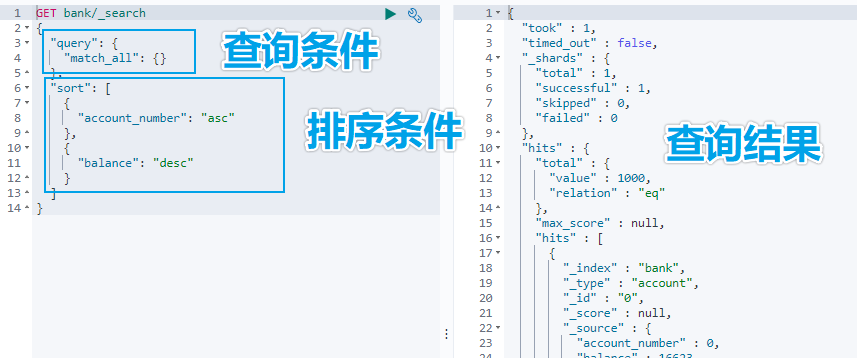
GET bank/_search
{
"query":{"match_all": {}},
"sort": [
{"account_number": "asc" }
]
}
示例:查询出所有,先按照 accout_number 升序排序,再按照 balance 降序排序
5.2 详解 QueryDSL 查询
DSL: Domain Specific Language
5.2.1 全部匹配 match_all
示例:查询所有记录,按照 balance 降序排序,只返回第 11 条记录到第 20 条记录,只显示 balance 和 firstname 字段。
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 10,
"size": 10,
"_source": ["balance", "firstname"]
}
5.2.2 匹配查询 match
- 基本类型 ( 非字符串 ) ,精确匹配
GET bank/_search
{
"query": {
"match": {"account_number": "30"}
}
}
- 字符串,全文检索
GET bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
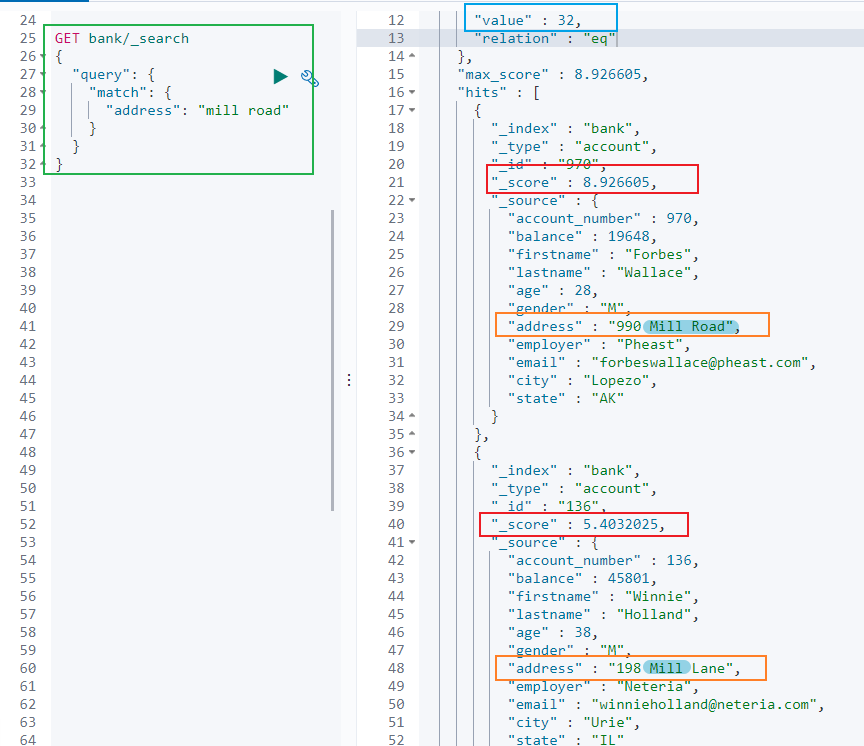
全文检索按照评分进行排序,会对检索条件进行分词匹配。
查询
address中包含mill或者road或者mill road的所有记录,并给出相关性得分。
查到了 32 条记录,最高的一条记录是 Address = "990 Mill Road",得分:8.926605. Address="198 Mill Lane" 评分 5.4032025,只匹配到了 Mill 单词。
5.2.3 短语匹配 match_phase
将需要匹配的值当成一个整体单词 ( 不分词 ) 进行检索
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
查出 address 中包含
mill road的所有记录,并给出相关性得分
5.2.4 多字段匹配 multi_match
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill land",
"fields": [
"state",
"address"
]
}
}
}
multi_match 中的 query 也会进行分词。
查询
state包含mill或land或者address包含mill或land的记录。
5.2.5 复合查询 bool
复合语句可以合并任何其他查询语句,包括复合语句。复合语句之间可以相互嵌套,可以表达复杂的逻辑。
