可以访问 这里 查看更多关于 消息中间件 的原创文章。
移山是禧云自研的数据迁移平台,包含异构数据源的迁移、实时数据同步等服务。有兴趣的可以看这里:了解在移山中怎么实现异构数据源的迁移;
本文主要介绍移山实时数据同步服务产生的背景以及整体架构设计。
- 可以访问 这里 查看更多关于大数据平台建设的原创文章。
一. 移山实时数据同步服务产生背景
-
禧云各个子公司业务系统基本都是以 MySQL 为主;
-
做为数据支持部门,需要订阅这些业务数据做为数据仓库的数据源,来进行下游的数据分析。比如:
-
各种离线数据 T+1 报表展示;
-
实时数据大屏展示等。
-
微信小程序实时数据指标展示
像这种常见的实时数据指标大屏展示,背后可能就用到实时数据同步服务技术栈。
二. 移山实时数据同步服务使用canal中间件
1. 使用场景符合
它可以对 MySQL 数据库增量日志解析,提供增量数据订阅和消费,完全符合我们的使用场景。
2. 支持将订阅到的数据投递到kafka
canal 1.1.1版本之后,server端可以通过简单的配置就能将订阅到的数据投递到MQ中,目前支持的MQ有kafka、RocketMQ,替代老版本中必须通过手动编码投递的方式。
移山的实时数据同步服务使用的MQ为kafka,以下为主要配置:
修改canal.properties中配置
# 这里写上当前canal server所在机器的ip canal.ip = 10.200.*.109 # register ip to zookeeper(这里写上当前canal server所在机器的ip) canal.register.ip = 10.200.*.109 # 指定注册的zk集群地址 canal.zkServers =10.200.*.109:2181,10.200.*.110:2181 # tcp, kafka, RocketMQ(设置serverMode模式,这个配置非常关键,我们设置为kafka) canal.serverMode = kafka # 这个demo就是conf目录里的实例 canal.destinations = demo # HA模式必须使用该xml,需要将相关数据写入zookeeper,保证数据集群共享 canal.instance.global.spring.xml = classpath:spring/default-instance.xml # 这里设置 kafka集群地址(其它关于mq的配置参数可以根据实际情况设置) canal.mq.servers = 10.200.*.108:9092,10.200.*.111:9092
修改demo.properties中配置
# canal伪装的MySQL slave的编号,不能与MySQL数据库和其他的slave重复 # canal.instance.MySQL.slaveId=1003 # 按需修改成自己的数据库信息 # position info(需要订阅的MySQL数据库地址) canal.instance.master.address=10.200.*.109:3306 # 这里配置要订阅的数据库,数据库的用户名和密码 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.defaultDatabaseName = # 设置要订阅的topic名称 canal.mq.topic=demo # 设置订阅散列模式的分区数 canal.mq.partitionsNum=3
备注
-
更多关于mq的配置参数解释,可以访问这里:https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
-
多个 canal server 除了 ip 和 MySQL.slaveId 设置不同外,其它都应该保持相同的配置。
3.支持带cluster模式的客户端链接,保障服务高可用
-
客户端可以直接指定zookeeper地址、instance name,canal client 会自动从zookeeper中的running节点,获取当前canal server服务的工作节点,然后与其建立链接;
-
其它canal server节点则做为Standby状态,如果当前active节点发生故障,可以自动完成failover切换。
对canal 的高可用(HA机制)想了解更多,可以查看这篇文章。
三. 移山实时数据同步流程图
实时数据同步服务流程图(摘自《禧云数芯大数据平台技术白皮书》)如下:
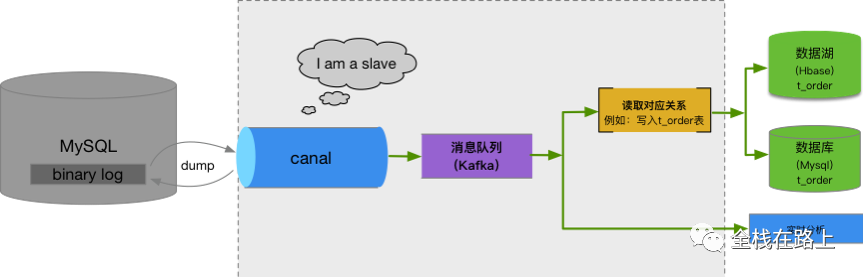
总结
-
canal server 订阅业务系统的 MySQL 数据库产生的 bin log;
-
canal server 将订阅到的 bin log 投递至 kafka 指定的topic里;
-
kafka 消费端拿到消息,根据实际的数据使用场景,将数据再写入 Hbase 或 MySQL,或直接做实时分析。
