问题
python课上,老师给同学们布置了一个问题,因为这节课上学的是正则表达式,所以要求利用python爬取小说网的任意小说并保存到文件。
我选的网站的URL是
‘https://www.biqukan.com/0_159/’
解决方法
首先先思考解决方式。
- 先获取到网页源码,从源码中找出小说的名字和目录结构
- 创建文件保存的目录,目录名是小说名
- 从网页代码中获取小说的目录列表
- 循环遍历目录,获取目录中每篇的超链接和文章标题
- 如果是超链接就继续发请求访问从而获取这章小说的正文
- 将正文写入创建好的目录,文件名是这章小说的标题名
使用之前需要导入相关的模块,requests模块,re正则的模块,os模块
导入有好几种,这里介绍的是在命令窗口中导入
以管理员的身份打开命令窗口。
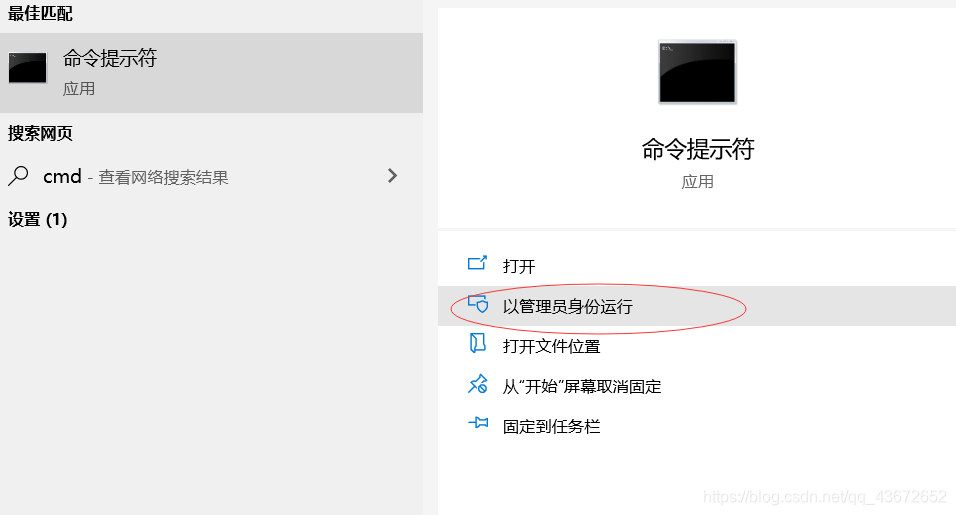
2、输入pip install requests 下载安装requests模块,同样的方式安装剩余模块。
r = requests.get(url)
# 向URL发起get请求,r是返回的对象
r.text就是响应的网页源代码
r.encoding=r.apparent_encoding
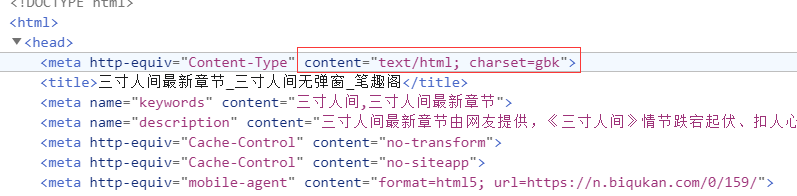
- 这里的encoding指的是对响应结果的编码格式,如果head中没有charset指明编码格式,那么默认是ISO-8859-1,r.text根据encoding编码响应内容;
- apparent_encding是 响应头的编码格式。从网页源代码中可以找出编码方式。
字符编码方式
r.raise_for_status()
如果status_code不是200,产生异常requests.HTTPError;这是HTTP错误。
该语句便于利用try-except进行异常处理。
正则表达式re.findall()方法返回的是一个list集合,关于正则表达式的一些字符。
.代表匹配除换行外的任意字符,*代表匹配一次到N次,?代表采用非贪婪模式匹配,不加?默认是贪婪模式进行匹配。
输入小说的链接,按下F12,查看源代码,检查元素,或是点
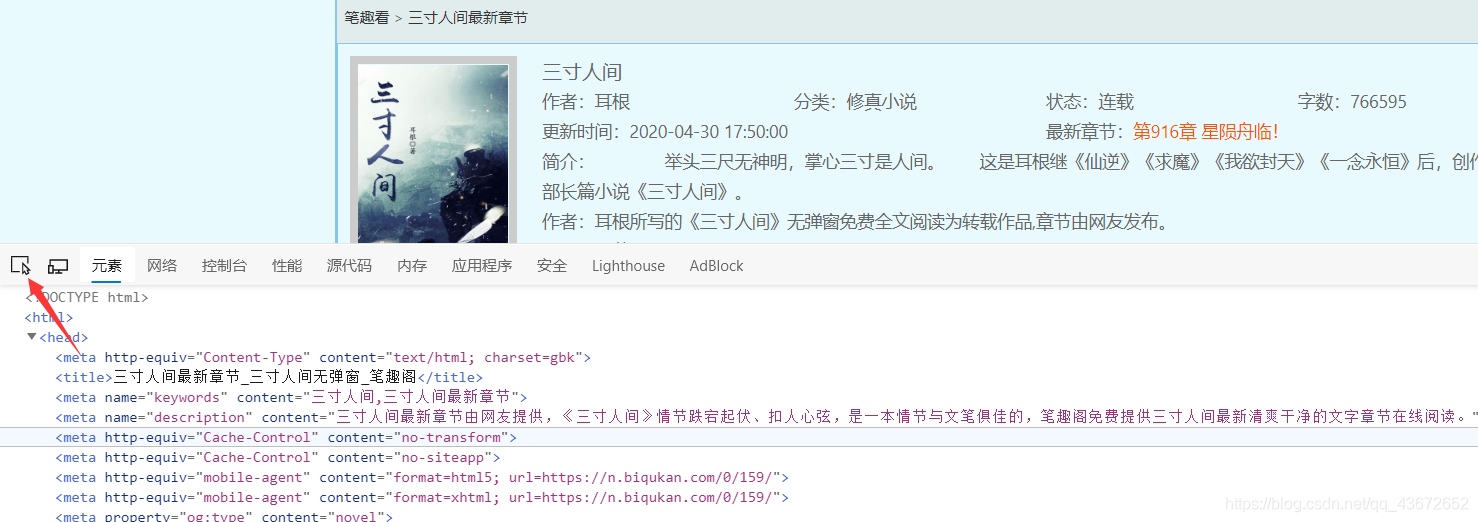
最左边的按钮,找到小说的名字,这时他在h2标签体中;
因此
name = re.findall(r'<h2>(.*?)</h2>',r.text)[0]
因为findall返回的是一个list集合,但是匹配到的只有小说名字一个元素,所以[0]就直接获取了小说名字 ‘三寸人间’
然后创建目录,先判断保存小说的目录存不存在,如果已存在不用创建,如果不存在再创建。这里目录名字就是小说名。
创建完目录后,继续获取小说的目录列表。
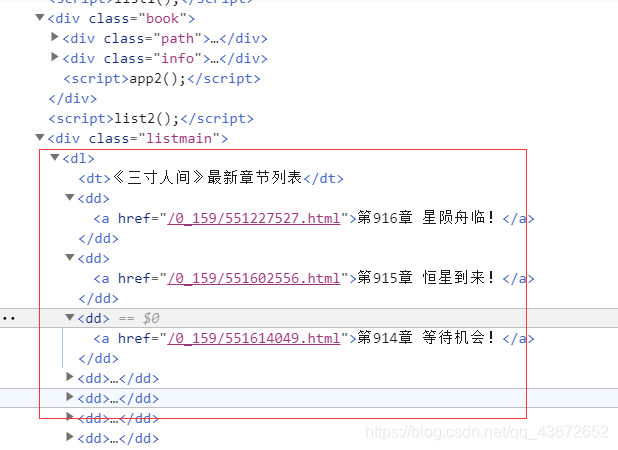
由上图可知,目录都在标签<dl></dl>中,
因此
novleList = re.findall(r'<dl>(.*?)</dl>',html,re.S)[0]
获取目录列表集合,