搭配使用 must,must_not,should
must: 必须达到 must 指定的条件。 ( 影响相关性得分 )
must_not: 必须不满足 must_not 的条件。 ( 不影响相关性得分 )
should: 如果满足 should 条件,则可以提高得分。如果不满足,也可以查询出记录。 ( 影响相关性得分 )
示例:查询出地址包含 mill,且性别为 M,年龄不等于 28 的记录,且优先展示 firstname 包含 Winnie 的记录。
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
},
{
"match": {
"gender": "M"
}
}
],
"must_not": [
{
"match": {
"age": "28"
}
}
],
"should": [
{
"match": {
"firstname": "Winnie"
}
}
]
}
}
}
5.2.6 filter 过滤
不影响相关性得分,查询出满足 filter 条件的记录。
在 bool 中使用。
GET bank/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte":18,
"lte":40
}
}
}
]
}
}
}
5.2.7 term 查询
匹配某个属性的值。
全文检索字段用 match,其他非 text 字段匹配用 term
keyword:文本精确匹配 ( 全部匹配 )
match_phase:文本短语匹配
非 text 字段精确匹配
GET bank/_search
{
"query": {
"term": {
"age": "20"
}
}
}
5.2.8 aggregations 聚合
聚合:从数据中分组和提取数据。类似于 SQL GROUP BY 和 SQL 聚合函数。
Elasticsearch 可以将命中结果和多个聚合结果同时返回。
聚合语法:
"aggregations" : {
"<聚合名称 1>" : {
"<聚合类型>" : {
<聚合体内容>
}
[,"元数据" : { [<meta_data_body>] }]?
[,"aggregations" : { [<sub_aggregation>]+ }]?
}
[,"聚合名称 2>" : { ... }]*
}
- 示例 1:搜索 address 中包含 big 的所有人的年龄分布 ( 前 10 条 ) 以及平均年龄,以及平均薪资
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAggr": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvg": {
"avg": {
"field": "age"
}
},
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
