转载自:https://www.cnblogs.com/Scott007/p/3893318.html
1 概述
为了增大并发性,Yarn采用事件驱动的并发模型,将各种处理逻辑抽象成事件和调度器,将事件的处理过程用状态机表示。什么是状态机?
如果一个对象,其构成为若干个状态,以及触发这些状态发生相互转移的事件,那么此对象称之为状态机。
处理请求作为某种事件发送到系统中,由一个中央调度器传递给对应的事件调度器,进而对事件进行处理,处理完成之后再次发送给中央调度器,再进行处理,直至处理完成。
Yarn的资源管理模块ResourceManager,其核心构成就是四类这样的状态机(基于2.4版本),分别是:
(1)RMApp:用于维护一个Application的生命周期;
(2)RMAppAttempt:用于维护一次试探运行的生命周期;
(3)RMContainer:用于维护一个已分配的资源最小单位Container的生命周期;
(4)RMNode:用于维护一个NodeManager的生命周期;
以上四个状态机,以继承了EventHandler 的Interface的形式存在于Yarn源码的org.apache.hadoop.yarn.server.resourcemanager中。其具体实现类,则是对应的xxxImpl类。
提交到Yarn中的应用程序被称为Application,它可能会尝试运行多次,每次的尝试运行称为“Application Attempt”,如果一次尝试运行失败,则由RMApp创建另一个继续运行,直至达到失败次数的上限。Container是运行环境的抽象概念,无论是ApplicationMaster还是具体的每个Task都得运行在Container中。
2 RMApp状态机
此状态机的具体实现类为org.apache.hadoop.yarn.server.resourcemanager.rmapp. RMAppImpl。其内部记录了一个Application的所有状态RMAppState(共11种)、触发状态间转换的事件RMAppEvent(共14种)、Application的其他基本信息等。其功能就是接收其他对象发出的RMAppEventType类型的事件,然后根据当前状态和事件类型,将当前状态转移到另外一种状态,同时触发一种行为。
下图是RMApp的状态转换图。
