阿里云的官方文档:https://help.aliyun.com/product/53923.html?spm=a2c4g.11186623.6.540.164a3843m7kJx4
vcenter6
192.168.0.87
administrator@vphere.local
密码
root
密码
esxi6
192.168.0.88
root
密码
本地存储网关
https://192.168.0.90
激活线下网关需要阿里云控制台ak账户开通以下2个权限:AliyunHCSSGWFullAccess 和 AliyunOSSFullAccess。
控制台的缺省用户名是root,缺省密码为Alibaba#sgw#1030。
1、本地存储网关需要的部署的环境为vcenter6以上,5.0.5.5是无法使用的;
2、本地存储网关需要至少4c8g的虚拟机。
3、缓存至少需要40G,原则上一个OSS对应一个缓存。所以如果你想一台服务器对应多个OSS,可以给虚拟机加多个缓存硬盘,每个缓存硬盘需要大于40G
4、存储网关当前支持的网络传输协议有NFS和SMB两种,NFS和SMB都是基于文件系统访问的运行在internet网络的协议。
• NFS协议主要用于Unix操作系统平台,例如AIX、HP-UX及各种Linux的访问。
• SMB协议主要用于windows系统平台的文件系统访问。
5、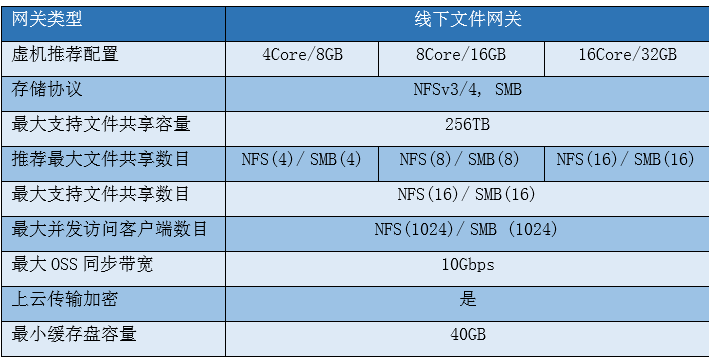
6、虚拟机配置要求
您必须确保在其上部署网关VM的基础硬件满足以下要求:
• 分配给VM的4个虚拟处理器。
• 分配给VM的8GB及以上内存。
• 100GB及以上磁盘空间,适用于安装虚拟机镜像和系统数据。
• 建议采用厚配置部署缓存盘获得更好的IO性能,单个缓存盘大小为40GB及以上。
7、vcenter6,VMware 使用OVA导入方式安装云存储网关,安装步骤见:https://help.aliyun.com/knowledge_detail/54123.html?spm=a2c4g.11186623.2.14.164a3843m7kJx4
8、所有的控制台(使用https://ip进行访问本地存储网关的控制台),操作系统的默认密码都是:缺省用户名是root,缺省密码为Alibaba#sgw#1030
9、时间同步非常重要!!!虚拟机和vcenter的物理母机进行时间同步(在虚拟机配置里勾选同步),再设置esxi的物理母机和阿里云的ntp进行同步!!!