检索结果如下所示:
hits 记录返回了,三种聚合结果也返回了,平均年龄 34 随,平均薪资 25208.0,品骏年龄分布:38 岁的有 2 个,28 岁的有一个,32 岁的有一个
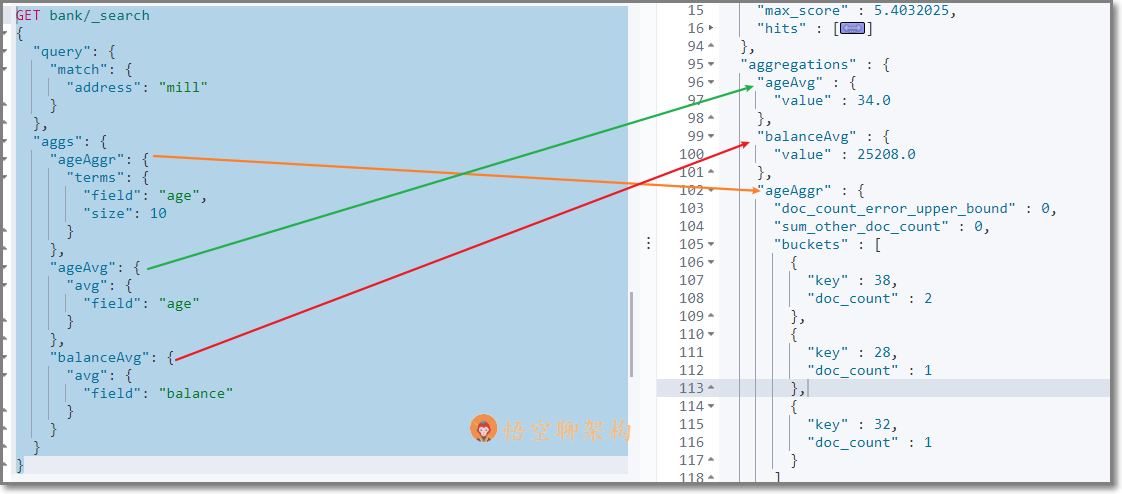
如果不想返回 hits 结果,可以在最后面设置 size:0
GET bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAggr": {
"terms": {
"field": "age",
"size": 10
}
}
},
"size": 0
}
- 示例 2:按照年龄聚合,并且查询这些年龄段的平均薪资
从结果可以看到 31 岁的有 61 个,平均薪资 28312.9,其他年龄的聚合结果类似。
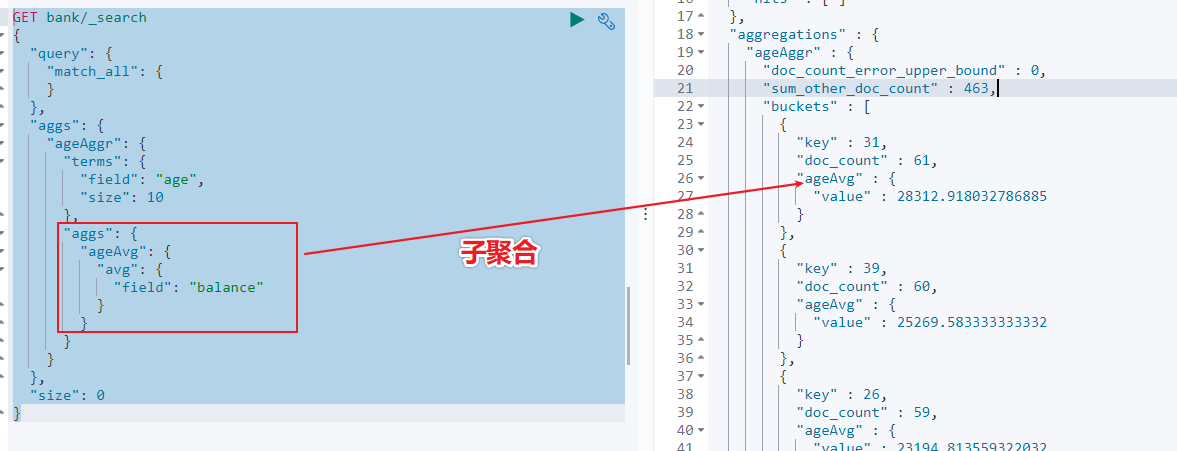
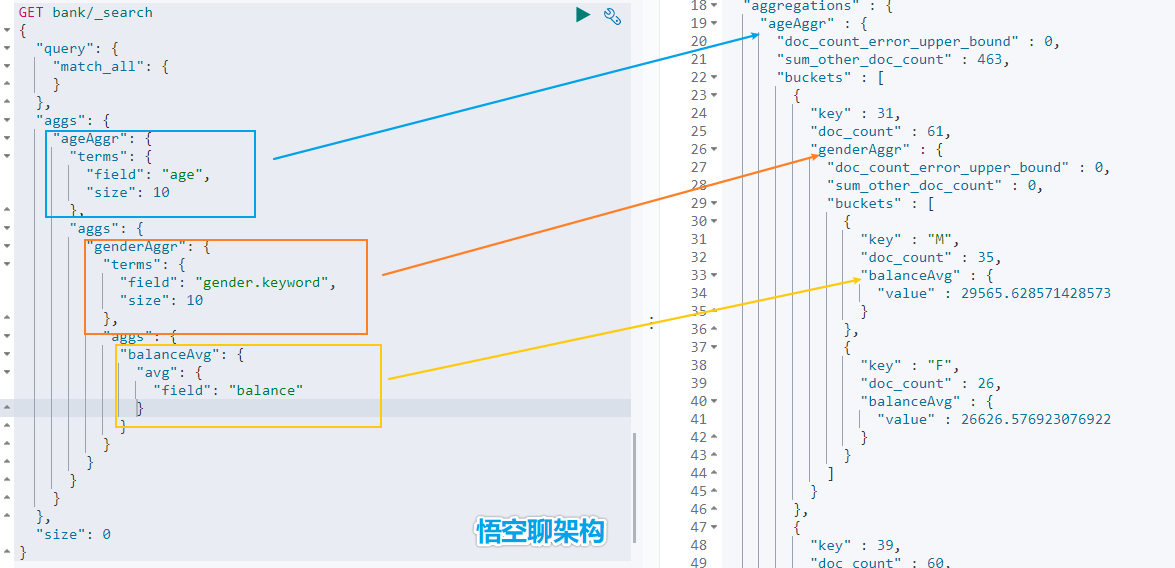
- 示例 3:按照年龄分组,然后将分组后的结果按照性别分组,然后查询出这些分组后的平均薪资
GET bank/_search
{
"query": {
"match_all": {
}
},
"aggs": {
"ageAggr": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"genderAggr": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
},
"size": 0
}
从结果可以看到 31 岁的有 61 个。其中性别为 M 的 35 个,平均薪资 29565.6,性别为 F 的 26 个,平均薪资 26626.6。其他年龄的聚合结果类似。
5.2.9 Mapping 映射
Mapping 是用来定义一个文档 ( document ) ,以及它所包含的属性 ( field ) 是如何存储和索引的。
- 定义哪些字符串属性应该被看做全文本属性 ( full text fields )
- 定义哪些属性包含数字,日期或地理位置
- 定义文档中的所有属性是否都能被索引 ( _all 配置 )
- 日期的格式
- 自定义映射规则来执行动态添加属性
Elasticsearch7 去掉 tpye 概念:
关系型数据库中两个数据库表示是独立的,即使他们里面有相同名称的列也不影响使用,但 ES 中不是这样的。elasticsearch 是基于 Lucence 开发的搜索引擎,而 ES 中不同 type 下名称相同的 field 最终在 Lucence 中的处理方式是一样的。
为了区分不同 type 下的同一名称的字段,Lucence 需要处理冲突,导致检索效率下降
ES7.x 版本:URL 中的 type 参数为可选。
ES8.x 版本:不支持 URL 中的 type 参数
所有类型可以参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
- 查询索引的映射
如查询 my-index 索引的映射
GET /my-index/_mapping
返回结果:
{
"my-index" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"employee-id" : {
"type" : "keyword",
"index" : false
},
"name" : {
"type" : "text"
}
}
}
}
}
- 创建索引并指定映射
如创建 my-index 索引,有三个字段 age,email,name,指定类型为 interge, keyword, text
PUT /my-index
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
返回结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my-index"
}
- 添加新的字段映射
如在 my-index 索引里面添加 employ-id 字段,指定类型为 keyword
PUT /my-index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
- 更新映射
我们不能更新已经存在的映射字段,必须创建新的索引进行数据迁移。
- 数据迁移
POST _reindex
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
六、中文分词
ES 内置了很多种分词器,但是对中文分词不友好,所以我们需要借助第三方中文分词工具包。
6.1 ES 中的分词的原理
6.1.1 ES 的分词器概念
ES 的一个分词器 ( tokenizer ) 接收一个字符流,将其分割为独立的词元 ( tokens ) ,然后输出词元流。
ES 提供了很多内置的分词器,可以用来构建自定义分词器 ( custom ananlyzers )
6.1.2 标准分词器原理
比如 stadard tokenizer 标准分词器,遇到空格进行分词。该分词器还负责记录各个词条 ( term ) 的顺序或 position 位置 ( 用于 phrase 短语和 word proximity 词近邻查询 ) 。每个单词的字符偏移量 ( 用于高亮显示搜索的内容 ) 。
6.1.3 英文和标点符号分词示例
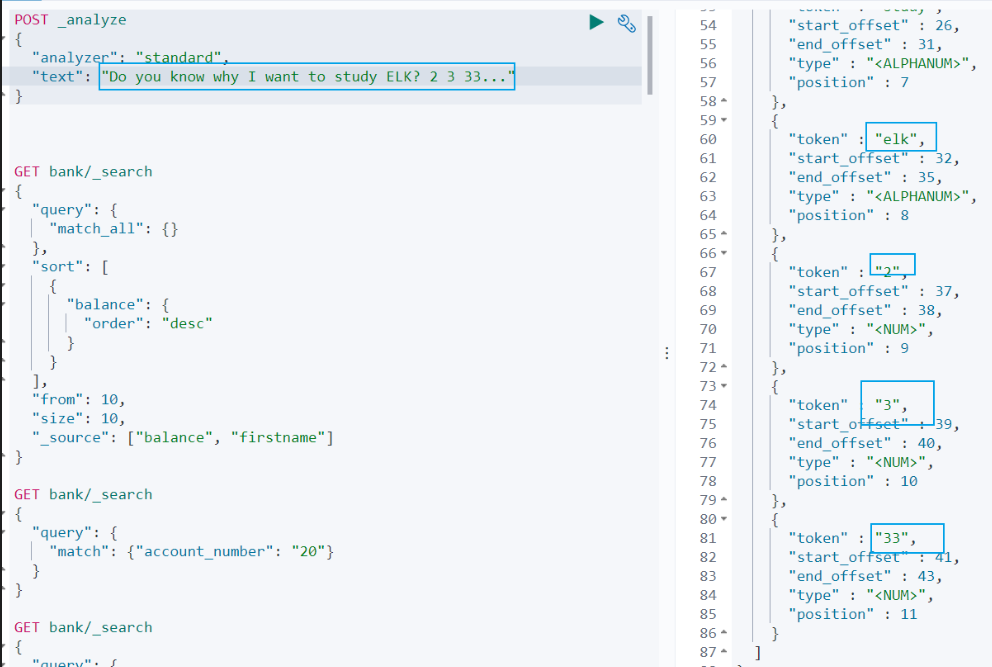
查询示例如下:
POST _analyze
{
"analyzer": "standard",
"text": "Do you know why I want to study ELK? 2 3 33..."
}
查询结果:
do, you, know, why, i, want, to, study, elk, 2,3,33
从查询结果可以看到:
(1)标点符号没有分词。
(2)数字会进行分词。
6.1.4 中文分词示例
但是这种分词器对中文的分词支持不友好,会将词语分词为单独的汉字。比如下面的示例会将 悟空聊架构 分词为 悟,空,聊,架,构,期望分词为 悟空,聊,架构。
POST _analyze
{
"analyzer": "standard",
"text": "悟空聊架构"
}
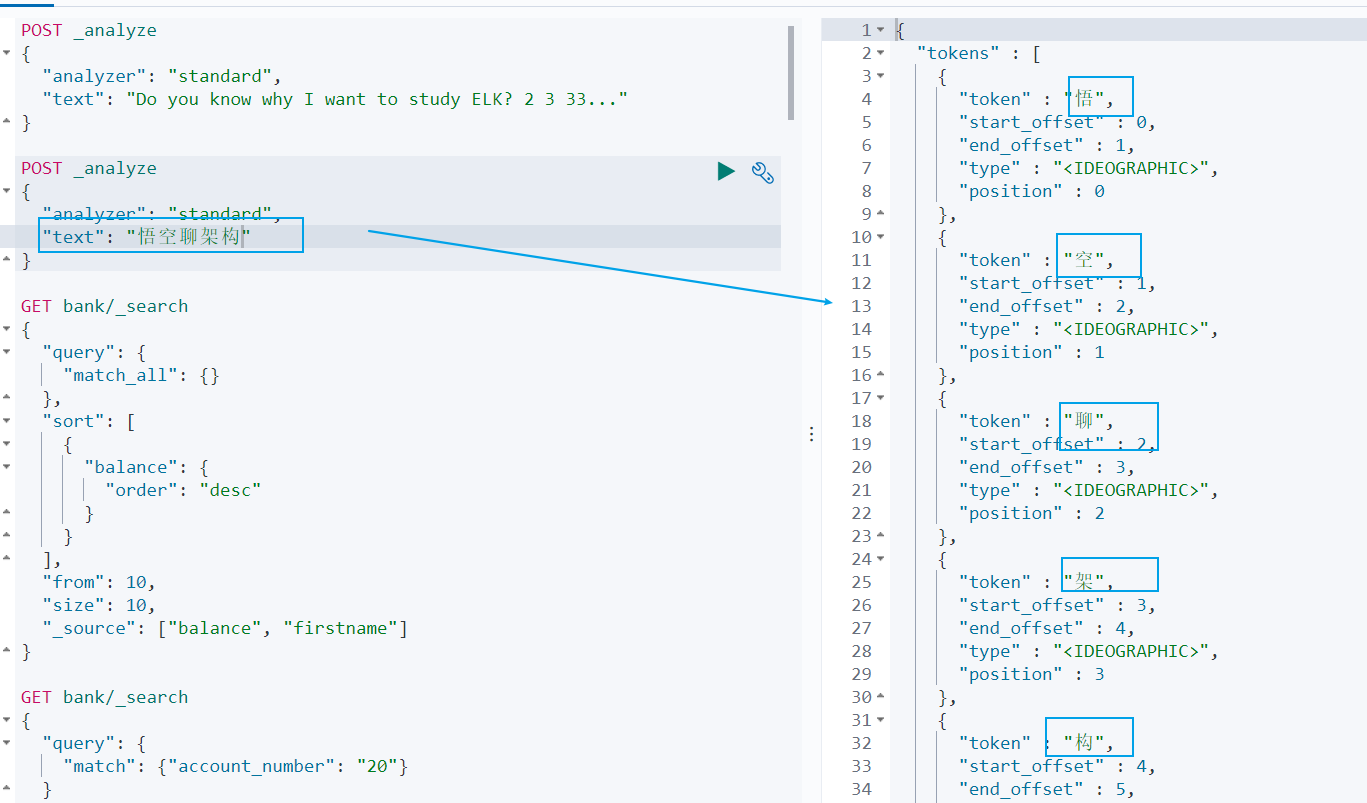
我们可以安装 ik 分词器来更加友好的支持中文分词。
6.2 安装 ik 分词器
6.2.1 ik 分词器地址
ik 分词器地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
先检查 ES 版本,我安装的版本是 7.4.2,所以我们安装 ik 分词器的版本也选择 7.4.2
http://192.168.56.10:9200/
{
"name" : "8448ec5f3312",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "xC72O3nKSjWavYZ-EPt9Gw",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
6.2.2 安装 ik 分词器的方式
6.2.2.1 方式一:容器内安装 ik 分词器
- 进入 es 容器内部 plugins 目录
docker exec -it <容器 id> /bin/bash
