一、安装准备
1、操作系统 Centos 7.x
2、时间问题
集群内所有节点时间一定要同步。
NTP、Chrony
3、用户
创建hadoop组和hadoop用户,并做ssh免密码登录
4、Hadoop HA集群
Hadoop 2.7.3
5、HBase
hbase 1.x
6、Hive
Hive 1.2.1,使用 mysql 存放元数据
7、准备目录
# mkdir /install # cd /install # chown -R hadoop:hadoop /install
8、kylin
kylin 1.6.0 这个版本支持hbase1.x版本 apache-kylin-1.6.0-HBase1.1.3-bin.tar.gz $ tar xf apache-kylin-1.6.0-hbase1.x-bin.tar.gz -C /install $ cd /install $ mv apache-kylin-1.6.0-bin/ kylin
#代表在root用户下
$代表普通用户
二、环境变量配置
部署每个节点 hadoop用户的 .bashrc export HADOOPROOT=/install export HADOOP_HOME=$HADOOPROOT/hadoop export ZOOKEEPER_HOME=$HADOOPROOT/zookeeper export HBASE_HOME=$HADOOPROOT/hbase export HIVE_HOME=$HADOOPROOT/hive1.2 export HCAT_HOME=$HIVE_HOME/hcatalog export KYLIN_HOME=$HADOOPROOT/kylin export CATALINA_HOME=$KYLIN_HOME/tomcat export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-1.2.1.jar PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin PATH=$PATH:$HBASE_HOME/bin:$FLUME_HOME/bin:$HIVE_HOME/bin:$HCAT_HOME/bin PATH=$PATH:$CATALINA_HOME/bin:$KYLIN_HOME/bin export PATH
基本的配置已经做好了,安装从以下步骤开始
三、配置kylin
修改bin/kylin.sh export KYLIN_HOME=/install/kylin export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
压缩问题
关于压缩的问题
本次不是用snappy,如果需要事先重新编译Hadoop源码,使得native库支持snappy
使用snappy能够实现一个适合的压缩比,使得这个运算的中间结果和最终结果都能占用较小的存储空间
1、 kylin.properties
1)设置Rest Server kylin.rest.servers=192.168.56.201:7070 默认为PST,修改为中国时间 kylin.rest.timezone=GMT+8
2)不启用压缩,注释即可
#kylin.hbase.default.compression.codec=snappy(注释掉或者设置为None)
3)定义kylin用于MR jobs的job.jar包和hbase的协处理jar包,用于提升性能(添加项)。
kylin.job.jar=/installsoftware/ kylin-1.6.0/lib /kylin-job-1.6.0.jar kylin.coprocessor.local.jar=/installsoftware/ kylin-1.6.0/lib/kylin-coprocessor-1.6.0.jar
2、kylin_job_conf.xml
不使用压缩
mapreduce.map.output.compress设置为false
mapreduce.output.fileoutputformat.compress 设置为false
3、kylin_hive_conf.xml
不使用压缩
hive.exec.compress.output 设置为false
四、启动服务
Kylin工作原理图

支撑服务启动
1、首先看一下时间是否同步
2、启动3个节点的ZooKeeper zkServer.sh start start-dfs.sh start-yarn.sh 或者start-all.sh mr-jobhistory-daemon.sh start historyserver要到所有NM上启动,可以写成脚本 start-hbase.sh
> list
这里可以启动hive客户端看看
$ hive
> show tables;
检查
1、检查基础的服务
Hadoop、HBase、Hive、环境变量、工作目录
2、hive依赖检查
find-hive-dependency.sh
3、hbase依赖检查
find-hbase-dependency.sh 启动kylin bin/kylin.sh start 停止过程 bin/kylin.sh stop stop-hbase.sh mr-jobhistory-daemon.sh stop historyserver stop-yarn.sh stop-dfs.sh zkServer.sh stop 可以写成脚本
五、登录
http://node1:7070/kylin
ADMIN/KYLIN登录
六、样例数据测试
启动kylin后,运行bin/sample.sh
查看sample.sh脚本内容
实际上操作的是sample_cube目录下的数据和脚本

