本文先简要介绍了AliSQL以及其开源背景,重点说明了AliSQL已开源的功能,包括Sequence Engine、TokuDB引擎支持和秒杀优化等,最后对AliSQL用户ISSUE和典型问题作了解答。
在2017在线技术峰会“阿里开源项目最佳实践”上,阿里云数据库内核专家赵建伟(冷香)为大家带来了“AliSQL开源功能特性”的演讲。本文先简要介绍了AliSQL以及其开源背景,重点说明了AliSQL已开源的功能,包括Sequence Engine、TokuDB引擎支持和秒杀优化等,最后对AliSQL用户ISSUE和典型问题作了解答。
3月1号下午,云栖社区将迎来2017在线技术峰会——“阿里开源项目最佳实践”。来自淘宝、天猫、阿里云、蚂蚁金服的8位项目核心成员将现场剖析阿里开源项目背后的技术实践,分享开源经验。其中,阿里云数据库内核专家赵建伟(冷香)为大家带来了“AliSQL开源功能特性”的演讲。本文先简要介绍了AliSQL以及其开源背景,重点说明了AliSQL已开源的功能,包括Sequence Engine、TokuDB引擎支持和秒杀优化等,最后对AliSQL用户ISSUE和典型问题作了解答。
以下是精彩内容整理:
AliSQL是基于MySQL官方版本的一个分支,由阿里云数据库团队维护,目前也应用于阿里巴巴集团业务以及阿里云数据库服务。该版本在社区版的基础上做了大量的性能与功能的优化改进,增加更多监控指标,并针对电商秒杀、物联网大数据压缩、金融数据安全等场景提供个性化的解决方案。在通用基准测试场景下,AliSQL 版本比 MySQL 官方版本有着 70% 的性能提升;在秒杀场景下,性能提升 100 倍。
AliSQL简介
AliSQL 于2016年10月份正式开源,我们也同步了github的开源地址:
https://github.com/alibaba/AliSQL,也得到了数据库相关的开发人员或DBA的关注,线上也收到了1700多个star。
按照内部制定的节奏,我们希望开源的AliSQL能持续地保持活跃,所以在主页上可以看到Release Notes自9月15号以来,一直不断地更新,Release Notes中有详细的本次发布的相关内容、使用方法和注意问题, 4月1日我们也将有重要的features发布。
AliSQL 也在主页提供必要的信息。最初的基础版本希望领先于官方版本,以及在性能上有质的飞跃,希望在特定场景下我们是遥遥领先的,所以我们给出了benchmark测试样例,在特定场景下有一些特定的优化,比如淘宝秒杀,我们专门做了benchmark,相对于其它分支有很大提升;16年11月份,我们合并了ToKuDB引擎,AliSQL以及官方提供的RDS上都是支持ToKuDB引擎的,ToKuDB引擎对于大数据、物联网等数据量大的场景下,会有很大的压缩比,所以在特定场景下ToKuDB的支持也做了配套工具的改良,如AliSQLBackup,多引擎支持上,我们希望对用户是透明的,也开放出物理备份的工具在github上;我们也提供DOC文档,其中Sequence