基本语法:
CREATE DATABASE [IF NOT EXISTS] db_name [DEFAULT] CHARACTER SET charset_name [DEFAULT] COLLATE collation_name;
最简便的设置(字符集和校验规则都采用默认设置):

创建一个名为itbsl的数据库,并设置字符集和校验规则

说明:
- MySQL语句以分号结尾;
- MySQL语句关键字不区分大小写。例如,不管写成CREATE还是create,效果是一样的,不过为了便于区分还是建议MySQL关键字大写,字段名和表名小写。
- CHARACTER SET
字符集,表示数据库的文字编码方式,上图中设置的是utf8,如果没有设置则采用默认值,这个默认值可以通过my.ini配置文件来修改,(MySQL8默认字符集是utf8mb4) - COLLATE
校验规则,校验规则影响如下:
1.查询结果的影响:如果是utf8_general_ci表示不区分大小写,如果是utf8_bin则表示区分大小写
2.对order by子查询的结果有影响 - 如果在数据库下创建表,那么在默认情况下,表将会使用对应的数据库的字符集和校验规则,如果在创建表的时候指定了新的字符集和校验规则,则以当前表的设置为准。
- 在创建数据库指定字符集时,可以用character set utf8,也可以用charset=utf8,两种均可。
字符集和校验规则
字符集是一套符号和编码。校验规则是在字符集内用于比较字符的一套规则。
字符集
- MySQL5.5.3之后增加了utf8mb4字符编码,最多使用四个字节存储字符
- utf8mb4是utf8的超集并完全兼容utf8,能够用四个字节存储更多的字符。
有了utf8,为什么要用utf8mb4?
标准的UTF-8字符集编码是可以使用1-4个字节去编码21位字符,这几乎包含了世界上所有能看见的语言。
而mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符等等。
MySQL在5.5.3版本之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。
当然了,如果我们能够确定数据库中不会存储四字节字符,完全可以使用utf8编码,因为这样更加节省空间。
我们可以通过select version()查看数据库的版本,以确定是否支持utf8mb4。
select version();

校验规则
是在字符集内用于比较字符的一套规则,比如定义'A'<'B'这样的关系的规则。不同collation可以实现不同的比较规则,如'A'='a'在有的规则中成立,而有的不成立;进而说,就是有的规则区分大小写,而有的无视。
utf8mb4对应的校验规则有utf8mb4_unicode_ci、utf8mb4_general_ci
utf8mb4_unicode_ci和utf8mb4_general_ci的对比:
- 准确性
- utf8mb4_unicode_ci是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
- utf8mb4_general_ci没有实现Unicode排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。
- 但是,在绝大多数情况下,这些特殊字符的顺序并不需要那么精确。
- 性能
- utf8mb4_general_ci在比较和排序的时候更快
- utf8mb4_unicode_ci在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
- 但是在绝大多数情况下发,不会发生此类复杂比较。相比选择哪一种collation,使用者更应该关心字符集与排序规则在db里需要统一。
校验规则的影响
实际操作来看看校验规则的影响
(1) 校验规则对查询的影响:
在数据库itbsl下创建一个校验规则为utf8_general_ci的test表;
use itbsl;
create table `test`(
`id` int auto_increment primary key comment "主键",
`name` char(20) not null default '' comment '姓名'
)charset=utf8 collate utf8_general_ci;
insert into `test` value(default, 'a');
insert into `test` value(default, 'A');
insert into `test` value(default, 'b');
insert into `test` value(default, 'B');
在校验规则为utf8_general_ci的情况下,查询name等于a的结果有两条,因为不区分大小写,如图所示:

在数据库itbsl下创建一个校验规则为utf8_bin的test2表;
use itbsl;
create table `test2`(
`id` int auto_increment primary key comment "主键",
`name` char(20) not null default '' comment '姓名'
)charset=utf8 collate utf8_bin;
insert into `test2` value(default, 'a');
insert into `test2` value(default, 'A');
insert into `test2` value(default, 'b');
insert into `test2` value(default, 'B');
在校验规则为utf8_bin的情况下,查询name等于a的结果只有一条,因为区分大小写了,如图所示:

(2) 校验规则对排序的影响
utf8_general_ci:
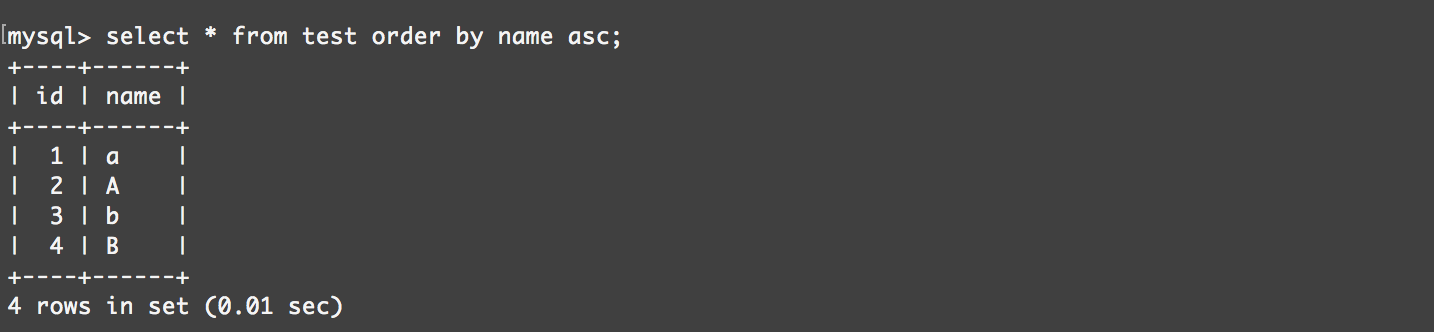
utf8_bin: 排序时按照字母对应的ascii码值排序

