昨天在论坛看到有人提出怎么识别两个字符串最大的相同的部分,很遗憾没人回帖,在此发布一个原创的算法,可以快速的找出两个字符串中所有的最长的相同的部分。
public class BestLike
{
private string strString1="";
private string strString2="";
private string strFormat="";
private string strLargeLen="1";
private int intStart=0;
private List<string> listResult = new List<string>();
public BestLike(string strString1,string strString2)
{
this.strString1 = strString1;
this.strString2 = strString2;
}
public List<string> GetString()
{
//格式化字符串
for(int i = 0; i <= strString1.Length-1;i++)
{
if (strString1.Substring(i, 1) == strString2.Substring(i, 1))
strFormat = strFormat + "1";
else
strFormat = strFormat + "0";
}
//查找最大相同长度
while (strFormat.IndexOf(strLargeLen,0) != -1)
{
strLargeLen = strLargeLen + "1";
}
strLargeLen = strLargeLen.Substring(0, (strLargeLen.Length - 1));
//提取数据并返回
while (strFormat.IndexOf(strLargeLen, intStart)!=-1)
{
listResult.Add(strString1.Substring(strFormat.IndexOf(strLargeLen, intStart),strLargeLen.Length));
intStart = strFormat.IndexOf(strLargeLen, intStart) + strLargeLen.Length;
}
return listResult;
}
}
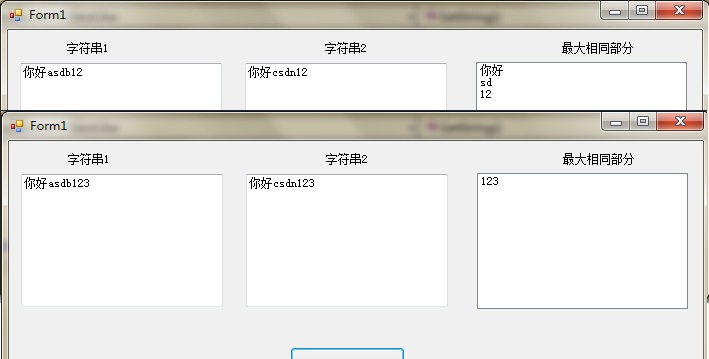
在实例化这个类的时候传入构造方法的参数---要比较的两个字符串,然后调用这个类的GetString ()方法即可,返回的是一个字符串型的泛型集合。因为两个字符串同等长度的部分可能有很多,所以用集合存放。
这个算法可以快速的找出两个字符相同的、最长的部分,而且是所有的。比如,a=”你好asdb12”,b=”你好csdn12”,那么返回的集合就包含了”你好”、”sd”、”12”三个字符串。如果a=”你好asdb123”,b=”你好csdn123”,返回的集合只包含”123”一个字符串,因为它比”sd”和”你好”长。
算法的思想是化繁为简,将两个字符串所有对应的字符一一的进行对比,相同标记为”1”,不同标记为”0”,然后寻找最长的连续的”1”,再根据所找到的”1…1”的位置到原字符串中截取就达到目的了。算法很好的支持了中文,不仅仅是中文,它支持任何一种编程语言支持的字符。
需要注意的是要比较的两个字符串必须等长。
这个算法是C#代码,学习了新语言,想熟悉一下,就没用最拿手的VB,估计以后也比较少用VB了。