Engine这个feature,在官方和业界MySQL分支上都还没有这个功能,我们提供从设计到语法到使用配套工具,以及非常详细的中英文文档,用户可以在主页上看到一级的重要链接,对大家使用AliSQL有一定帮助。
AliSQL开源背景
AliSQL并不是一个从零开始的项目,它起于开源,汲取社区红利,拥抱开源,促进社区发展。
AliSQL社区背景是基于官方大版本(MySQL & MariaDB),紧跟小版本,汲取不同开源分支(Percona,MariaDB)技术红利。集团背景是基于Alibaba集团业务进行性能的改进。
AliSQL已开源功能介绍
Sequence Engine
最初想法是在集团大范围使用MySQL之前,使用Oracle时大量使用Sequence,Sequence用来生成单调的文件,文件又被业务方进行包装加上日期或用户标识,便于进行天然用户维度的分库分表。这样大范围推广MySQL时,我们发现使用上不舒服的地方,如果想定制化递增的补偿等,相对于Orcale或Pg提供的Sequence有一些不足,基于此,我们在MySQL上移植Sequence特性,希望在语法上兼容到其它相关数据库。

我们提供的语法基本和Orcale类似,在获取MAXVALUE提供两个语法,一是SELECT FROM sequence,一是SELECT FOR sequence,FROM子句希望兼容到现有MySQL方法,FOR获取方法同时也兼容了SQLSERVER的方法,我们先行在这部分做了兼容和支持,现在AliSQL可以用SELECT MAXVALUE FOR sequence获取下一个值,每一次都会迭代步长,如果用SELECT MAXVALUE FROM sequence,获得的是定义的数据,本身sequence在AliSQL中提供这样的语法,在设计阶段基于sequence engine实现语法,sequence本身设计是通过sequence handler来访问。数据存储是以一张二维表的方式,所有属性保存在一行上,sequeence初始化是,先创建一张表,再插入一条记录,如果在create sequence中设置了cache,我们会在sequence handler保留cache,从sequence获取nextvalue时,只需迭代cache里面的值就可以了,不需要访问sequence handler底层基表,每当迭代nextvalue会有cache用完时,会面临sequence的更新,SELECT语句内部已经变成update语句,另外,sequence获取的值是不允许回滚的,所以我们开启了Autonomous transaction,我们也将sequence的逻辑备份更改成create table+insert语法。