- 获取 ik 分词器压缩包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 解压缩 ik 压缩包
unzip 压缩包
- 删除下载的压缩包
rm -rf *.zip
6.2.2.2 方式二:映射文件安装 ik 分词器
进入到映射文件夹
cd /mydata/elasticsearch/plugins
下载安装包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
- 解压缩 ik 压缩包
unzip 压缩包
- 删除下载的压缩包
rm -rf *.zip
6.2.2.3 方式三:Xftp 上传压缩包到映射目录
先用 XShell 工具连接虚拟机 ( 操作步骤可以参考之前写的文章 [02. 快速搭建 Linux 环境-运维必备] ( http://www.jayh.club/#/05. 安装部署篇/01. 环境搭建篇 )) ,然后用 Xftp 将下载好的安装包复制到虚拟机。
6.3 解压 ik 分词器到容器中
- 如果没有安装 unzip 解压工具,则安装 unzip 解压工具。
apt install unzip
- 解压 ik 分词器到当前目录的 ik 文件夹下。
命令格式:unzip <ik 分词器压缩包>
实例:
unzip ELK-IKv7.4.2.zip -d ./ik

- 修改文件夹权限为可读可写。
chmod -R 777 ik/
- 删除 ik 分词器压缩包
rm ELK-IKv7.4.2.zip
6.4 检查 ik 分词器安装
- 进入到容器中
docker exec -it <容器 id> /bin/bash
- 查看 Elasticsearch 的插件
elasticsearch-plugin list
结果如下,说明 ik 分词器安装好了。是不是很简单。
ik

然后退出 Elasticsearch 容器,并重启 Elasticsearch 容器
exit
docker restart elasticsearch
6.5 使用 ik 中文分词器
ik 分词器有两种模式
-
智能分词模式 ( ik_smart )
-
最大组合分词模式 ( ik_max_word )
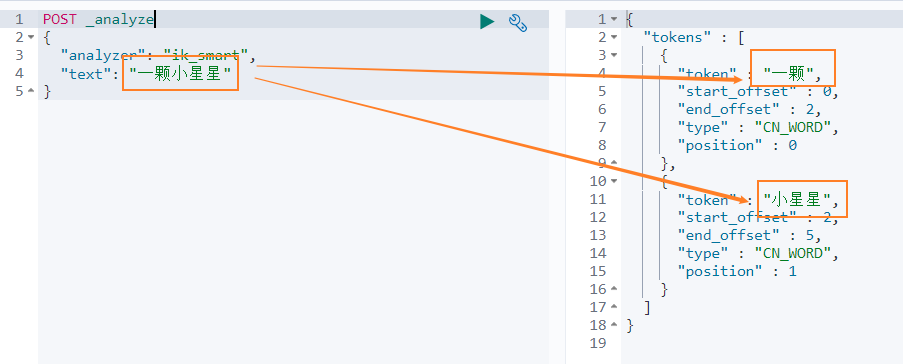
我们先看下 智能分词 模式的效果。比如对于 一颗小星星 进行中文分词,得到的两个词语:一颗、小星星
我们在 Dev Tools Console 输入如下查询
POST _analyze
{
"analyzer": "ik_smart",
"text": "一颗小星星"
}
得到如下结果,被分词为 一颗和小星星。
再来看下 最大组合分词模式。输入如下查询语句。
POST _analyze
{
"analyzer": "ik_max_word",
"text": "一颗小星星"
}
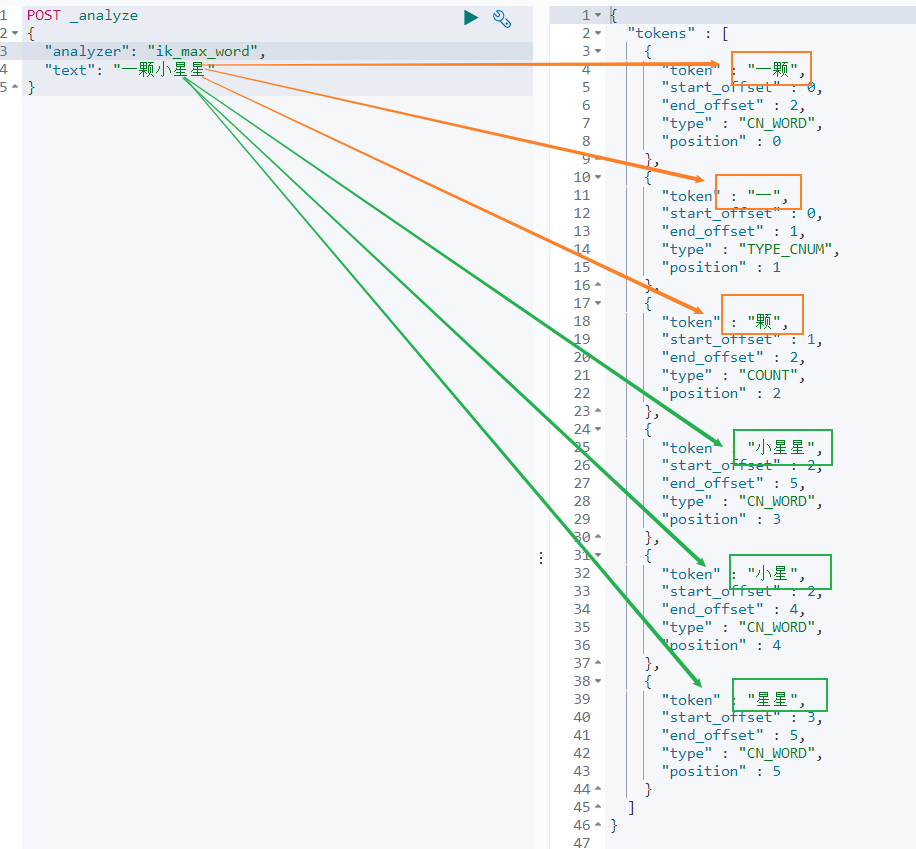
一颗小星星 被分成了 6 个词语:一颗、一、颗、小星星、小星、星星。
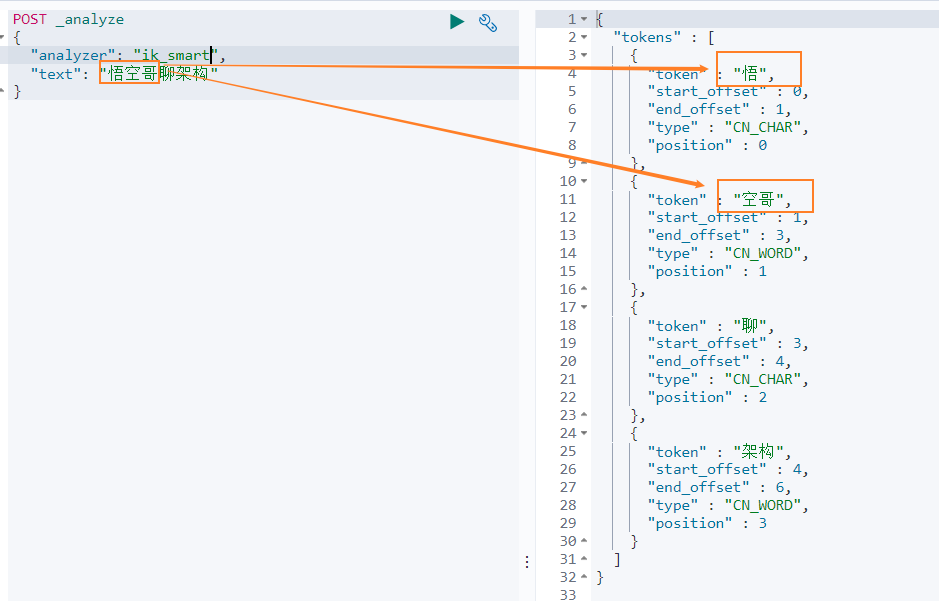
我们再来看下另外一个中文分词。比如搜索悟空哥聊架构,期望结果:悟空哥、聊、架构三个词语。
实际结果:悟、空哥、聊、架构四个词语。ik 分词器将悟空哥分词了,认为 空哥 是一个词语。所以需要让 ik 分词器知道 悟空哥 是一个词语,不需要拆分。那怎么办做呢?
