一个比特(bit)可以是0,或者是1,8个比特(bit),组成一个字节(byte)。全为0时代表数字0,全为1时代表数字255。

一个字节可以表示256个数字,两个字节可以表示65536个数字。

更多的字节,可以有更多的组合,就可以表示更大的数值范围。
整数可以这么存,那字符呢?一堆二进制的0和1,怎么也算不出字母A吧。不能直接表示,那就通过数字中转一下。只要给它指定一个数值编号,要存储字符时,就存储这个数值。要读取时,按照映射关系找到这个字符。

像这样收录许多字符然后给它们一一编号,得到一个字符编号对照表,这就是“字符集”。
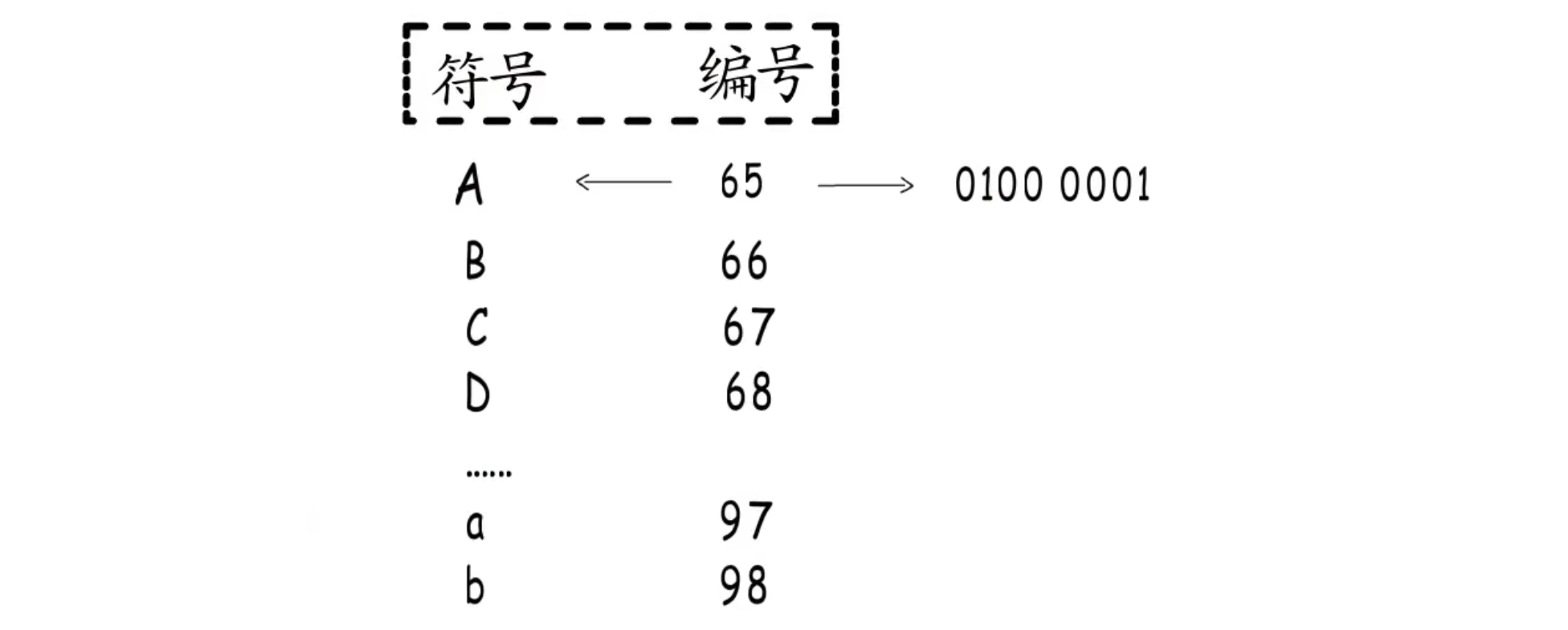
ASCII字符集只收录了128个字符,其扩展字符集也只有256个。(ASCII最初被设计的目的也只是用来映射英文体系所需要的字符)