10、激活线下网关需要阿里云控制台ak账户开通以下2个权限:AliyunHCSSGWFullAccess 和 AliyunOSSFullAccess
11、部署好网关后需要先在部署平台(VMWare vSphere, Hyper-V)端添加磁盘,磁盘添加成功后,才能在网关的阿里云控制台或者网关控制台管理界面进行缓存相关的操作;
注:文件网关支持的缓存盘容量最小40G,如果添加的磁盘容量小于40G则在网关上无法识别到新加的磁盘;
12、如果你的缓存是40G,那么其中20%8G是存储元数据(也就是文件的索引信息,文件大小信息等等,并不是真实文件),剩余80%32G才是你真正存放文件的空间,其中20%的空间里元数据是永远都不会删除的,除非你主动去删除它;
剩余的80%的工作机制是这样,当用户存放文件到这个80%了,那么网关会立即同步到阿里云去(这个时间,我测试了下大概是1分钟之内,虽然可以设置0-120秒),如果这个80%的缓存满了,那么系统会自动删除不是热点的文件,并让用户可以放新的文件,当然删除文件必须是已经上传到阿里云的oss桶里的,如果这些文件都没有存放到阿里云去,那么缓存就会爆满,结果就是用户无法在存放新的文件到缓存里去。
13、反向同步:将OSS上的元数据同步回本地。适用网关容灾和数据恢复/共享场景。(一般我们不用这个模式)
14、忽略删除:文件删除操作不同步至OSS防止误操作。保证OSS侧是全量数据。
15、同步延迟:频繁打开正在上传的大文件容易造成OSS碎片。设置延迟后,对于文件不会在关闭后立刻上传,会延迟一段时间,防止频繁的本地修改操作。缺省值为0s,最大值120s。
16、用户端可以使用\ip共享文件夹名来访问本地存储网关,也可以设置为本地映射网络磁盘
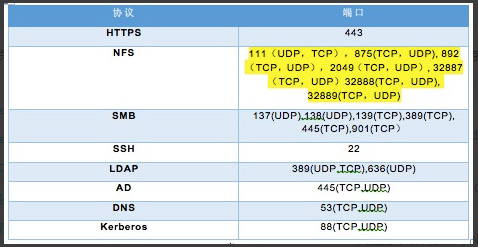
17、服务需要的端口号清单:
18、如果会使用文件网关写入比较大的文件,单一文件大小应保持在缓存盘容量的30%以下,且不能多个大文件并发写入,否则容易造成缓存盘写满的情况。
19、100G的空间大概能hold住3亿文件的元数据。比如说你缓存上了300G,那么元数据只有20%,那么就是60G,那么只能存放1.8亿的元数据文件。
20、目录结构好的话,1s大概能同步1000个文件。
21、反向同步唯一的担心就是,反向在扫描的时候,有可能会影响前端的IO。如果是在前端不忙的时候规划着做,应该也还好。
22、我们会写到60%左右的时候,开始回收空间,我们的回收是会清理掉一部分本地文件的数据部分(基本上就是LRU的这种算法),所有的元数据都保留在本地的。所以用户根本感知不到。数据部分用户读取的话,我们发现本地没有,还会去oss再拉到本地缓存盘。实时通过网络,加载过来。那就是如果打开已经删除数据的文件,打开的速度取决于网络速度了。所以对网络还是有要求的,如果网络不是很好,本地盘就要尽量大一点,多缓存一部分数据
23、公司这边一天是100G的文件,大概有100万个文件。如果你只有1.8亿的元数据文件,那么只能存放180天就爆满!
24、反向同步会从云上OSS Bucket同步元数据到本地的缓存盘,以保证云上和本地缓存的一致性。当使用反向同步时,性能会有一定的损耗。注意是元数据,并不是数据,也就是只是同步索引过来。
25、反向同步我们需要拿两级,拿当前文件夹以及子文件夹,因为当前文件夹的子文件夹的mtime我们要改掉 要不然上面协议头或者操作系统不会清理缓存。首先找到文件夹以及下面所有的文件,同时我们支持用户做一些权限控制的,比如在linux修改用户权限,这部分我们会在object的元数据里面记下来。head request就是去看object里面有没有我们自定义元数据,有的话再同步到本地。如果您这边不关心用户权限,只是文件上传下载,这部分是可以去掉的。
26、反向同步逻辑是 我们会记一下文件夹的同步时间 当这次的访问时间和上次的同步时间超过10小时(你定义的反向同步时间) 就会触发反向同步,如果文件夹一直不访问 就一直不会同步。我们是stat文件夹的时候 和 进文件夹的时候(超过反向的时间间隔) 我们会触发反向同步
27、如果你把缓存盘从100G扩容为600G,扩盘之后可能机器要重启一下 才能认出来盘。要重新建共享的。要删除掉重新创建的。否则仍然认为是100G。
28、这个缓存刷新时间和网络有关系,然后是不是很多要删除的也有关系。线上的话我们一秒处理大概能到2000,线下的话就只有500左右。如果你有2000w个文件。那么需要12小时左右才能刷新完成。