一、事务使用条件和场景
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
二、事务特性
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
-
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
-
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0,用来禁止使用当前会话的自动提交。
三、事务的隔离级别
SQL标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
- 读未提交(RU)是指,一个事务还没提交时,它做的变更就能被别的事务看到。(脏读)
- 事务A和事务B,事务A未提交的数据,事务B可以读取到 - 这里读取到的数据叫做“脏数据” - 这种隔离级别最低,这种级别一般是在理论上存在,数据库隔离级别一般都高于该级别
- 读提交(RC)是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 事务A和事务B,事务A提交的数据,事务B才能读取到(不管事务B是否先于事务A开始执行) - 这种隔离级别高于读未提交 - 换句话说,对方事务提交之后的数据,我当前事务才能读取到 - 这种级别可以避免“脏数据” - 这种隔离级别会导致“不可重复读取” - Oracle默认隔离级别 - 可重复读(RR)是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。未提交的更改对其他事务是不可见的
- 事务A和事务B,事务A提交之后的数据,事务B读取不到(事务B在先于事务A开始执行情况下)
- 事务B是可重复读取数据(读到的数据去决于自身事务开启的时间点。在事务开启时,读到的是多少,那么在事务提交之前读到的值就是多少)
- 这种隔离级别高于读已提交
- 换句话说,对方提交之后的数据,我还是读取不到
- 这种隔离级别可以避免“不可重复读取”,达到可重复读取
- 比如1点和2点读到数据是同一个
- MySQL默认级别
- 虽然可以达到可重复读取,但是会导致“幻读” - 串行化:对应一个记录会加读写锁,出现冲突的时候,后访问的事务必须等前一个事务执行完成才能继续执行
- 事务A和事务B,事务A在操作数据库时,事务B只能排队等待 - 这种隔离级别很少使用,吞吐量太低,用户体验差 - 这种级别可以避免“幻像读”,每一次读取的都是数据库中真实存在数据,事务A与事务B串行,而不并发
三、不同隔离级别所面对的问题

很显然,隔离级别越高,它所带来的资源消耗也就越大(锁),因此它的并发性能越低。准确的说,在可串行化的隔离级别下,是没有并发的。
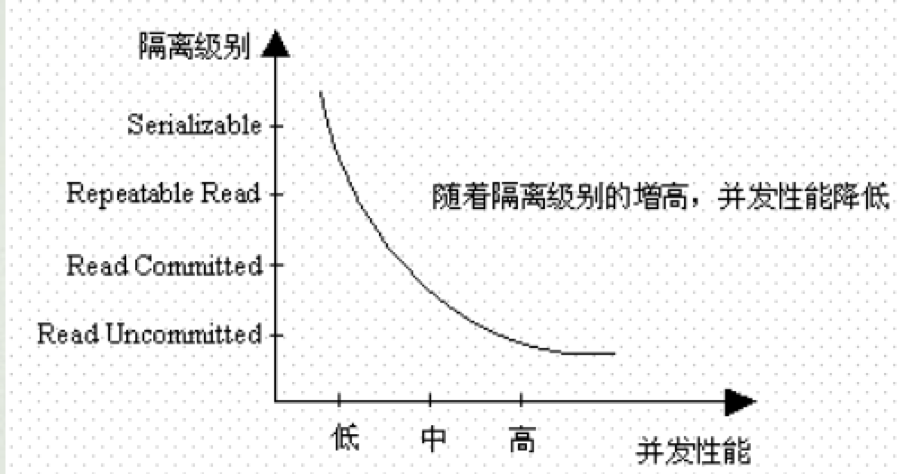
四、事务的隔离级别作用范围
• 事务隔离级别的作用范围分为两种:
– 全局级:对所有的会话有效
– 会话级:只对当前的会话有效
设置隔离级别作用范围
• 例如,设置会话级隔离级别为READ COMMITTED :
mysql> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
或:
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
• 设置全局级隔离级别为READ COMMITTED :
mysql> SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
五、MySql中的事务
事务的实现是基于数据库的存储引擎。不同的存储引擎对事务的支持程度不一样。mysql中支持事务的存储引擎有innoDB和NDB。innoDB是mysql默认的存储引擎,默认的隔离级别是RR,并且在RR的隔离级别下更进一步,通过多版本并发控制(MVCC,Multiversion Concurrency Control )解决不可重复读问题,加上间隙锁(也就是并发控制)解决幻读问题。因此innoDB的RR隔离级别其实实现了串行化级别的效果,而且保留了比较好的并发性能。
事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。
1.redo log
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
记录1:<trx1, insert...>
记录2:<trx2, delete...>
记录3:<trx3, update...>
记录4:<trx1, update...>
记录5:<trx3, insert...>
2.undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程
假设有2个数值,分别为A和B,值为1,2
1. start transaction;
2. 记录 A=1 到undo log;
3. update A = 3;
4. 记录 A=3 到redo log;
5. 记录 B=2 到undo log;
6. update B = 4;
7. 记录B = 4 到redo log;
8. 将redo log刷新到磁盘
9. commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
六、分布式事务
分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。

如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM)。
应用程序定义了事务的边界,指定需要做哪些事务;
资源管理器提供了访问事务的方法,通常一个数据库就是一个资源管理器;
事务管理器协调参与了全局事务中的各个事务。
分布式事务采用两段式提交(two-phase commit)的方式。第一阶段所有的事务节点开始准备,告诉事务管理器ready。第二阶段事务管理器告诉每个节点是commit还是rollback。如果有一个节点失败,就需要全局的节点全部rollback,以此保障事务的原子性。
参考文献:
《高性能mysql第三版》
《mysql技术内幕 innoDB存储引擎》
原文:https://www.cnblogs.com/maypattis/p/5628355.html