本篇文章主要介绍requests获取网页内容出现 'NoneType' object has no attribute 'xpath' 异常的解决思路
下面是出错的代码:
import requests
from lxml import etree
response = requests.get('https://blog.csdn.net/it_xf?viewmode=contents')
etree_html = etree.HTML(response.text)
content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()')
for each in content:
replace = each.replace('
', '').replace(' ', '')
if replace == '
' or replace == '':
continue
else:
print(replace)
1、错误分析
获取到的html.text 为 空字符串;所以下面抛出异常NoneType
原因是请求Get 需要增加 headers来解决反扒;模拟浏览器请求来获取数据;
2、解决办法
首先找到需要的headers,headers 如何寻找?看下图的标记:
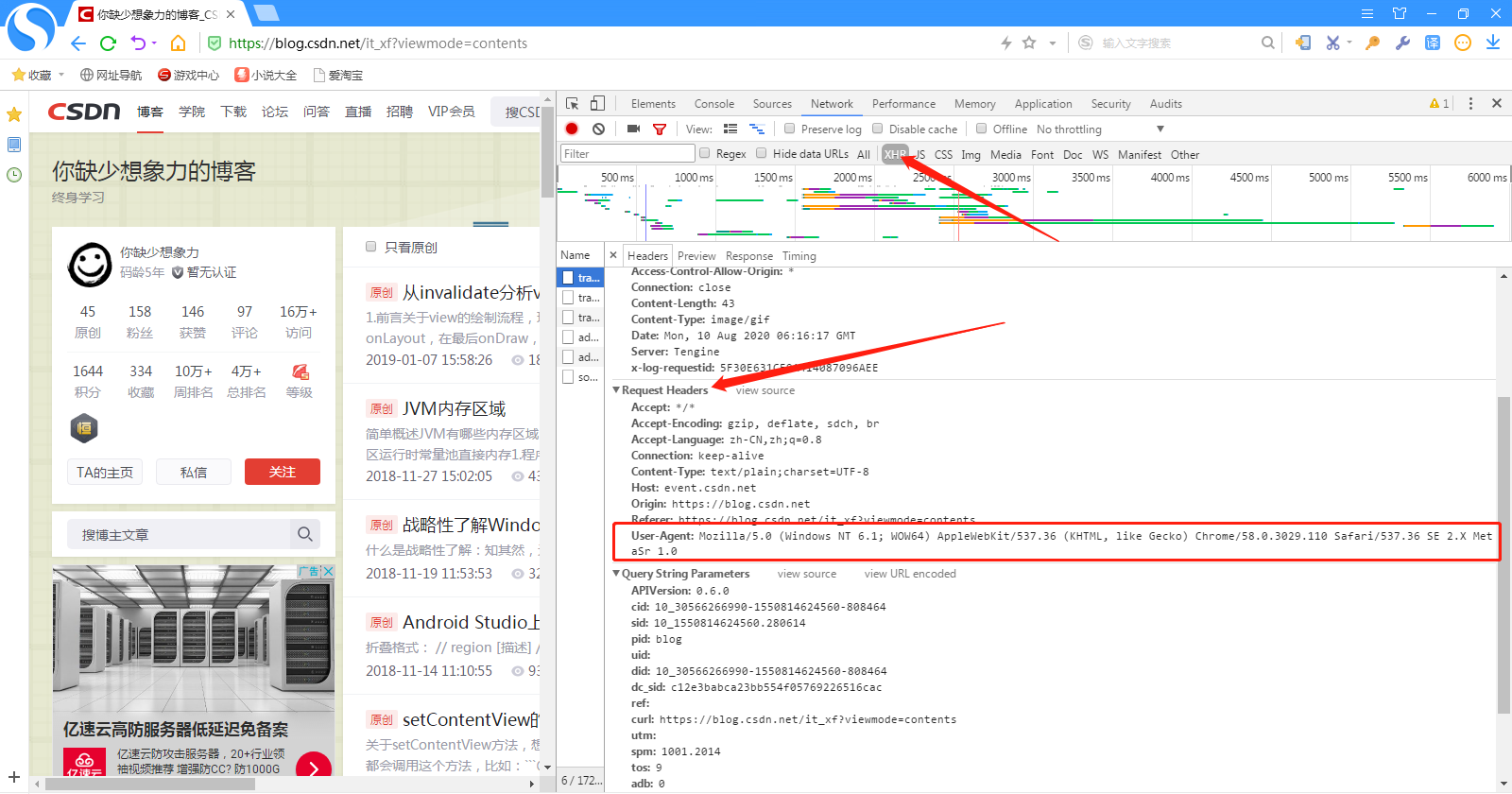
然后直接把上面的headers复制出来放到代码中进行改造;
改造后的代码如下:
1 import requests 2 from lxml import etree 3 headers = { 4 'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) ' 5 'AppleWebKit/537.36 (KHTML, like Gecko) ' 6 'Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0' 7 } 8 response = requests.get('https://blog.csdn.net/it_xf?viewmode=contents', headers = headers) 9 etree_html = etree.HTML(response.text) 10 content = etree_html.xpath('//*[@id="mainBox"]/main/div[2]/div[1]/h4/a/text()') 11 12 for each in content: 13 replace = each.replace(' ', '').replace(' ', '') 14 if replace == ' ' or replace == '': 15 continue 16 else: 17 print(replace)