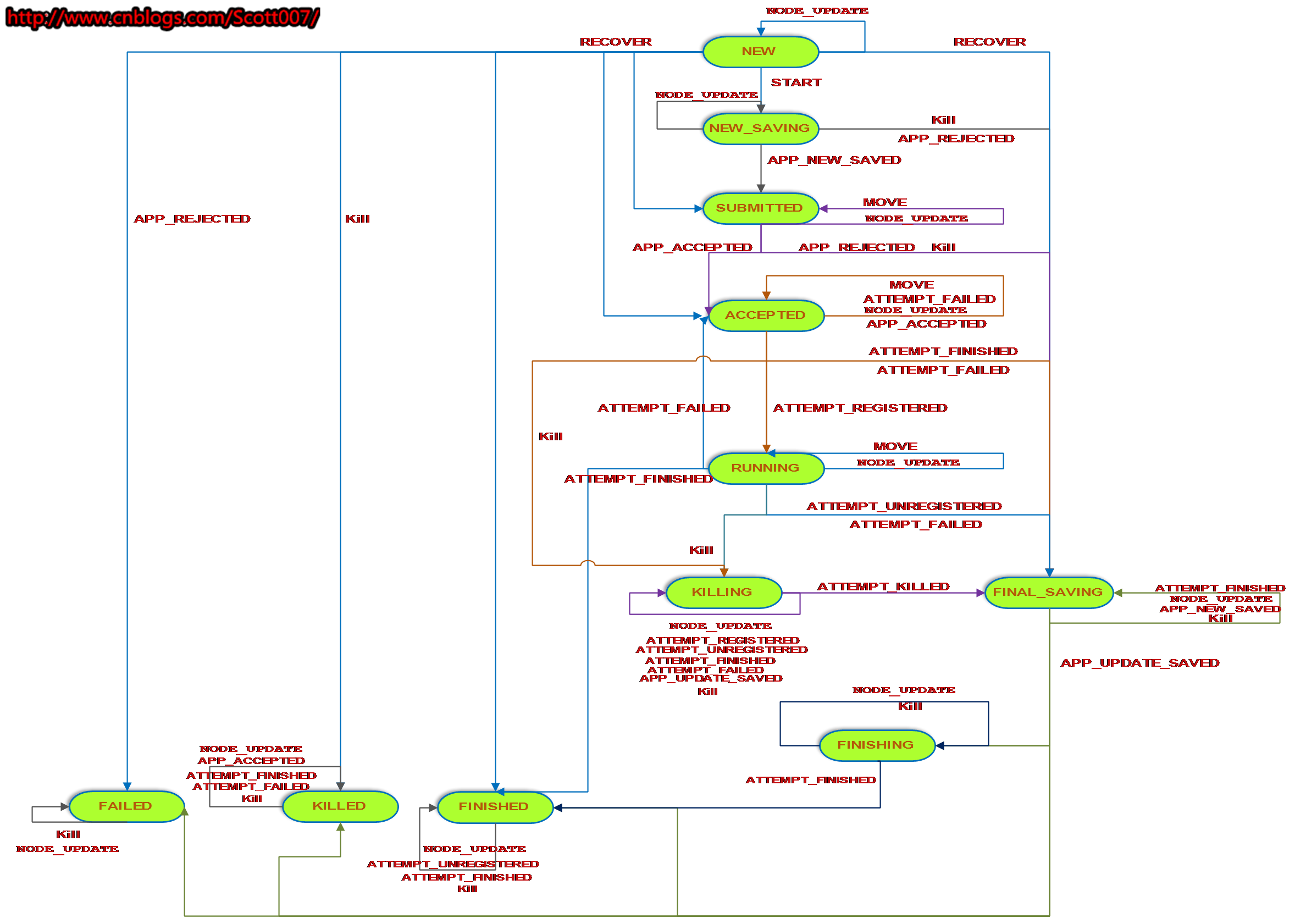
其中,NEW_SAVING状态,指的是使用日志记录Application基本信息时所处的状态,这是RM收到Application时所做的第一件事情,以便故障后重启。接收到RECOVER重启事件后,可以从NEW状态直接转变为SUBMITTED、ACCEPTED、FINISHED、FAILED、KILLED、FINAL_SAVING状态,但是默认情况下,Recover是不开启的,可以通过参数yarn.rsourcemanager.recovery.enabled设置。
APP_REJECTED事件触发的情况比较多,客户端在提交Application时如果发生异常、RM审核Application不合法等,均会触发。
Application运行失败的情况也比较多,但是ATTEMPT_FAILED事件被触发后,不一定直接转入FAILED,系统会检查当前Application的失败次数是否达到上限,如果没有的话,会重新创建一个RMAppAttemptImpl对象,并让状态机回到ACCEPTED状态,否则进入FINAL_SAVING,进而进行失败处理,比如释放资源等。
3 RMAppAttempt状态机
此状态机的具体实现类为org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl。其内部记录了一个Application Attepmt的所有状态RMAppAttemptState (共13种)、触发状态间转换的事件RMAppAttemptEvent(共15种)等。其功能就是接收其他对象发出的RMAppAttemptEventType类型的事件,然后根据当前状态和事件类型,将当前状态转移到另外一种状态,同时触发一种行为。
下图是RMAppAttempt的状态转换图。
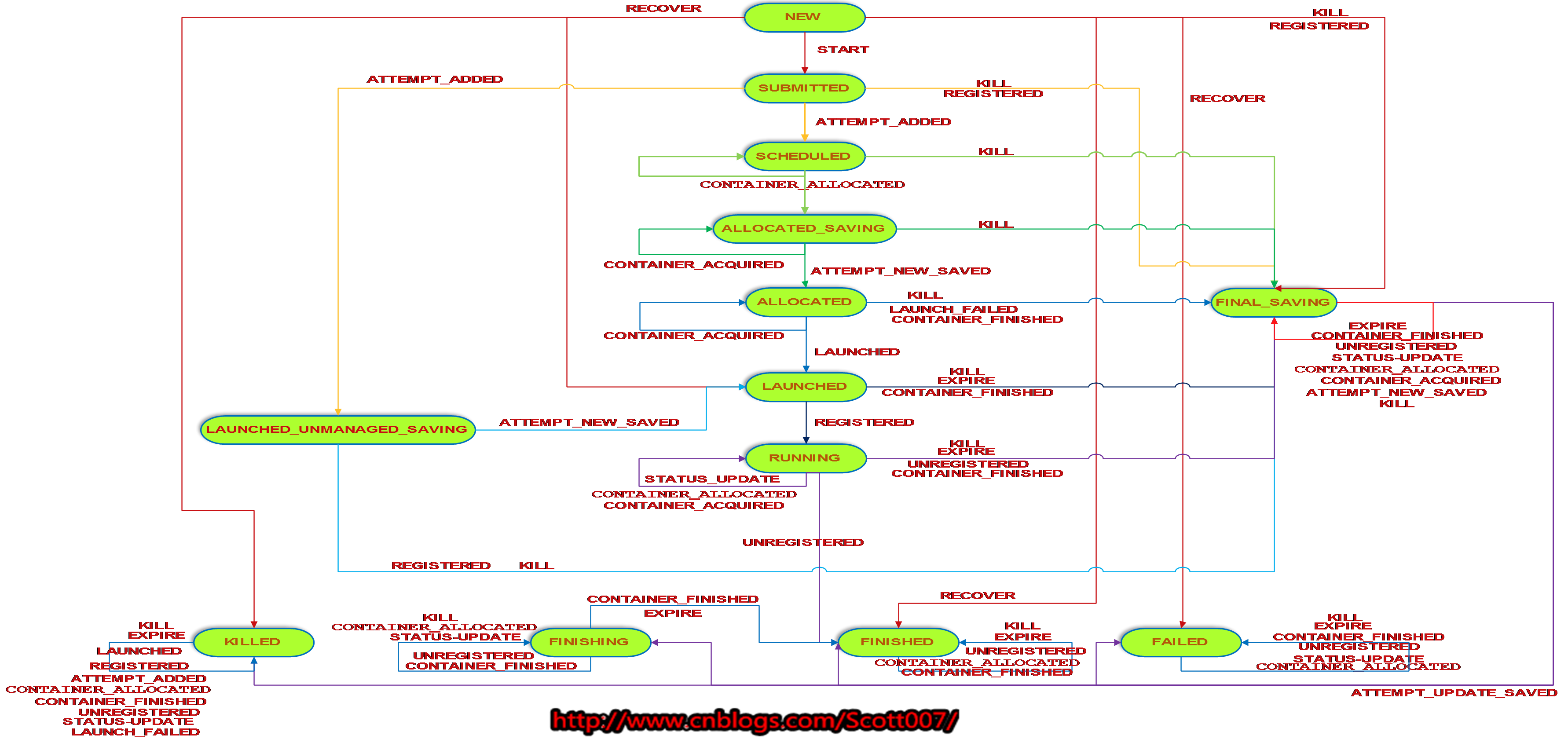
其中,RMAppAttemptImpl被创建之后,ResourceManager将其加入到ResourceScheduler中,通过合法性检查后的状态就是SCHEDULERED,此时开始给ApplicationMaster分配资源。在接收到分配的一个Container资源后,将Container信息写到磁盘,以后故障恢复用,保存完成之前的状态变为ALLOCATED_SAVING,保存完毕了状态就变为ALLOCATED。