数据库操作相关指令
查询数据库版本
SELECT VERSION();

显示数据库语句
SHOW DATABASES;

显示数据库创建语句
SHOW CREATE DATABASE db_name;

itbsl被反引号``包裹,如果使用``包裹数据库名或表名,这样数据库名或者表名使用了关键字,也不会报错,会正常执行,所以建议在创建数据库或者表时都加上反引号,但是同时建议数据库名和表明不要和关键字一样。
/*!40100 DEFAULT CHARACTER SET utf8 */
上面这句话不是注释,而是表示:当MySQL数据库版本大于4.01时,就执行DEFAULT CHARACTER SET utf8mb4,反之就不执行这句话。
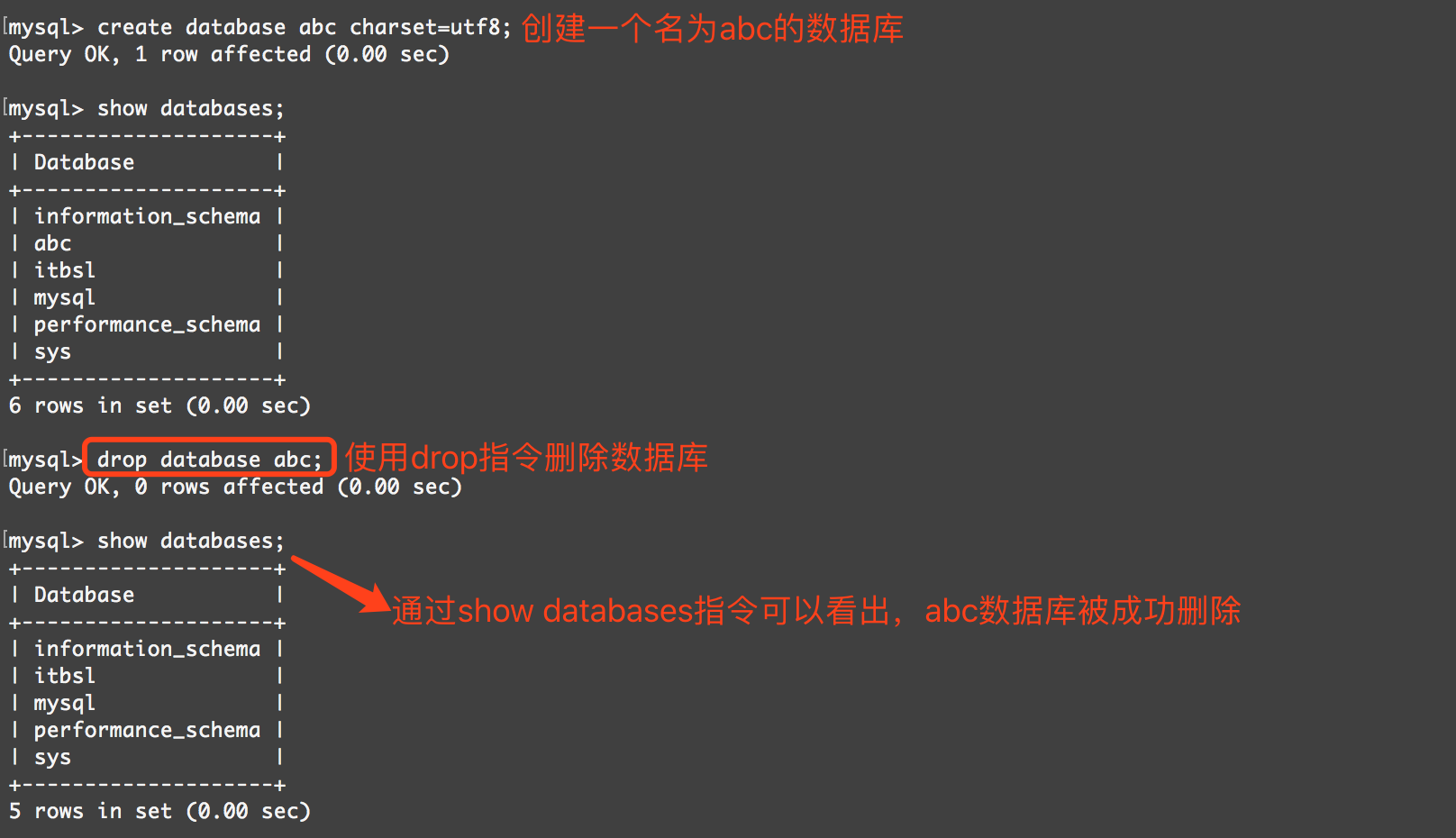
数据库删除语句
DROP DATABASE [IF EXISTS] db_name;
查看当前数据库有多少个用户在操作
SHOW PROCESSLIST;

通过这个命令可以查看当前有哪些用户在连接MySQL,如果看到非法(异常)用户,可以及时发现并对其进行处理。