重启kylin服务
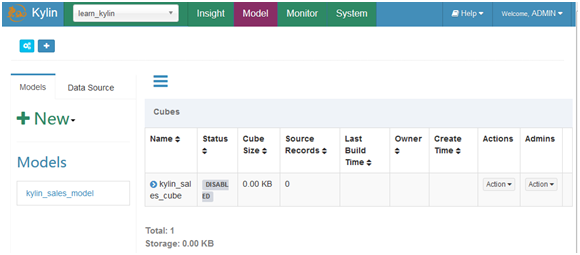
看看hive和hbase
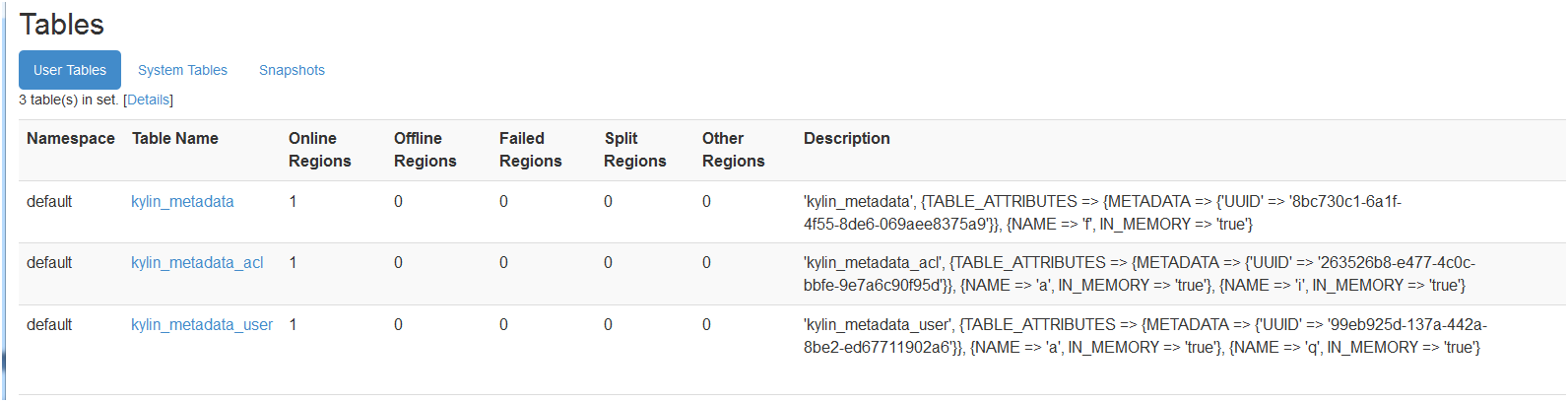
Hive中kylin的元数据信息


默认有一个Cube定义,需要Build。
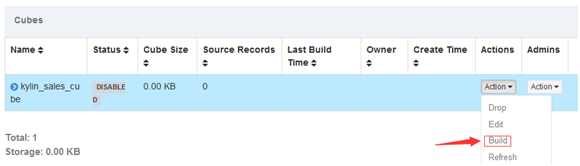

Monitor中监视整个构建过程
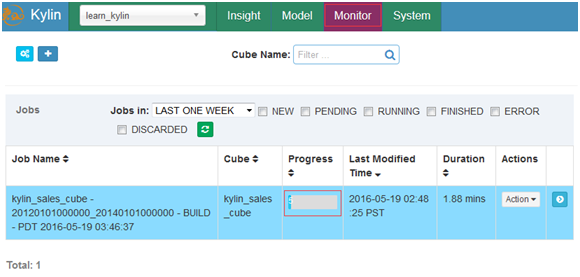
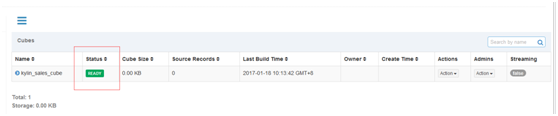
Cube构建成功后状态会变成Ready状态
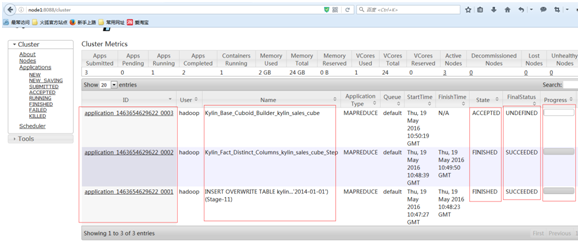
构建Cube过程根据集群性能的不同而不同
七、查询时间对比
测试语句 select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt; select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales where part_dt<'2013-01-01' group by part_dt order by part_dt; hive执行时间 Time taken: 168.643 seconds, Fetched: 365 row(s) kylin中 第一次 1.33S 第二次 0.38s 第三次 0.33s 第四次 0.34s 看来有缓存 select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt having sum(price)>1200 order by part_dt
到此Kylin的前期安装部署已经完毕