然后我们要的是a标签找连接里面的内容和href属性值。
在对他进行匹配。得到如下

剩下的就是遍历集合,取出超链接的href和标题,进而访问href,访问的时候需要加上网站的前缀,https://www.biqukan.com/。然后得到正文的返回结果。


想要获取小说内容采用正则匹配,以</script>开头,以<script>结尾。取中间内容。
content = re.findall(r'<script>app2.*?</script>(.*?)<script>',chapterHtml.text,re.S)
最后在保存前需要注意的是,小说中有空格和换行等HTML代码,需要将其替换成相应的格式,保存的时候一定不要忘了编码格式!!!
完整代码如下
import re
import requests
import os
# 将要爬取的url
url = 'https://www.biqukan.com/0_159/'
"""
1. 获取小说名字
2. 创建保存小说的目录
3. 从网页代码中获取小说的目录列表
4. 循环遍历目录,获取每篇的标题,每篇的超链接,如果是超链接就继续请求,进而获取文章内容,最后创建文件将章节写入
"""
# 1.获取小说名
def getNovelName(url):
r = requests.get(url)
# 打印状态码
print(r.status_code)
try:
r.raise_for_status()
r.encoding = r.apparent_encoding
html = r.text
name = re.findall(r'<h2>(.*?)</h2>', html)[0]
except:
return '获取失败'
return name
dirName = getNovelName(url)
#2. 保存小说的路径
path = 'D://workspace//python//reptile//work9_regular/'+dirName
#. 创建一个保存小说的目录
def createDir(path):
try:
if not os.path.exists(path):
os.mkdir(dirName)
else:
print('该文件夹已存在')
except:
print('创建文件失败!')
#3. 创建目录
createDir(path)
def getHtml(url):
r = requests.get(url)
r.encoding=r.apparent_encoding
if r.status_code==200:
return r.text
# 获取小说主页源代码
html = getHtml(url)
#4. 获取目录列表
novleList = re.findall(r'<dl>(.*?)</dl>',html,re.S)[0]
#5. 获取目录中的链接和标题
alls = re.findall(r'<a href ="(.*?)">(.*?)</a>',novleList,re.S)
def writeToFile(alls,path):
# 遍历目录下的标题和链接,继续访问链接获取内容
for item in alls:
hrefs = item[0] # 超链接地址
title = item[1] # 标题
chapterHtml = requests.get('https://www.biqukan.com/'+hrefs)
chapterHtml.encoding=chapterHtml.apparent_encoding
content = re.findall(r'<script>app2.*?</script>(.*?)<script>',chapterHtml.text,re.S)[0]
content = content.replace('<br />','
') # 替换换行
content = content.replace('u3000',' ') # 替换制表
content = content.replace(' ',' ') # 替换空格
f = open(path+'/'+title+'.txt','w',encoding='utf-8') # 注意编码方式
f.write(content)
# 6.写入文件
writeToFile(alls,path)
本人初学者,以上有错误的地方欢迎批评指正,有更好的想法的欢迎评论交流!
最后成功保存下来的截图!