四. 创建一个实时数据同步任务的主要步骤
以创建一个数据订阅类型为 HBase 的数据同步任务为例,主要步骤如下:
-
创建kafka的topic;
-
进入到canal server的bin目录,拷贝example整个目录,生成一个新的实例目录;
-
手动修改新实例的配置文件,配置以下主要参数:
-
3.1 设置slaveId,不能与已经成功运行的实例设置的slaveId值重复;
-
3.2 要订阅的数据库所在的机器地址和端口号;
-
3.3 要订阅的数据库名称;
-
3.4 要订阅的表;
-
3.5 要订阅的数据库用户名、密码;
-
3.6 配置向kafka发送消息的topic;
-
3.7 配置kafka的partition等;
-
-
重启canal server;
-
查看实例的启动日志,判断实例是否启动成功。
存在的问题
由于缺乏 WebUI 的支撑,因此会存在以下问题:
-
流程复杂:如上这些一系列的操作都是依靠脚本的方式配置完成,配置过程繁琐,数据开发者很容易在某个环节上发生遗漏、出错;
-
不利于任务的统一管理:比如谁开发的任务可能只有写代码的这个人比较熟悉;
-
不方便查看任务的运行情况:比如已消费消息数、延迟消息数;
-
不利于排查问题:查看任务的执行情况只能登陆 canal server 所在服务器去查看任务所属实例的启动日志,如果遇到错误时,不能够快速及时的排查问题。
怎么解决问题
为了解决上面提到的这些问题,我们开发了移山的实时数据同步服务。
后话
-
在最新的稳定版:canal 1.1.4版本,迎来最重要的 WebUI 能力;
-
instance 可以通过 WebUI 来创建,但是有部分使用者反馈,instance的启动会有不稳定的情况出现,我们期待稳定版本可以快速发布。
五. 移山实时数据同步服务整体架构
1. 所需集群环境
zookeeper集群
为什么要用zookeeper集群,可以看这篇文章:阿里canal是怎么通过zookeeper实现HA机制的?
kafka集群
-
kafka 具有高吞吐量、内置的分区、备份冗余分布式等特点,为大规模消息处理提供了一种很好的解决方案;
-
前面已经提到过 canal 中间件通过简单的配置即可支持将订阅到的数据直接投递到 kafka中。
canal server集群
为保障数据订阅服务的稳定性,我们需要借助 canal 的HA机制,实现故障自动转移,保障服务高可用,因此我们需要部署多个 canal server。
hbase集群
-
数据湖在禧云的实践是存储集团各子公司、ISV各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析和传输;
-
数据湖的技术解决方案,我们选择的是 Apache HBase。
2. 移山实时数据同步架构设计
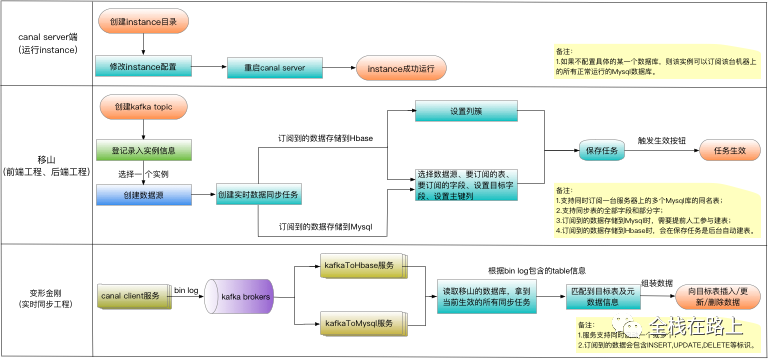
架构图
canal server端
-
在canal server 的多个节点上手工创建、运行instance;
备注:
-
我们在配置instance相关参数时,不指定具体的数据库,这样该instance可以订阅到该MySQL节点上的所有数据库,然后在移山创建同步任务时再指定具体要订阅的表。
移山
前端采用 Vue.js + Element UI,后端使用 SpringBoot 开发:
-
前端工程
-
负责提供创建实时同步任务所需的 WebUI;
-
提供丰富的任务运行监控功能。
-
-
后端工程
-
负责前端工程的数据接口,会记录目标表(实时同步任务订阅到的数据最终存储的目的地)的各种元数据信息。
-
备注:
-
如果要创建的同步任务将数据存储至MySQL,则需要提前人工干预创建MySQL表(MySQL数据库由DBA统一管理);
-
如果要创建的同步任务将数据存储至Hbase,则在移山创建任务时,由后台自动创建Hbase表。
变形金刚
处理订阅数据存储的java工程,分为三个可单独部署的模块:
-
canal client服务
-
canal 客户端,从 canal server 拿到数据,并将数据投递至kafka。
-
-
kafkaToHbase服务
-
kafka 消费端,负责将接收的消息进行转化处理,处理后的数据存储至Hbase。
-
-
kafkaToMySQL服务
-
kafka 消费端,负责将接收的消息进行转化处理,处理后的数据存储至MySQL。
-
备注:
-
以上三个服务均支持命令行启动、停止。
更多文章
欢迎访问更多关于消息中间件的原创文章:
- RabbitMQ系列之消息确认机制
- RabbitMQ系列之RPC实现
- RabbitMQ系列之怎么确保消息不丢失
- RabbitMQ系列之基本概念和基本用法
- RabbitMQ系列之部署模式
- RabbitMQ系列之单机模式安装
关注微信公众号
欢迎大家关注我的微信公众号阅读更多关于 消息队列 的原创文章: