1. 集合流的简介
1.1 集合的流式编程简介
Stream流:是JDK1.8之后出现的新特性,也是JDK1.8新特性中最值得学习的特性之一。
Strem流:是对集合操作的增强,流不是集合的元素,也不是一种数据结构,他不负责数据的存储。流更像是一个迭代器,可以遍历集合中的每一个元素进行处理。
1.2 为什么要使用集合的流式编程
有些时候,我们需要对集合中的元素进行操作。在这个过程中,集合的流式编程可以大幅度的简化代码、将集合里面的数据读取到一个流中,对其中的数据进行操作。
1.3 使用流式编程的步骤
- 获取数据源(可以是集合,数组等),将其中的数据读取到流中。
- 对流中的数据进行各种各样的处理。
- 对流中的数据进行整合处理。
2. 数据源的获取
2.1 数据源简介
数据源:就是流中数据的来源。
特别注意:当将数据读取到流中进行处理时,我们在流中对数据进行的处理时,不会影响数据源。
2.2 数据源的获取
- 方法一:
Stream<Integer> stream = list.stream();
- 方法二:
Stream<Integer> stream = list.parallelStream();
- 方法三:
IntStream<Integer> stream = Arrays.stream(array)
关于stream()与parallelStream()的区别:
stream():获取的数据源是串行的。
parallelStream():获取的数据源是并行的。 其中集成了多个线程对流中的数据进行操作,效率更高。
3. 处理
3.1 filter
条件过滤,仅保留流中满足指定条件的数据,其他不满足的数据都会被删除掉。

3.2 distinct

3.3 sorted

3.4 limit和skip

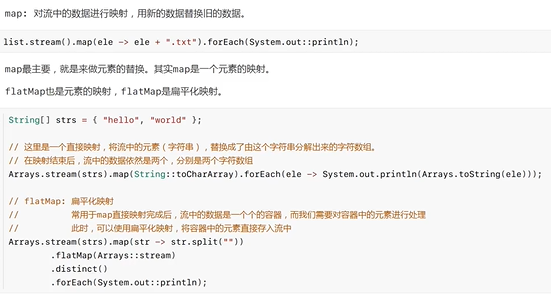
3.5 map和flatMap
4. 整合处理
将流中的数据最终整合到一起,可以将其存入一个集合。
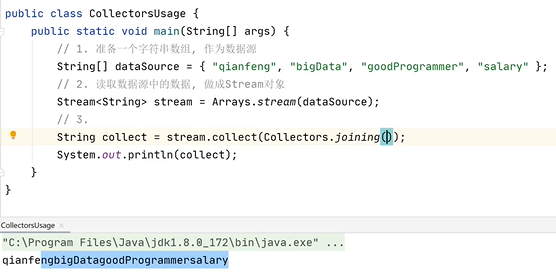
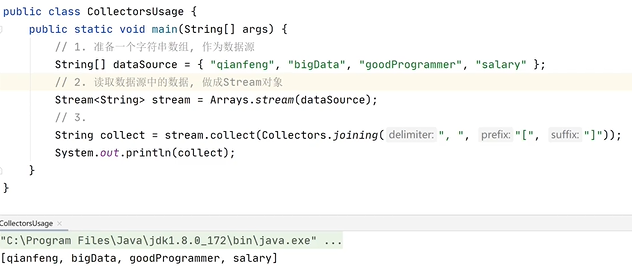
4.1 collect
将流中的数据收集到一起存入一个集合,对这些数据进行一些处理。
collect方法的参数是一个Collector接口,而且,这个接口并不是一个函数式接口,实现这个接口,可以自定义收集的规则。一般情况下,物品们不需要去自定义实现这个接口,直接用Collctors工具类即可。

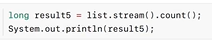
4.2 count
统计流中元素的数量
4.3 foreach

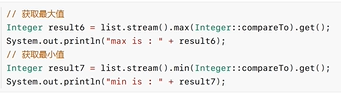
4.4 max和min
4.5 Matching
-
allMatch:只有当流中所有元素都满足指定的规则时,才返回true。
-
anyMatch:只要流中有任意元素满足指定的规则时,就会返回true。
-
noneMatch:只有当流中所有元素都不满足指定的规则时,才返回true。
-

4.5 Find

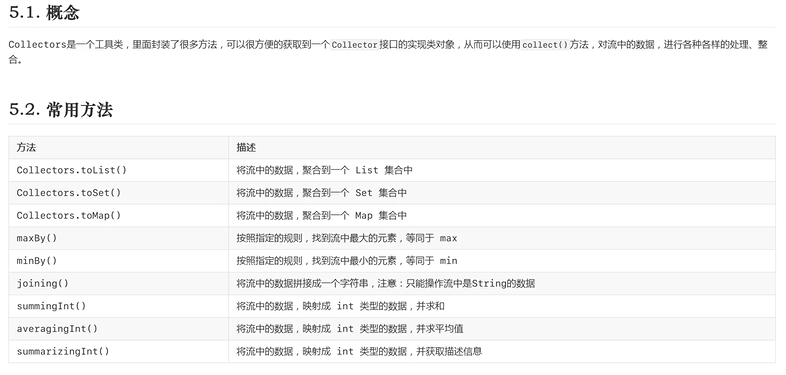
5. Collectors工具类