推荐系统之余弦相似度的Spark实现
(1)原理分析
余弦相似度度量是相似度度量中最常用的度量关系,从程序分析中,
- 第一步是数据的输入,
- 其次是使用相似性度量公式
- 最后是对不同用户的递归计算。
本例子是基于欧几里得举例的相似度计算。
(2)源代码
1 package com.bigdata.demo 2 3 import org.apache.spark.{SparkContext, SparkConf} 4 5 /** 6 * Created by SimonsZhao on 3/29/2017. 7 */ 8 object CollaborativeFilteringSpark { 9 //1.设置环境变量 10 val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilteringSpark") 11 //2.实例化环境 12 val sc=new SparkContext(conf) 13 //3.设置用户 14 val users=sc.parallelize(Array("aaa","bbb","ccc","ddd","eee")) 15 //4.设置电影名 16 sc.parallelize(Array("smzdm","ylxb","znb","nhsc","fcwr")) 17 //5.使用一个source嵌套map作为姓名电影名和分值的存储 18 var source=Map[String,Map[String,Int]]() 19 //6.设置一个用以存放电影分的map 20 val filmSource =Map[String,Int]() 21 //7.设置电影评分 22 def getSource():Map[String,Map[String,Int]]={ 23 val user1FilmSource=Map("smzdm"->2,"ylxb"->3,"znb"->1,"nhsc"->0,"fcwr"->1) 24 val user2FilmSource=Map("smzdm"->1,"ylxb"->2,"znb"->2,"nhsc"->1,"fcwr"->4) 25 val user3FilmSource=Map("smzdm"->2,"ylxb"->1,"znb"->0,"nhsc"->1,"fcwr"->4) 26 val user4FilmSource=Map("smzdm"->3,"ylxb"->2,"znb"->0,"nhsc"->5,"fcwr"->3) 27 val user5FilmSource=Map("smzdm"->5,"ylxb"->3,"znb"->1,"nhsc"->1,"fcwr"->2) 28 //存储人的名字 29 source += ("aaa" -> user1FilmSource) 30 //存储人的名字 31 source += ("bbb" -> user2FilmSource) 32 //存储人的名字 33 source += ("ccc" -> user3FilmSource) 34 //存储人的名字 35 source += ("ddd" -> user4FilmSource) 36 //存储人的名字 37 source += ("eee" -> user5FilmSource) 38 //返回嵌套的map 39 source 40 } 41 //采用余弦相似度两两计算分值 42 def getCollaborateSource(user1:String,user2:String):Double={ 43 //获得第一个用户的评分 44 val user1FilmSource =source.get(user1).get.values.toVector 45 //获得第二个用户的评分 46 val user2FileSource=source.get(user2).get.values.toVector 47 //对公示分子部分进行计算 48 val member=user1FilmSource.zip(user2FileSource).map(d => d._1 *d._2).reduce(_+_).toDouble 49 //求解分母的第一个变量 50 val temp1=math.sqrt(user1FilmSource.map(num=>{math.pow(num,2)}).reduce(_+_)) 51 //求解分母第二个变量 52 val temp2=math.sqrt(user2FileSource.map(num=>{math.pow(num,2)}).reduce(_+_)) 53 //求出分母 54 val denominator=temp1*temp2 55 //求出分式的值 56 member/denominator 57 } 58 def main(args: Array[String]) { 59 //初始化分数 60 getSource() 61 //设定目标对象 62 val name="bbb" 63 //进行迭代计算 64 users.foreach(user=>{ 65 println(name+" 相对于"+user+"的相似性分数是:"+getCollaborateSource(name,user)) 66 }) 67 } 68 }
点击可复制代码


1 package com.bigdata.demo 2 3 import org.apache.spark.{SparkContext, SparkConf} 4 5 /** 6 * Created by SimonsZhao on 3/29/2017. 7 */ 8 object CollaborativeFilteringSpark { 9 //1.设置环境变量 10 val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilteringSpark") 11 //2.实例化环境 12 val sc=new SparkContext(conf) 13 //3.设置用户 14 val users=sc.parallelize(Array("aaa","bbb","ccc","ddd","eee")) 15 //4.设置电影名 16 sc.parallelize(Array("smzdm","ylxb","znb","nhsc","fcwr")) 17 //5.使用一个source嵌套map作为姓名电影名和分值的存储 18 var source=Map[String,Map[String,Int]]() 19 //6.设置一个用以存放电影分的map 20 val filmSource =Map[String,Int]() 21 //7.设置电影评分 22 def getSource():Map[String,Map[String,Int]]={ 23 val user1FilmSource=Map("smzdm"->2,"ylxb"->3,"znb"->1,"nhsc"->0,"fcwr"->1) 24 val user2FilmSource=Map("smzdm"->1,"ylxb"->2,"znb"->2,"nhsc"->1,"fcwr"->4) 25 val user3FilmSource=Map("smzdm"->2,"ylxb"->1,"znb"->0,"nhsc"->1,"fcwr"->4) 26 val user4FilmSource=Map("smzdm"->3,"ylxb"->2,"znb"->0,"nhsc"->5,"fcwr"->3) 27 val user5FilmSource=Map("smzdm"->5,"ylxb"->3,"znb"->1,"nhsc"->1,"fcwr"->2) 28 //存储人的名字 29 source += ("aaa" -> user1FilmSource) 30 //存储人的名字 31 source += ("bbb" -> user2FilmSource) 32 //存储人的名字 33 source += ("ccc" -> user3FilmSource) 34 //存储人的名字 35 source += ("ddd" -> user4FilmSource) 36 //存储人的名字 37 source += ("eee" -> user5FilmSource) 38 //返回嵌套的map 39 source 40 } 41 //采用余弦相似度两两计算分值 42 def getCollaborateSource(user1:String,user2:String):Double={ 43 //获得第一个用户的评分 44 val user1FilmSource =source.get(user1).get.values.toVector 45 //获得第二个用户的评分 46 val user2FileSource=source.get(user2).get.values.toVector 47 //对公示分子部分进行计算 48 val member=user1FilmSource.zip(user2FileSource).map(d => d._1 *d._2).reduce(_+_).toDouble 49 //求解分母的第一个变量 50 val temp1=math.sqrt(user1FilmSource.map(num=>{math.pow(num,2)}).reduce(_+_)) 51 //求解分母第二个变量 52 val temp2=math.sqrt(user2FileSource.map(num=>{math.pow(num,2)}).reduce(_+_)) 53 //求出分母 54 val denominator=temp1*temp2 55 //求出分式的值 56 member/denominator 57 } 58 def main(args: Array[String]) { 59 //初始化分数 60 getSource() 61 //设定目标对象 62 val name="bbb" 63 //进行迭代计算 64 users.foreach(user=>{ 65 println(name+" 相对于"+user+"的相似性分数是:"+getCollaborateSource(name,user)) 66 }) 67 } 68 }
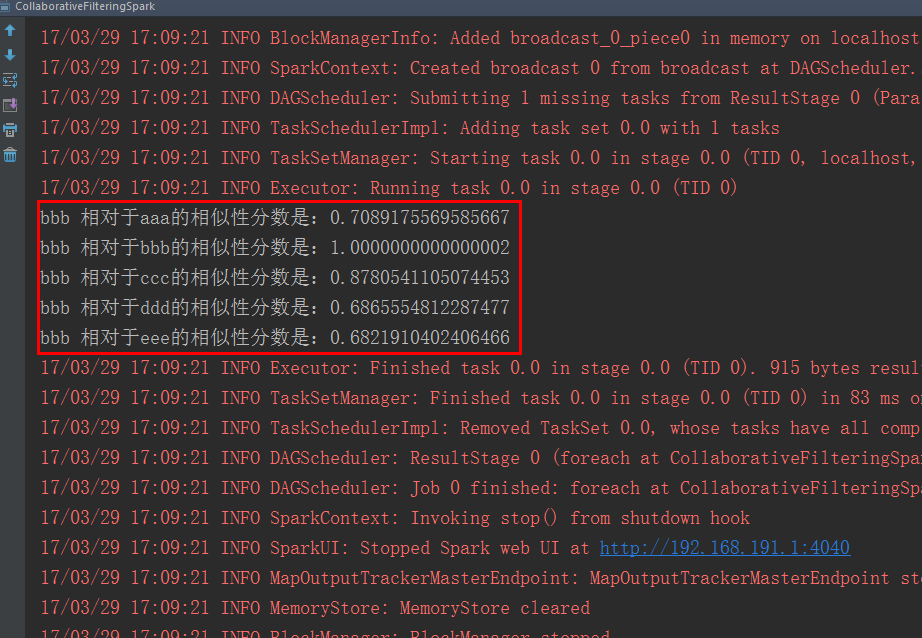
(3)结果分析