学习Python自然语言处理,记录一下学习笔记。
运用Python进行自然语言处理需要用到nltk库,关于nltk库的安装,我使用的pip方式。
pip nltk
或者下载whl文件进行安装。(推荐pip方式,简单又适用)。
安装完成后就可以使用该库了,但是还需要下载学习所需要的数据。启动ipython,键入下面两行代码:
>>>import nltk >>>nltk.download()
就会出现下面的一个界面:
选择book,选择好文件夹,(我选择的是E: ltk_data)。下载数据。
下载完成后,可以验证一下下载成功与否:
>>> from nltk.book import * *** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: 'texts()' or 'sents()' to list the materials. text1: Moby Dick by Herman Melville 1851 text2: Sense and Sensibility by Jane Austen 1811 text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus text9: The Man Who Was Thursday by G . K . Chesterton 1908
如果出现上面的文本,说明下载数据成功。
在进行下面的操作之前,一定要保证先导入数据(from nltk.book import *)
prac1:搜索文本:
1.concordance('要搜索的文本')
>>>text1.concordance('monstrous') Displaying 11 of 11 matches: ong the former , one was of a most monstrous size . ... This came towards us , ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r ll over with a heathenish array of monstrous clubs and spears . Some were thick d as you gazed , and wondered what monstrous cannibal and savage could ever hav that has survived the flood ; most monstrous and most mountainous ! That Himmal they might scout at Moby Dick as a monstrous fable , or still worse and more de th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l ing Scenes . In connexion with the monstrous pictures of whales , I am strongly ere to enter upon those still more monstrous stories of them which are to be fo ght have been rummaged out of this monstrous cabinet there is no telling . But of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
2.similar('文本'):搜索那些词出现在相似的上下文中:
>>>text1.similar('monstrous') exasperate imperial gamesome candid subtly contemptible lazy part pitiable delightfully domineering puzzled determined vexatious modifies fearless christian horrible mouldy doleful >>>text2.similar('monstrous') very heartily so exceedingly a extremely good great remarkably amazingly sweet as vast
可以看出text1和text2在使用monstrous这个词上在表达意思上完全不同,在text2中,monstrous有正面的意思。
3.common_contexts(['word1','word2'...]):研究共用2个或者2个以上的词汇的上下文。
>>>text2.common_contexts(['monstrous','very']) a_lucky be_glad am_glad a_pretty is_pretty
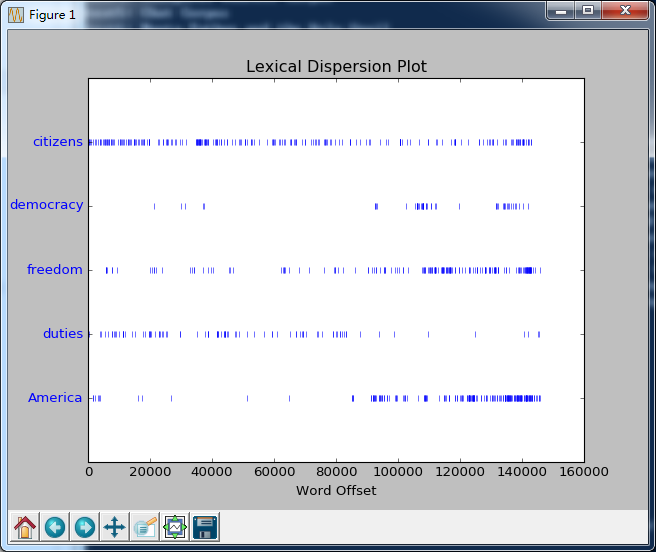
4.dispersion_plot():位置信息离散图。每一列代表一个单词,每一行代表整个文本。(ps:该函数需要依赖numpy和matplotlib库)
>>>text4.dispersion_plot(['citizens','democracy','freedom','duties','America'])
piac2:计数词汇:
计数词汇主要函数为len(),sorted():用于排序,set():用于得到唯一的词汇,去除重复。这些函数的用法和Python中一样,不做重复。
piac3:简单的统计:
该部分中很多函数都不在适用于python3,有的用法需要自己改进,有的则完全不可用
1.频率分布:FreqDist(文本):统计文本中每个标识符出现的频率。该函数在Python3上使用需要改进。
例如我们在text1《白鲸记》中统计最常出现的50个词:
原始版本:
>>>fdist1=FreqDist(text1) >>>vocabulary1=fdist1.keys() >>>vocabulary[:50]
但是在Python3中却行不通了。我们需要自己对其进行排序;
>>>fdist1=FreqDist(text1) >>>len(fdist1) 19317 >>>vocabulary1=sorted(fd.items(),key=lambda jj:jj[1],reverse=True) >>>s=[] >>>for i in range(len(vocabulary1)): s.append(vocabulary1[i][0]) >>>print(s) [',', 'the', '.', 'of', 'and', 'a', 'to', ';', 'in', 'that', "'", '-', 'his', 'it', 'I', 's', 'is', 'he', 'with', 'was', 'as', '"', 'all', 'for', 'this', '!', 'at', 'by', 'but', 'not', '--', 'him', 'from', 'be', 'on', 'so', 'whale', 'one', 'you', 'had', 'have', 'there', 'But', 'or', 'were', 'now', 'which', '?', 'me', 'like']
在本书中,凡是涉及到FreqDist的都需要对其进行改进操作。
2.细粒度选择词:这里需要用到Python的列表推导式。
例如:选择text1中长度大于15的单词:
>>>V=sorted([w for w in set(text1) if len(w)>15]) ['CIRCUMNAVIGATION', 'Physiognomically', 'apprehensiveness', 'cannibalistically', 'characteristically', 'circumnavigating', 'circumnavigation', 'circumnavigations', 'comprehensiveness', 'hermaphroditical', 'indiscriminately', 'indispensableness', 'irresistibleness', 'physiognomically', 'preternaturalness', 'responsibilities', 'simultaneousness', 'subterraneousness', 'supernaturalness', 'superstitiousness', 'uncomfortableness', 'uncompromisedness', 'undiscriminating', 'uninterpenetratingly']
判断的条件还有:s.startwith(t)、s.endwith(t)、t in s、s.islower()、s.isupper()、s.isalpha():都是字母、s.isalnum():字母和数字、s.isdigit()、s.istitle()
3.词语搭配和双连词:collocations()函数可以帮助我们完成这一任务。
如查看text4中的搭配:
>>>text4.collocations()
United States; fellow citizens; four years; years ago; Federal
Government; General Government; American people; Vice President; Old
World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice;
God bless; every citizen; Indian tribes; public debt; one another;
foreign nations; political parties
本书的第一章中还有一个babelize_shell()翻译函数,键入后会出现下面错误:
NameError: name 'babelize_shell' is not defined
原因是因为该模块已经不再可用了。
利用Python的条件分支和循环就可以简单的来处理一些文本信息。