简介
其实我不是啥正经人,错了,不是啥正经程序员,所能想到的估计也就码农一级吧,高级程序员,搞什么算法,什么人工智能,大数据计算…………离我还太遥远。
但是这并不妨碍我继续学习,继续写垃圾小程序。
反正我做的小程序,也就是把人从重复的劳动中解脱出来。用电脑代替人脑记忆那些枯燥的繁琐的数据。用电脑来查询记忆的数据。人脑的神经网络是比计算机查找的快。随便吧,还搞不到那个层次。先用电脑记录查询吧。
虽然python学习中已经学习了读写文件,在文件中查找,不过那都面向少量数据,更别提什么大数据了。几万行数据,你试试,搞起来累死了。新武器,数据库。
数据库:
抄吧
本词条由“科普中国”百科科学词条编写与应用工作项目 审核 。
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它产生于距今六十多年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。数据库有很多种类型,从最简单的存储有各种数据的表格到能够进行海量数据存储的大型数据库系统都在各个方面得到了广泛的应用。
在信息化社会,充分有效地管理和利用各类信息资源,是进行科学研究和决策管理的前提条件。数据库技术是管理信息系统、办公自动化系统、决策支持系统等各类信息系统的核心部分,是进行科学研究和决策管理的重要技术手段。
就是存数据,查数据,改数据…………的工具集合。
ORM:
继续抄
对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
也就是不用你管数据库怎么样操作,怎么处理了,把数据库变成了你程序当中的对象,你就像操作对象一样来操作数据库。降低了程序员的学习成本,你不需要额外再去学数据库了。简单学习一下数据库对象的操作就可以使用数据库了。
sqlalchemy:
还得抄
python中最出名的,最好用的,最…………反正python中,涉及数据库的,我都用它了。
alembic:
不抄我怎么解释
通常我们会将我们的代码放入到某个VCS(版本控制系统)中,进行可追溯的版本管理。一个项目除了代码,通常还会有一个数据库,这个数据库可能会随着项目的演进发生变化,甚至需要可以回滚到过去的某个状态,于是一些工具将数据库的版本化也纳入了管理。
Alembic 是 Sqlalchemy 的作者实现的一个数据库版本化管理工具,它可以对基于Sqlalchemy的Model与数据库之间的历史关系进行版本化的维护。
随着软件的开发,功能的增加,方向的调整,数据库的结构也会跟着变化,那么数据库结构怎么管理呢?手动管理,实在不是程序员的办法,alembic就是为了自动化处理数据库结构的工具。会随着程序中对数据库对象的定义,半自动的修改你的数据库结构。
一:安装依赖
在python项目的虚拟环境中安装sqlalchemy alembic 和 MySQL-connector-python
二:创建数据库连接
在项目根目录增加文件config.py,项目配置文件。
本例只写入了数据库配置。以后cookie,session,加密的盐,都写这里吧。
config.py
from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session, sessionmaker from sqlalchemy.ext.declarative import declarative_base engine = create_engine('mysql+mysqlconnector://plan:plan@mysql/plan', convert_unicode=True) db_session = scoped_session(sessionmaker(autocommit=False, autoflush=False, bind=engine)) Base = declarative_base() Base.query = db_session.query_property()
这个配置文件使用了MySQL-connector-python库连接第一篇文章写的mariadb数据库。
连接参数是'mysql+mysqlconnector://plan:plan@mysql/plan'
三:创建models
在项目根目录创建目录models,并在其中创建models.py文件。
models目录是模型主目录,公共部分模型,都放这里。
models.py就是模型了。
在app/app01目录下创建app01_models.py,app01的私有models,就定义在这里了。
结构如下:
. ├── app │ ├── alembic.ini │ ├── app │ │ ├── app01 │ │ │ ├── app01_models.py #新加,app01的私有models │ │ │ └── views.py │ │ ├── app02 │ │ │ └── views.py │ │ └── main │ │ └── views.py │ ├── build_requirements.py │ ├── config.py │ ├── main.py │ ├── migrate │ │ ├── env.py │ │ ├── README │ │ ├── script.py.mako │ │ └── versions │ ├── models #新加目录 │ │ └── models.py #公共models │ └── requirements.txt ├── dockerfile ├── list.txt └── rebuild.sh
/models/models.py