TokuDB引擎支持
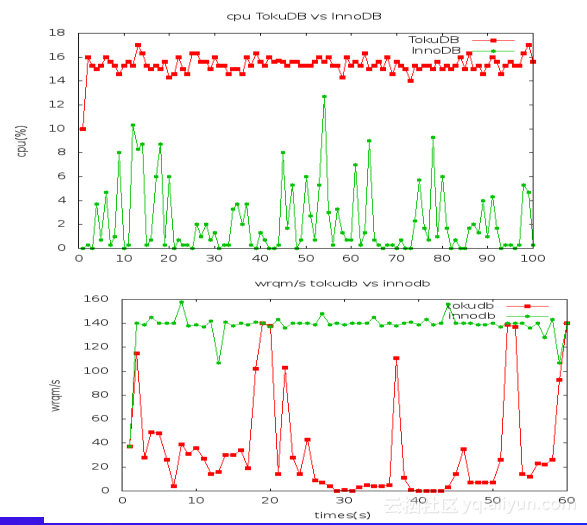
TokuDB引擎是在10月份版本释放出来的,在特定场景下可以有非常高的压缩比,有一些单机数据库在云上的客户,数据增长飞快,我们也希望在有限资源下尽量减少分库分表的需求,不断地压榨单机所能提供的资源;异步写、Sata 盘亲合,吞吐量很高;事务 ACID 完整支持,并没有牺牲任何事物特性;支持Secondary Clustering Index,在innoDB或其它树形结构上,对二级索引使用上,如果查询牵涉到二级索引以外的字段需要回表,如果主表与二级索引顺序反差比较大,回表就变成非常离散的图,为了减少离散图的情况,在TokuDB树形结构上支持cluster。
秒杀优化
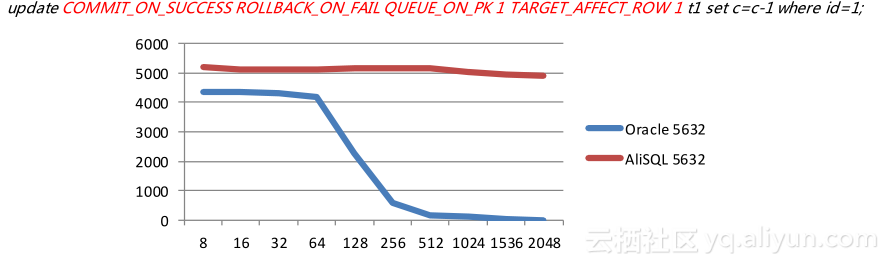
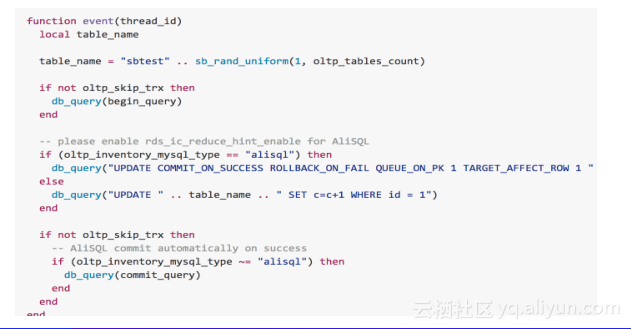
秒杀减库存并没有并行性可言(维护事务特性的情况下),10w的集中库存放到1s内减完是不现实的,应用服务器的反应是增加连接,大量的请求导致CPU无法调度,当数据库请求越来越慢时,应用服务器的线程会被耗尽,请求如果满足不了,会增加更多的数据库连接,这就是常说的雪崩效应,雪崩是没有办法缓解的,如图,当请求到2000量级时,数据库基本没有办法响应。针对这个情况,我们做了排队机制,当绵羊并发性可言时就不要消耗任何CPU等资源,在server上进行排队,排队只消耗内存,保证数据库请求到达率很高的情况下还有比较稳定的响应跟吞吐量。
TABLE/INDEX STATISTICS
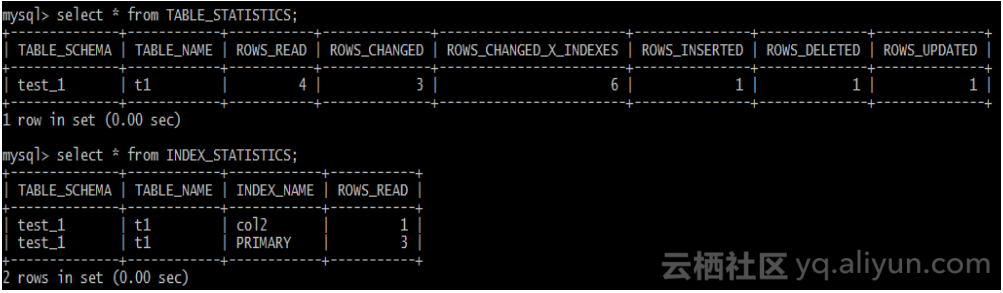
我们还增加了一些统计信息:
- Table的统计: 核心业务的读写比例如何,后期的扩展性是读写分离,还是水平拆分哪个更适合,基于数据分析业务模型,在架构上做出数据库规划,在容量提升过程中是非常好的数据指导。
- Index的统计: 索引使用的频率和效率,哪些索引根本没有使用, 可以drop掉。
Persistent AUTO_INCREMENT