接着,ResourceManager中的ApplicationMasterLauncher与对应的NodeManager通信,进行启动ApplicationMaster,此时状态变为LAUNCHED,启动完成之后,ApplicationMaster立即向ResourceManager注册,状态变为RUNNING。
同时,由于Yarn允许ApplicationMaster启动在客户端,比如Spark的yarn-client模式,此时仍然需要记录ApplicationMaster的日志以便进行故障恢复,正在进行记录日志的RMAppAttemptImpl所处的状态就是LAUNCHED_UNMANAGED_SAVING,至于RECOVER,与前面的RMApp状态机类似。
还有几个比较重要的事件:
(1)CONTAINER_ALLOCATED:RresourceManager将某个NodeManager节点上的Container分配给RMAppAttemptImpl之后,会创建一个RMContainerImpl(后文会讲),并向该对象发送一个启动事件,进而向RMAppAttemptImpl发送一个CONTAINER_ALLOCATED事件,此时RMAppAttemptImpl将获取分配到的Container资源,并发起一个日志记录的事件,将资源分配的信息写到磁盘以便进行故障恢复。
(2)UNREGISTERED:当ApplicationMaster运行完成之后,会通知ResourceManager,ResourceManager接受到通知后会发送一个UNREGISTERED事件给RMAppAttemptImpl,进而进入FINISHING状态,等待Container退出后,资源被回收,再变为FINISHED状态。但是如果ApplicationMaster是由客户端自行启动的,收到UNREGISTERED事件后会直接变为FINISHED状态。
(3)CONTAINER_FINISHED:当ApplicationMaster所在的Container退出后,大当前NodeManager节点会将其状态汇报给ResourceManager,这时ResourceManager会发出一个FINISHED事件给RMContainerImpl,它再发出一个CONTAINER_FINISHED事件给RMAppAttemptImpl。
