出自:https://zhuanlan.zhihu.com/p/81033956
概述
Hadoop作为最早开源的大数据处理系统,经过多年发展为业界主流架构,并拥有一套完善的生态圈,同时作为应用在HDFS之上的数仓解决方案,通过这么多年发展,是大企业大数据平台广泛采用的方案。但是Hive由于采用的MR计算架构,存在一定性能瓶颈,而各种新兴的大数据处理架构蓬勃发展,如何摆脱MR计算架构,同时兼容Hive架构是很多新兴架构的在技术演进过程中需要考虑的重要点。
目前业界SQL引擎基本都兼容Hive,例如Impala,Presto,Drill等。Spark SQL也不例外,在2.0版本前,Spark SQL连接Hive除了元数据Metadata之外,从语法解析开始都是Hive完成的。Spark2.0版本之后,引入了ANTRL4作为SQL编译器,摆脱了对Hive的依赖。
源码入口

阅读逻辑
一,HiveSessionState
Spark SQL本身核心类是SessionState,该类整合了Catalog,Parser,Analyzer,SparkPlanner等所必须的对象。同样,在连接Hive时,也存在类似对象HiveSessionState。而HiveSessionState重载了三个重要对象:Catalog,Analyzer,SparkPlanner。

二,Spark Thrift Server
thrift是一种接口描述语言和二进制通信协议,由 Facebook 开发并贡献到 Apache 开源社区,用来定义和创建跨语言的服务。
作为服务化的应用,离不开服务端( Server )、客户端( Client )、鉴权管理( Auth)、客户端与服务端会话( Session )操作( Operation ) 等概念
Spark Thrift Server源自HiveServer2,封装比较复杂,但是大体还是随着Thrift服务来,可分为如下体系:
Service 体系
Operation 与 OperationManager体系
Session 与 SessionManager 会话体系
Authentication 安全认证管理
三,Hive相关策略体系
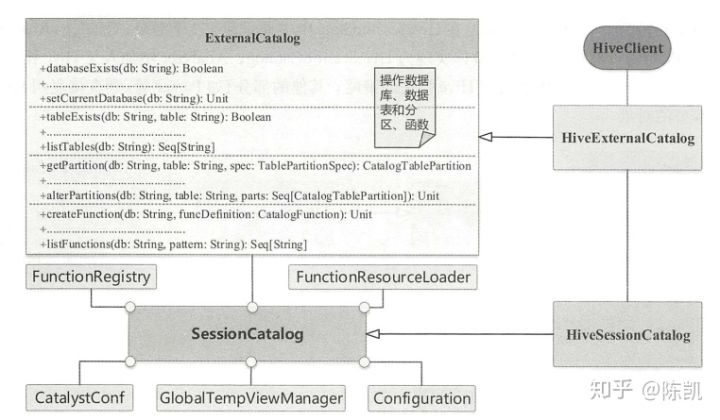
1,HiveSessionCatalog 体系
在逻辑计划阶段已经总结过 SparkSQL 中默认的 Catalog 体系,对于其他模块, Session Catalog ,提供调用的接口,而 External Catalog 则是实际存储与操作数据的根本所在。 在 Hive 场景下,HiveSession Catalog 继承了 Session Catalog, HiveExternalCatalog 则继承了 ExternalCatalog
2,Analyzer 之 Hive-Specific 分析规则
在逻辑计划阶段, HiveSessionState 中仍然会生成新的 Analyzer ,如图 10.5 所示,可以看到,不同之处在于 extendedCheckRules 中少了 HiveOnlyCheck 规则,且extendedResolutionRules 中多了 ParquetConversions 和 OrcConversions 两条规则 。 在默认的 Analyzer 中, HiveOnlyCheck 规则会遍历逻辑算子树,如果发现 CreateTable 类型的节点且对应的 CatalogTable 是 Hive 才能够提供的,则会抛出 AnalysisException 异常,因此在 Hive 场景下,这条规则不再需要 。
顾名思义, ParquetConversions 与 OrcConversions 用来处理 Parquet 数据表文件与 ORCFile数据表文件 。
3,SparkPlanner 之 Hive-Specific 转换策略
在物理计划阶段, HiveSessionState 中创建的 SparkPlanner 与 SessionState 中默认创建的 SparkPlanner 的区别。 由此可见,在 Hive 场景中, extraStrategies 中 多 了 HiveTableScans 、DataSinks 和 Scritps 这 3 条策略。

图 1.1 Hive相关策略
4,Hive 相关的任务执行
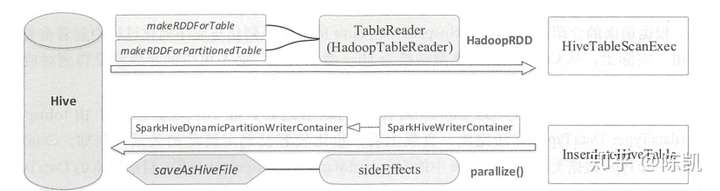
Spark SQL 连接 Hive ,最重要的就是读数据与写数据,即物理执行计划 HiveTableScanExec与 InsertlntoHiveTable
负责读数据的 HiveTableScanExec 的实现相对简单,作为叶子节点,读者很容易想到需要生成 HadoopRDD 来处理输入数据。 HiveTableScanExec 的构造参数中比较重要的是代表 Hive 数据表的 relation (类型为 MetastoreRelation )和代表 Hive Partition 相关的谓词partitionPruningPred(类型为 Seq[Expression ]) 。
因此,根据 MetastoreRelation 中是否包含数据分区,具体分为两种情况:如果 relation 中没有数据分区的定义,则直接调用makeRDDForTable 方法;如果relation 中定义了数据分区,则调用 makeRDDForPartitionedTable 方法。 这两个方法的具体实现由 HadoopTableReader 完成。 在 HadoopTableReader 的实现中,根据 relation 所在的 HDFS 路径创建 HadoopRDD 后,还需要支持将 Hive 数据表中的 Writable 数据行转换为常规的 Row 类型。