6.5 自定义分词词库
6.5.1 自定义词库的方案
- 方案
新建一个词库文件,然后在 ik 分词器的配置文件中指定分词词库文件的路径。可以指定本地路径,也可以指定远程服务器文件路径。这里我们使用远程服务器文件的方案,因为这种方案可以支持热更新 ( 更新服务器文件,ik 分词词库也会重新加载 ) 。
- 修改配置文件
ik 分词器的配置文件在容器中的路径:
/usr/share/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml。
修改这个文件可以通过修改映射文件,文件路径:
/mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
编辑配置文件:
vim /mydata/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
配置文件内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
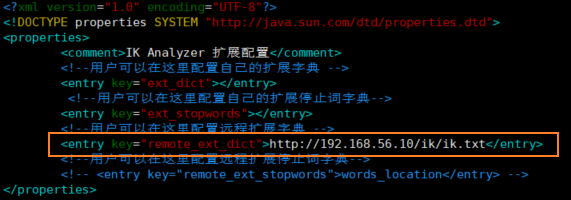
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
修改配置 remote_ext_dict 的属性值,指定一个 远程网站文件的路径,比如 http://www.xxx.com/ikwords.text。
这里我们可以自己搭建一套 nginx 环境,然后把 ikwords.text 放到 nginx 根目录。
6.5.2 搭建 nginx 环境
方案:首先获取 nginx 镜像,然后启动一个 nginx 容器,然后将 nginx 的配置文件拷贝到根目录,再删除原 nginx 容器,再用映射文件夹的方式来重新启动 nginx 容器。
- 通过 docker 容器安装 nginx 环境。
docker run -p 80:80 --name nginx -d nginx:1.10
- 拷贝 nginx 容器的配置文件到 mydata 目录的 conf 文件夹
cd /mydata
docker container cp nginx:/etc/nginx ./conf
- mydata 目录 里面创建 nginx 目录
mkdir nginx
- 移动 conf 文件夹到 nginx 映射文件夹
mv conf nginx/
- 终止并删除原 nginx 容器
docker stop nginx
docker rm <容器 id>
- 启动新的容器
docker run -p 80:80 --name nginx
-v /mydata/nginx/html:/usr/share/nginx/html
-v /mydata/nginx/logs:/var/log/nginx
-v /mydata/nginx/conf:/etc/nginx
-d nginx:1.10
- 访问 nginx 服务
192.168.56.10
报 403 Forbidden, nginx/1.10.3 则表示 nginx 服务正常启动。403 异常的原因是 nginx 服务下没有文件。
- nginx 目录新建一个 html 文件
cd /mydata/nginx/html
vim index.html
hello passjava
- 再次访问 nginx 服务
浏览器打印 hello passjava。说明访问 nginx 服务的页面没有问题。
- 创建 ik 分词词库文件
cd /mydata/nginx/html
mkdir ik
cd ik
vim ik.txt
填写 悟空哥,并保存文件。
- 访问词库文件
http://192.168.56.10/ik/ik.txt
浏览器会输出一串乱码,可以先忽略乱码问题。说明词库文件可以访问到。
- 修改 ik 分词器配置
cd /mydata/elasticsearch/plugins/ik/config
vim IKAnalyzer.cfg.xml
- 重启 elasticsearch 容器并设置每次重启机器后都启动 elasticsearch 容器。
docker restart elasticsearch
docker update elasticsearch --restart=always
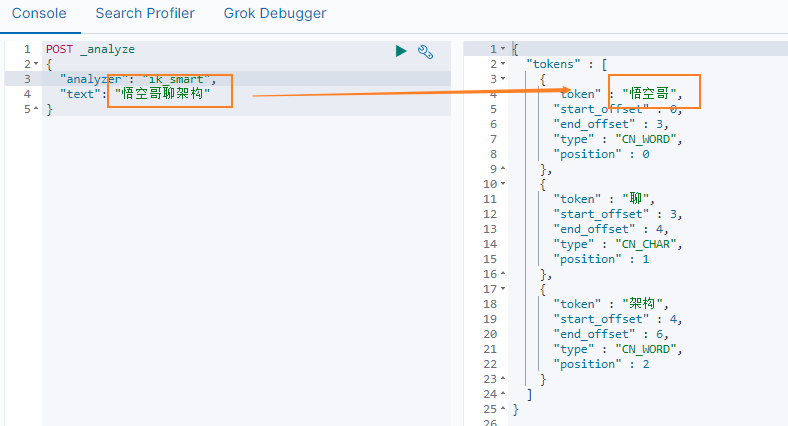
- 再次查询分词结果
可以看到 悟空哥聊架构 被拆分为 悟空哥、聊、架构 三个词语,说明自定义词库中的 悟空哥 有作用。
七、写在最后
中篇和下篇继续肝,加油冲呀!
-
中篇: 实战 ES 应用。
-
下篇: ES 的集群部署。
-
END -
你好,我是
悟空哥,「7年项目开发经验,全栈工程师,开发组长,超喜欢图解编程底层原理」。
我还手写了 2 个小程序,Java 刷题小程序,PMP 刷题小程序,点击我的公众号菜单打开!
另外有 111 本架构师资料以及 1000 道 Java 面试题,都整理成了PDF。
可以关注公众号 「悟空聊架构」 回复悟空领取优质资料。
「转发->在看->点赞->收藏->评论!!!」 是对我最大的支持!
《Java并发必知必会》系列:
1.反制面试官 | 14张原理图 | 再也不怕被问 volatile!
5.5000字 | 24张图带你彻底理解Java中的21种锁

我是悟空哥,努力变强,变身超级赛亚人!我们下期见!