
在上一篇博文我们介绍了JAVA新生代收集器,本篇博文我们要讲的就是关于老年代的一些收集器。老年代存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域的特性,所以老年代采用的是“标记-清除-整理”算法(以前的博文有详细讨论过)。
- Serila Old收集器:该收集器是Serial收集器的老年代版,同样是一个单线程的收集器,优劣势和Serial收集器一样,这里就不多说了。
- Parallel Old收集器:在我们之前文章的代码例子中默认的年老代收集器,也是Parallel Scavenge收集器的老年代版本。关注点也和Parallel Scavenge收集器一样,注重系统的吞吐量,适合于CPU资源敏感的场合。
- CMS(Concurrent Mark Sweep)收集器:是一种以最短停顿时间为目标的收集器。当应用尤其重视服务的响应速度,希望系统能有最短的停顿时间,该收集器非常适合。
CMS收集器的收集过程比以往的收集器都要复杂,收集过程分为四个步骤:初始标记、并发标记、重新标记、并发清除。
先介绍下每个过程,再来说他是怎么达到最短停顿时间这个目标的。初始标记是需要进行STW的,但仅仅只是标记GC Roots能够直接关联的对象(并不是死掉的对象哦~),由于有OopMap的存在,因此该步骤速度非常快。如图,其中蓝色底纹的便是能够直接关联的对象。 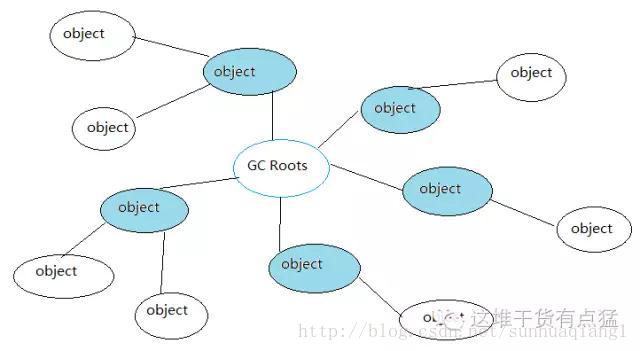
接着就进入了第二步,并发标记。这步是不需要STW的,不需要!他和我们的主程序线程共同执行,从上一步被标记的对象开始,进行可达性分析组成“关系网”。由于不需要进行SWT,所以该步骤不会影响用户体验。既然不暂停线程,小伙伴是不是又怕回收了不该回收的对象?为了避免这个问题,因此就有了第三步。
重新标记是需要STW的,但这又有什么关系呢?重新标记只是为了修改在上一步标记中有了变动的对象。有了这一步,就不怕回收掉不该回收的对象了。而且,由于这一步只是对上一步的结果进行修改,所以STW的时间相当短,对用户的影响不大。
最后一步就是并发清除了,这一步也不需要进行STW,只是清除一些不在“关系网”上的对象而已。
讲到这里,大家应该知道了该收集器如何做到最短停顿时间了吧。通过一次短STW时间的标记和一次不需要STW的标记,大大缩下来第三步标记的范围(只需要修改就好了),第四步不需要STW。
看上去很完美,但还是有他的缺陷:大量使用了并发操作,因此会占用一部分CPU的资源,导致吞吐量下降;当在并发清除垃圾的时候,也就是第四步的时候,他是与当前主线程并发执行的,因此他在回收的时候,我们的主线程又会产生新的垃圾,而这些垃圾在这次回收过程已经回收不了了,只能等待下一次回收了。这些垃圾又叫做“浮动垃圾”。
到这里我们就把老年代的收集器也讲完啦,不知道小伙伴们吸收消化的怎样。学习更重要的还是靠自己的努力与勤奋,别人能给点毕竟有限,自己挖掘才能发现无尽!