我们有时候会不会有这种困扰: 在网上看到一个很好看的视频想下载保存下来,却发现没有下载选项,会不会觉得很失望. 看了这篇博客后,保管能减少你这样的烦恼.
我们利用HTTP协议和HttpURLConnection完成网上资源的爬取,这样不用网站提供下载选项我们也能拿到我们自己想要的资源 甚至有些收费的视频也能弄到手哦. 多学点技术,就可以少花点钱嘛
废话不多说,上代码
/**
* 网络文件下载器
* @author 雷神
*
*/
public class FileDownloader {
public void download(String url,File file) throws MalformedURLException, FileNotFoundException {
URL urlObj = new URL(url);
//获取文件名称
String path = urlObj.getPath();
int index = path.lastIndexOf("/");
String fname = path.substring(index+1);
//文件名组合目录获得要下载的文件名,创建输出流
File files = new File(file,fname);
OutputStream os = new FileOutputStream(files);
System.out.println("开始下载...");
new Thread(()->{
HttpURLConnection conn = null;
InputStream is = null;
//打开连接
try {
conn = (HttpURLConnection) urlObj.openConnection();
conn.setRequestMethod("GET");
int stateCode = conn.getResponseCode();
if(stateCode == HttpURLConnection.HTTP_OK){
is = conn.getInputStream();
byte[] b = new byte[1024];
int len = 0;
while((len = is.read(b))!= -1){
os.write(b, 0, len);
}
System.out.println("下载完成");
}
} catch (Exception e) {
e.printStackTrace();
}finally{
try {
if(os != null){
os.close();
}
if(is != null){
is.close();
}
if(conn != null){
conn.disconnect();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
public static void main(String[] args) throws IOException, FileNotFoundException {
//获得网上资源链接
String url = "https://img2.huashi6.com/images/resource/2015/07/15/51430h533p0.png?imageView2/3/q/100/interlace/1/w/448/h/320";
//传入资源和要目标目录
new FileDownloader().download(url,new File("D:/老婆们"));
}
}
开始代码分析:
谈到网上爬取,就不得不说到URL类, URL又称之为统一资源定位器,一般用于表示一个网络地址(本地网,外部网络),通过该地址可以定位到网络中的资源
一个URL地址通常由以下几个部分构成:
-
协议(双方约定的通信标准: http:// ftp:// jdbc:mysql://)
-
主机地址或域名(资源所在服务器地址:softeem.com 119.231.8.9 192.168.0.1)
-
端口(服务器中指定服务对外数据交换接口,唯一:80 3306)
-
-
查询路径(?之后的内容:page=1 user=root&password=123456)
而我们现在需要的就是其中的请求资源地址 通过URL类中的getPath()方法可以获得不含查询路径的资源地址
在网页上按f12 点击network选项卡 选择你想要的文件,将RequeryURL中的地址复制下来,通过此地址获得一个URL对象
调用getPath()方法得到一个类似这样的资源路径:
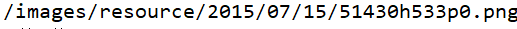
我们要下载此文件肯定要得到它的文件名,所以我们取得最后"/"的索引 通过subString()方法截取"/"之后的所有字符串,得到文件名 然后通过传过来的父目录,创建一个新的File对象 获得它的文件输出流. (这样准备工作都做好,我们可以准备读取网上的资源了)
这里我们为了防止文件读取异常 可能会阻塞了其他功能的执行 我们建立了一个线程,如果只需要下载文件,那么线程可以不用建立
为了下载资源 我们首先要做的是打开一个我们主机和网络的链接 : 通过OpenConnection()实现,获得链接后,我们需要设置我们的请求头 setRequestMethod("GET"); GET代表我们需要向该网址获得资源
接着我们需要判断该网页的状态码 其实在我们按f12的时候上面就已经显示状态码了,调用getResponseCode()方法获得状态码,状态码200代表请求成功
所以当我们获得的状态码等于200时 就可以读取并下载文件了
最后通过getInputStream()方法获得目标文件的输入流,接着用我们早已准备好的文件输出流,对目标文件进行循环读取写入. 这样网上的资源就能传到我们指定的目录了!!!!
其实思路很简单 主要就是对HttpConnection和URL类中的方法掉用,看了这篇博客之后 我相信你可以在网上白嫖资源了哈哈哈
你学到东西了吗