这在只使用英文的国家貌似没什么问题,但是随着世界的互联,其它非英语母语的国家该怎么办呢?比如汉字、日文等。
针对汉字,最先设计了GB2312字符集、但是GB2312不包含繁体字,所以又设计了BIG5字符集,但是依然有很多字符没有被收录,其它国家的字体也不在其中
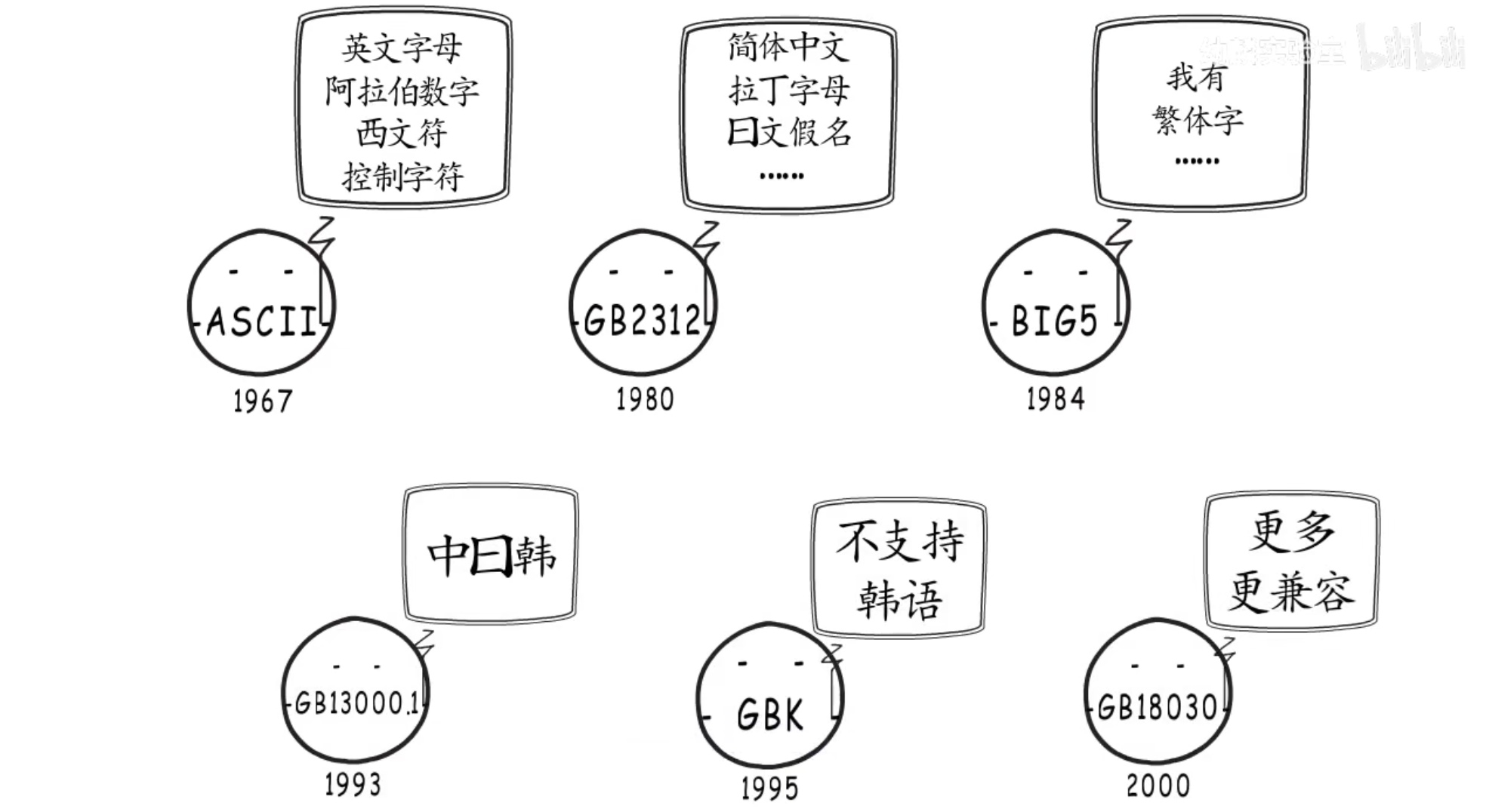
与其不断推出收录更多字符的字符集,还不如本着全球化统一标准的目的,制作一个通用字符集,Unicode学术学会就是这样做的,这个字符集就是Unicode,它于1990年开始研发并于1994年正式公布,实现了跨语言跨平台的文本转换与处理,字符集促成了字符与二进制的合作。但是有了字符集就万事大吉了吗?那怎么存储(eggo世界)这个内容呢?