(4)EXPIRE:若ApplicationMaster一段时间内未汇报心跳,则ResourceManager会发出一个EXPIRE事件给RMAppAttemptImpl,会清理ApplicationMaster和Container。
(5)CONTAINER_ACQUIRED:ApplicationMaster获得资源后,向Container发出通知,RMContainerImpl接受到通知后进而向RMAppAttemptImpl发出CONTAINER_ACQUIRED事件,RMAppAttemptImpl将NodeManager信息保存,便于后面进行Container的清理。
(6)STATUS_UPDATE:ApplicationMaster向ResourceManager的心跳汇报。
4 RMContainer状态机
此状态机的具体实现类为org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl。其内部记录了一个Container的所有状态RMContainerState (共9种)、触发状态间转换的事件RMContainerEvent (共8种)等。其功能就是接收其他对象发出的RMContainerEventType类型的事件,然后根据当前状态和事件类型,将当前状态转移到另外一种状态,同时触发一种行为。
下图是RMContainerImpl的状态转换图。
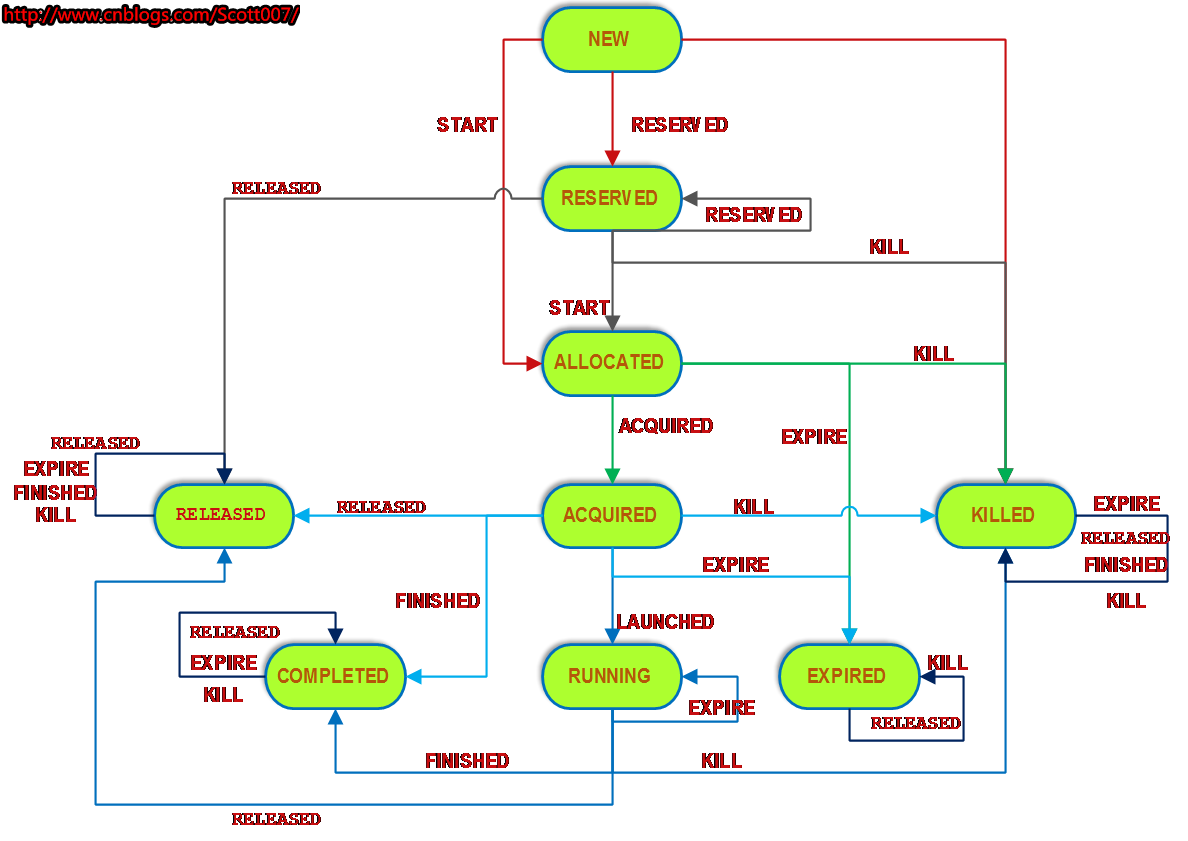
当一个NodeManager上的资源不足以满足当前一个Application的请求却有不得不分配给这个Application时,当前节点会为此Application预留资源,逐渐累加空余的剩余资源直至满足要求后才把资源封装成一个Container发给ApplicationMaster。如果一个Container已经被创建,并且处在剩余资源的累加过程中,它就处于上图中的RESERVED状态。当此Container已经分配给ApplicationMaster,并且此时ApplicationMaster还没发送通知说它已经得到了资源时,此Container处于ALLOCATED状态,直至ApplicationMaster发送通知给ResourceManager说它已经拿到了资源,则状态变为ACQUIRED。
之后,ApplicationMaster与NodeManager通信来启动这些Container,并且NodeManager会将Container的状态通过心跳报告给ResourceManager,ResourceManager则对收到的心跳的每个Container发送一个LAUNCHED事件,RMContainerImpl将收到事件对应的Container从失效列表中移除,表示Container状态正常。如果一段时间内,ApplicationMaster都没有使用某个Container,则ResourceManager对此Container发出EXPIRE事件,进行资源回收。
5 RMNode状态机
此状态机用于维护一个NodeManager的生命周期,其实现类是org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNodeImpl,记录了NodeManager节点的各个状态NodeState (共6种)以及触发状态转换的事件RMNodeEvent(共9种),状态转换的同时会触发一种行为。
下图是RMNodeImpl的状态转换图。

其中,如果一个NodeManager节点被加入到黑名单,则其状态会被置为DECOMMISHONED状态,即下线状态,进而NodeManager进程会退出。若当前NodeManager节点处于UNHEALTHY状态,不健康了(比如磁盘损坏),则会通过心跳通知给ResourceManager,ResourceManager将不再为此节点分配新的任务,向ResourceManager的心跳报告丢失之后,NodeManager变为LOST状态。
当Application执行完成之后,会触发CLEANUP_APP事件,用于清理程序所占用的内存,而一个Container执行完成的时候,会触发CLEANUP_CONTAINER事件,用于清理Container占用的资源。若一个NodeManager重复向ResourceManager注册,则ResourceManager会触发一个RECONNECTED事件,RMNodeImpl收到事件通知后更新自身的信息。