参考:
http://www.rabbitmq.com/tutorials/tutorial-one-python.html
http://www.rabbitmq.com/tutorials/tutorial-three-python.html
1 基本
RabbitMQ是一个消息中间件(message broker),它接受和转发消息。类似邮局的功能。
使用的术语:
Procucer-发送消息的就是生产者。
Queue-消息存储在队列中,队列就是一个大型的消息缓存。多个生产者可以将消息发送给一个队列,多个消费者可以尝试从一个队列接受数据。
Consume-消费者是等待接受消息的程序
note:producer,consumer,broker在绝大部分应用中,分布在不同的主机上。
2 第一个程序-Hello World

生产者向队列‘hello’发送消息,生产者从队列接受消息。
中间的box是queue--维持在消费者一端的消息缓存。
2.1 send.py
import pika
#向一个指定地址上的broker创立连接
conncetion = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = conncetion.channel()
#发送消息之前需要确认接收端队列存在
#如果发送数据到一个不存在的位置,RabbitMQ会丢掉消息
#在这里我们声明一个hello队列来投递消息
channel.queue_declare('hello')
#现在发送一个消息到hello这个队列。
#在RabbitMQ中,一个消息无法直接发送带队列,而是需要通过一个exchange。
#目前只需要知道如何使用一个默认的由一个空字符串认证的exchange,它允许指定消息要发到哪个队列
#队列名在route-key参数中指定
channel.basic_publish(exchange='',routing_key='hello',body='Hello World')
#退出程序之前需要确认网络缓存被清空,并且消息被投递到RabbitMQ。可以优雅地关闭连接
conncetion.close()
2.2 receive.py
import pika
#连接到RabbitMQ Server
conncetion = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = conncetion.channel()
#确认接收端队列存在
channel.queue_declare('hello')
#从队列接受消息较为复杂,它通过向队列订阅一个回调函数来工作
#每当我们接受一个消息,pika库会调用回调函数
#在这个case中,函数会打印消息内容
def callback(ch, method, properties, body):
print("Received %r" % body)
#告知RabbitMQ,指定的回调函数要从hello队列中接受消息
#如果订阅的queue不存在,这一步会失败
channel.basic_consume(callback,queue='hello',no_ack=True)
#这个函数会一直等待数据,并在需要时运行回调函数
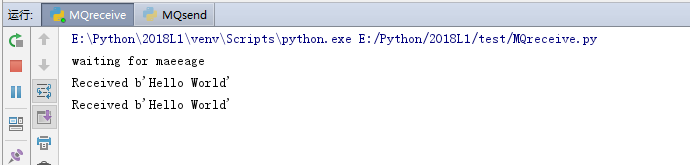
print('waiting for maeeage')
channel.start_consuming()
2.3 运行程序
当消费者启动,就会开始等待从hello队列接受消息,并且循环接受。每当队列中产生数据,就会到达消费者。
2.4 消费者轮训机制
如果从同一个队列获取数据的消费者有多个,那就会默认使用轮训机制获取数据。

2.5 no_ack参数
在应用场景中,生产者相当于客户端,消费者相当于服务端。生产者使用basix_publish函数发送数据到队列,然后消费者使用basic_consume从队列中获取数据,并调用回调函数对数据进行处理。
在流程上,生产者发送消息到队列,然后消费者使用回调函数处理完后,默认情况下,在basic_consume函数中,no_ack=False,就是会向生产者发送清楚处理完成确认消息。生产者收到该消息,就会删除队列中的消息。
如果消费者在处理过程中宕机,RabbitMQ检测到sokcet连接断了,就会把消息发到下一个轮训点。
在第二大点的案例中,加上了no_ack=True,就是消费者不会向生产者发送处理完确认信息。这样,如果消费者在处理过程中宕机,生产者也会删除队列中的消息。这适合于不看重处理结果的请求。
2.6 持久化队列
当RabbitMQ服务宕机,队列信息就会丢失,在声明队列时加上持久化参数,会把队列保存(里面的消息依然不会保存)
channel.queue_declare('hello',durable=True)
会把消息也持久化,需要在生产者的basic_publish函数里加一个参数
channel.basic_publish(exchange='',routing_key='hello',body='Hello World',
properties=pika.BasicProperties(delivery_mode=2)
)
2.7 channel.basic_qos(prefetch_count=1)
3 Publish/Subscribe
在RabbitMQ的消息模型中,核心特征就是,生产者永远不会直接向队列发送任何消息,甚至大部分时候生产者都不知道一个消息是否会被投递到队列中。
生产者只能把消息发给exchange。exchange一面从生产者接受消息,另一面把消息推送给队列。exchange必须准确知道该如何处理所收到的消息。exchange type就是来定义处理方式的规则。
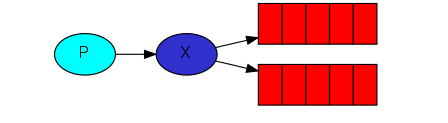
在第二大点,exchange='',这是默认的exchange,会按照route_key里的queue名去发送消息(如果该queue存在的话)
fanout exchange很简单,就是把自己从生产者收到的所有消息广播给它绑定的所有队列。
3.1 publish.py
import pika
message='i am jabbok'
connect = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connect.channel()
#声明一个fanout的exchange类型,取名‘logs’
#exchange会向所有与自己绑定的queue广播自己收到的消息
channel.exchange_declare(exchange='logs',exchange_type='fanout')
#当exchange='',会根据route_key的值去查找队列
#而fanout类型的exchange,是向所有绑定的队列发送消息。所以route_key=''
channel.basic_publish(exchange='logs',routing_key='',body=message)
channel.close()
3.2 subscribe.py
import pika,time
conncetion = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = conncetion.channel()
channel.exchange_declare(exchange='logs',exchange_type='fanout')
#在本例中,只需要当前的消息,所以每次连接队列都会清空
#为此创建的队列使用的是随机名,所以队列声明里不需要queue参数
#加上exclusive唯一参数,与该随机名queue连接的生产者断开连接,该queue删除
#result.method.queue包含一个随机的队列名
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
#绑定exchange和队列,就是告诉exchange把消息发给哪个queue
#这里queue是个随机名
channel.queue_bind(exchange='logs',queue=queue_name)
def callback(ch, method, properties, body):
print("Received %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
print('waiting for maeeage')
channel.start_consuming()
3.3 运行
消费发布后,如果对端没有订阅者,队列马上删除。这时再运行订阅,也收不到消息。
在第二大点,同一个消息,消费者是轮训接受。但在订阅发布模型中,所有订阅者都会收到同一个消息。