直接的想法是,找到每个字符对应的编号,存成二进制,如果使用unicode字符集,拿到他们的编号,直接组合会得到这样一大串二进制位

问题出现了,该怎么知道这一长串内容是要按照下面的方式划分的呢?

也可以按照下面的方式划分呀

所以,照搬编号的方式,行不通!!!
那现在我们可以知道了,编码完成之后还需要解决的一个问题是如何划分字符边界。
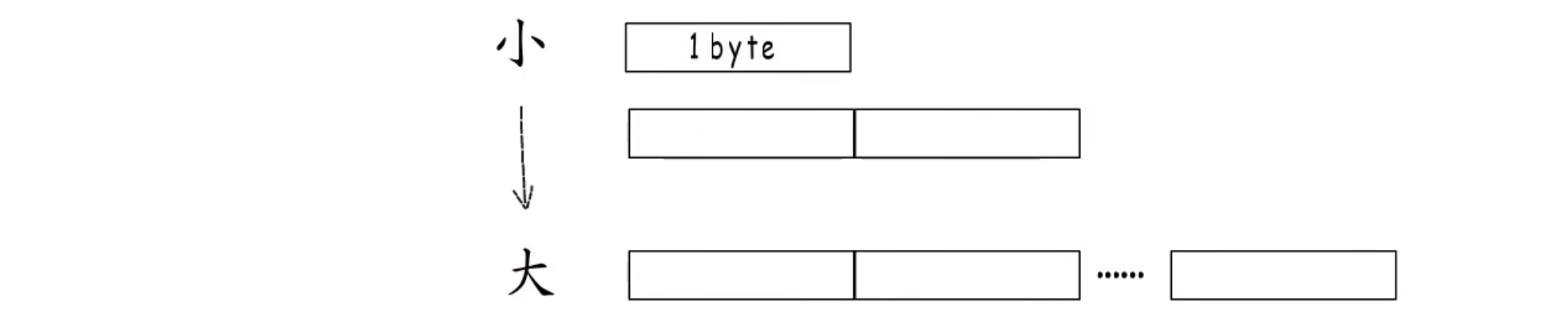
其中一个方法可以这样,不管编号多大多小,统一按照最长的编码的来,位数不够的高位补0嘛

这就是定长编码,这样就可以解决字符边界的问题,但是可以发现,这样就太浪费内存了,而且字符集收录的符号越多,编号跨度就越大,定长编码造成的浪费就越显著,还得再想办法,定长编码不行,那就“变长编码”,小编号少占字节,大编号多占字节。
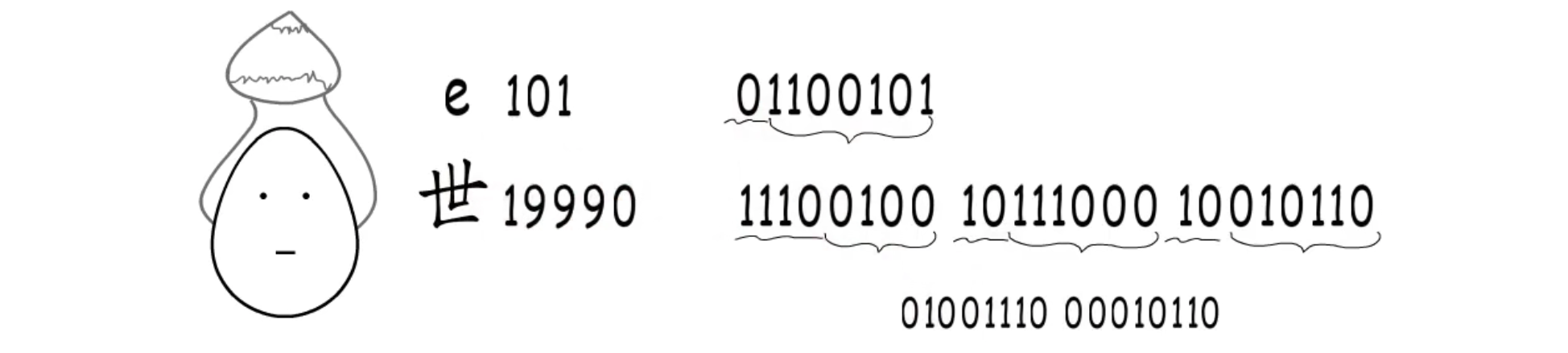
但是怎么划分字符边界呢?来看一种解决方案,如果编号属于[0,127],就占用一个字节,且最高位固定标识为0。如果属于[128,2047],就占用两个字节,且有固定标识位110和10,三个以及更多字节的编码也遵循这样的规则

以二进制数字01100101,这个字节最高位是零,就表示这个字符只占一个字节,除去标识位,剩下的7位就是该字符的二进制编号,转换成十进制就是101,对应字符e,“世”字同理。
这样划分字符就不成问题了。刚刚我们做的是解码,现在来编码试试,世界的“界”字在Unicode字符集中编号为30028,符合区间[2048,65535],所以要占用三字节,使用下面这个模板。
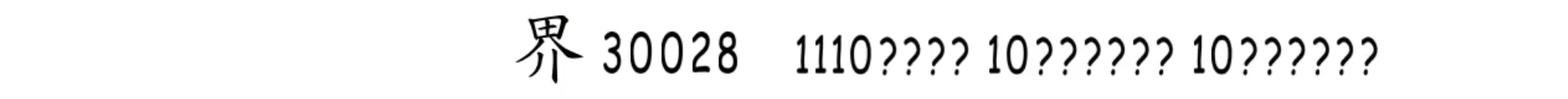
然后将编号30028转换成二进制01110101 01001100,再对应填到模板中

好的,这样就编码完成了, 我们刚刚用的其实就是UTF-8编码,也就是Go语言默认的编码方式。