from config import Base from sqlalchemy import Column, Integer, String class User(Base): __tablename__ = 'public' id = Column(Integer, primary_key=True) public_name = Column(String(50)) public_email = Column(String(120)) def __init__(self, name=None, email=None): self.public_name = name self.public_email = email def __repr__(self): return '<User %r>' % (self.public_name)
/app/app01/app01_models.py
from config import Base from sqlalchemy import Column, Integer, String class app01(Base): __tablename__ = 'private' id = Column(Integer, primary_key=True) private_name = Column(String(50)) private_email = Column(String(120)) def __init__(self, name=None, email=None): self.private_name = name self.private_email = email def __repr__(self): return '<User %r>' % (self.private_name)
四:创建alembic扩展工具
在pycharm中用扩展工具来构建alembic的3条命令。
alembic init migrate 创建alembic目录结构
alembic revision --autogenerate 生成alembic升级脚本
alembic upgrade head 升级数据库结构到最新版
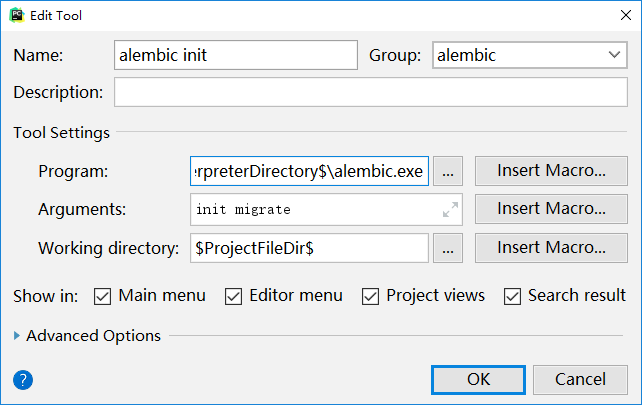
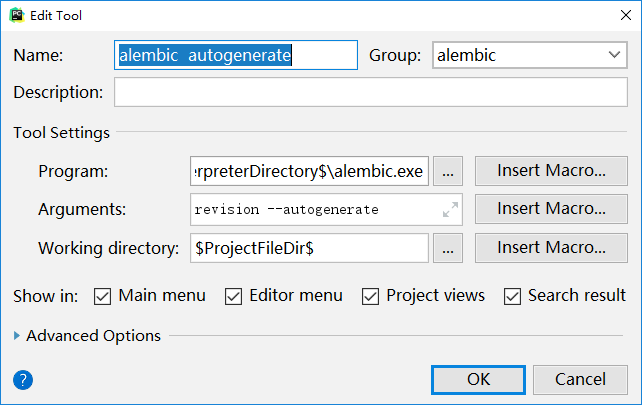
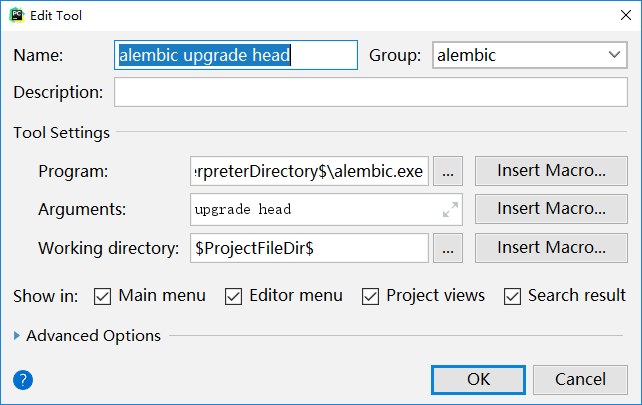
Program:$PyInterpreterDirectory$alembic.exe这行比较长,抓图看不清
五:创建alembic目录结构
用刚才配置的扩展工具执行 init也可以。
直接执行命令 alembic init migrate 也可以。
会在项目目录下生成一个目录 migrage 一个配置文件 alembic.ini
生成结果如下:
. ├── app │ ├── alembic.ini #自动增加文件,需配置 │ ├── app │ │ ├── app01 │ │ │ ├── app01_models.py │ │ │ └── views.py │ │ ├── app02 │ │ │ └── views.py │ │ └── main │ │ └── views.py │ ├── build_requirements.py │ ├── config.py │ ├── main.py │ ├── migrate #自动增加目录 │ │ ├── env.py #需修改 │ │ ├── README │ │ ├── script.py.mako │ │ └── versions │ └── requirements.txt ├── dockerfile ├── list.txt └── rebuild.sh
六:配置alembic
上一节已经标明了,需要修改配置的有两个文件。
alembic.ini,其中配置数据库连接参数。
修改这行:
sqlalchemy.url = driver://user:pass@localhost/dbname
改为我们的数据连接参数:
sqlalchemy.url = mysql+mysqlconnector://plan:plan@mysql/plan
env.py,其中配置models。
修改这行:
target_metadata = None
改为:
import os import sys sys.path.append(os.path.dirname(os.path.abspath(__file__)) + "/../") from models import models target_metadata = models.Base.metadata
其实我也不是很明白,大概就是引入路径的问题,所以加了sys.path.append
七:生成升级脚本并升级数据库
alembic revision --autogenerate 生成alembic升级脚本
alembic upgrade head 升级数据库结构到最新版
执行这两个命令,或用扩展工具的图形菜单。
八:检查数据库结构
跟随第一张最后一节的测试。
点开数据库,就能看到有表了。
如下:
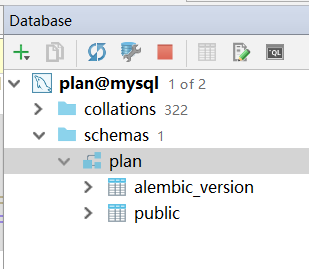
哈哈,两个对象结构,怎么只有一个public,private不见了。
专门留下来,没创建。
alembic_version,是alembic自动创建,用来控制版本的,不要动就好了。
九:数据库版本控制
来,改一下alembic配置models的地方。
import os import sys sys.path.append(os.path.dirname(os.path.abspath(__file__)) + "/../") from models import models from app.app01 import app01_models #此行增加 target_metadata = models.Base.metadata
由于对象public和private都是由Base派生的,所以,只要target_metadata = models.Base.metadata,一遍就可以了。
部分教程中写的是target_metadata = [models.Base.metadata,app01_models.Base.metadata],不知道怎么用。
可能是连接多数据库时候用的。以后需要分库的时候再说吧。看不懂的请忽略。
再来一遍生成版本控制脚本和升级数据库结构。
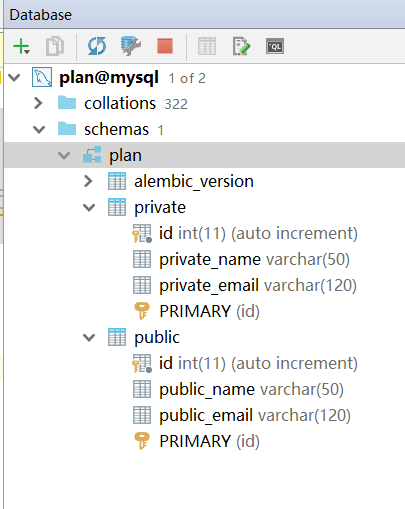
private也出来了。
这就是自动化的数据库结构版本控制。
十:结合docker
看这个镜像作者的使用说明:
Custom /app/prestart.sh
If you need to run anything before starting the app, you can add a file prestart.sh to the directory /app. The image will automatically detect and run it before starting everything.
For example, if you want to add Alembic SQL migrations (with SQLALchemy), you could create a ./app/prestart.sh file in your code directory (that will be copied by your Dockerfile) with:
#! /usr/bin/env bash
# Let the DB start
sleep 10;
# Run migrations
alembic upgrade head
and it would wait 10 seconds to give the database some time to start and then run that alembic command.
If you need to run a Python script before starting the app, you could make the /app/prestart.sh file run your Python script, with something like:
#! /usr/bin/env bash
# Run custom Python script before starting
python /app/my_custom_prestart_script.y
Note: The image uses source to run the script, so for example, environment variables would persist. If you don't understand the previous sentence, you probably don't need it.
你可以在app启动前,执行一些命令,那么正好,我们可以执行数据库版本升级。
在app目录下,创建prestart.sh
#! /usr/bin/env bash # Let the DB start sleep 10; # Run migrations alembic upgrade head
好了,随便改改你的数据库结构。只生成一下升级脚本,不用执行到服务器。
重建镜像,它在启动的时候就会自动帮你升级数据库版本到最新版本了。
我使用这个是因为,我服务器5点自动重启,然后就连不上数据库了。重启Flask这个镜像,一切正常,手动重启服务器,居然也都没事。
这个升级数据库脚本,正好在启动APP前sleep 10秒。谁知道是不是因为启动容器的顺序的关系呢?这里sleep 10秒,也可以避免这个问题。
该文件请在linux下创建。
或者我写进dockerfile。
FROM tiangolo/uwsgi-nginx-flask:python3.6-alpine3.7 MAINTAINER jackadam<jackadam@sina.com> #变更源 # 安装包源切到中科大, 国内访问加速 RUN { echo 'http://mirrors.ustc.edu.cn/alpine/v3.7/main'; echo 'http://mirrors.ustc.edu.cn/alpine/v3.7/community'; echo 'http://mirrors.ustc.edu.cn/alpine/edge/main'; echo 'http://mirrors.ustc.edu.cn/alpine/edge/community'; echo 'http://mirrors.ustc.edu.cn/alpine/edge/testing'; } > /etc/apk/repositories && # 设置默认时区为亚洲/上海 (没有北京可选) apk add --no-cache --upgrade apk-tools && apk add --no-cache tzdata && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone && apk del tzdata #升级pip RUN pip3 install --upgrade pip #复制依赖包列表 COPY ./app/requirements.txt /app/requirements.txt #安装依赖包 RUN pip3 install -i https://pypi.doubanio.com/simple -r /app/requirements.txt #创建prestart.sh RUN { echo '#! /usr/bin/env bash'; echo '# Let the DB start'; echo 'sleep 10;'; echo '# Run migrations'; echo 'alembic upgrade head'; } > /app/prestart.sh #复制flask源码 COPY ./app /app
结语
到此,我们已经创建了数据库,新建flask项目,配置同步到服务器,服务器自动更新docker镜像,用sqlalchemy连接数据库,用alembic控制数据库版本。
那么程序的版本怎么控制?用git啊。写不写git呢?