在自增组件上,我们也做了feature,自增组件维持内存的值,获取值时会在内存中作计算,得到下一个值,插入时以此值插入到数据库当中。初始化过程是逻辑的初始化,数据库在这个表启动时初始化Table对象时,从表中选择MAX ID作为当前值,每次启动都会从表中获取当前最大值作为当前内存基准值使用,在历史数据归档导致数据冲突的背景下,我们提供了innodb_autoinc_persistent和innodb_autoinc_persistent_interval两个参数配置,每次变更的AUTO_INCREMENT进行一次持久化,持久化位置为root page PAGE_MAX_TRX_ID官方保留位置,目前已经合并到mariaDB。
Semisync优化
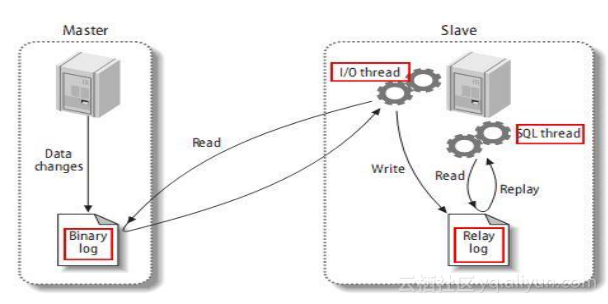
Semisync希望在主备部署的过程中,如果主库提交时数据库写入日志能够传输到备库,传完返回ACK在进行提交,保证主库数据的持久化及时传入到备库。我们做了Semisync静态编译优化,也做了LOCK_log锁优化(LOCK_end_position)。
表级别并行复制
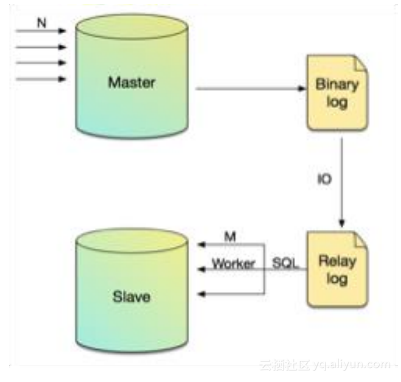
我们也在AliSQL开源了表级别的并行复制,对DBA来说,备库delay是很困扰的问题,影响数据库安全和恢复时间等。我们在官方SCHEMA级别并行复制基础上,提供了TABLE级别的并行复制,并不须要求是不同数据库,只要是不同的表,就可以做到并行复制。
IO限速
IO限速提供了以下两个信息:
- 统计信息:Logical_read、Physical_sync_read和Physical_async_read,可以对当前SQL执行过程中产生多少读取、IO操作和逻辑操作有比较直观的、可量化的信息;
- SQL 物理IO限制:“Set rds_sql_max_IOPS= 100;”,可以达到当前执行的100/S IOPS。
动态加字段(next release)
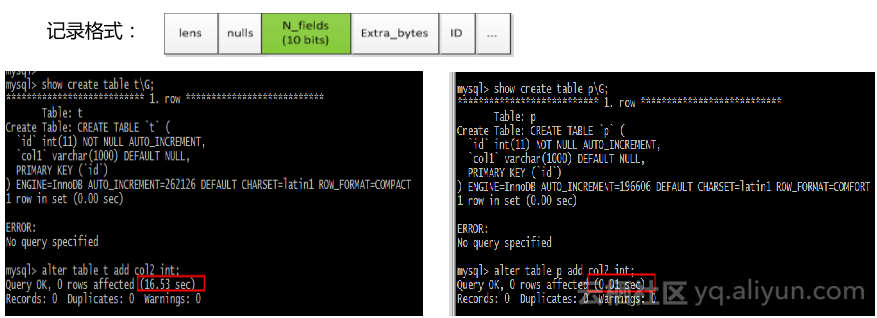
我们希望在简单的加字段过程中做到动态的完成,通过变更innoDB记录格式,在原本格式上增加了N_fields,N_fields代表记录中一共存储多少字段,通过这种方式加字段后,会发现每一条记录里可能的个数都不一样,所以我们加的每一个字段都是“非”,必须加在最后面,如果数据字典比记录fields值多,我们要填充len值,图中新的记录格式变更字段只需很少的时间,因为其中只需做数据字典结构的变更,数据本身不做任何迁移和变更。
AliSQL用户ISSUE和典型问题
- 编译指南:现阶段不支持WINDOWS、不支持embeded,我们也提供了AliSQL Compiler Guide,guide中详细介绍AliSQL在编译过程中需要的环境和参数。
- 参数优化:

我们给出了不同配置规格参数的样例供用户参考,其中有以前没有公开的,也是后面要逐步开放的。
- 秒杀使用指南: