concat_ws: 用指定的字符连接字符串
例如:
连接字符串:
concat_ws("_", field1, field2),输出结果将会是:“field1_field2”。
数组元素连接:
concat_ws("_", [a,b,c]),输出结果将会是:"a_b_c"。
collect_set: 把聚合的数据组合成一个数组,一般搭配group by 使用。
例如有下表T_course;
| id | name | course |
| 1 | zhang san | Chinese |
| 2 | zhang san | Math |
| 3 | zhang san | English |
spark.sql("select name, collect_set(course) as course_set from T_course group by name");
结果是:
| name | course_set |
| zhang san | [Chinese,Math,English] |
贴上套牌车项目代码:
public class TpcCompute2 {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().enableHiveSupport().appName("TpcCompute2").master("local").getOrCreate();
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext());
sc.setLogLevel("ERROR");
//hphm,id,tgsj,lonlat&
spark.udf().register("getTpc", new ComputeUDF(), DataTypes.StringType);
spark.sql("use traffic");
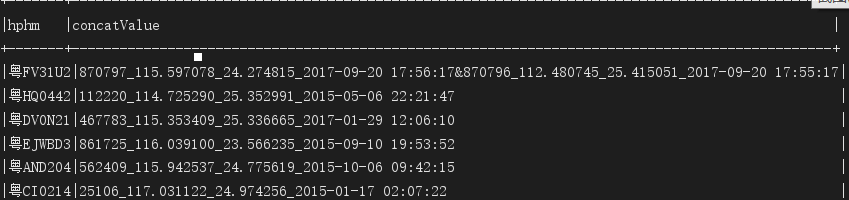
spark.sql("select hphm,concat_ws('&',collect_set(concat_ws('_',id,kk_lon_lat,tgsj))) as concatValue from t_cltgxx t where t.tgsj>'2015-01-01 00:00:00' group by hphm").show(false);
Dataset<Row> cltgxxDF =
spark.sql("select hphm,concatValue from (select hphm,getTpc(concat_ws('&',collect_set(concat_ws('_',id,kk_lon_lat,tgsj)))) as concatValue from t_cltgxx t where t.tgsj>'2015-01-01 00:00:00' group by hphm) where concatValue is not null");
cltgxxDF.show();
//创建集合累加器
CollectionAccumulator<String> acc = sc.sc().collectionAccumulator();
cltgxxDF.foreach(new ForeachFunction<Row>() {
@Override
public void call(Row row) throws Exception {
acc.add(row.getAs("concatValue"));
}
});
List<String> values = acc.value();
for (String id : accValues) {
System.out.println("accValues: " + id);
Dataset<Row> resultDF = spark.sql("select hphm,clpp,clys,tgsj,kkbh from t_cltgxx where id in (" + id.split("_")[0] + "," + id.split("_")[1] + ")");
resultDF.show();
Dataset<Row> resultDF2 = resultDF.withColumn("jsbh", functions.lit(new Date().getTime()))
.withColumn("create_time", functions.lit(new Timestamp(new Date().getTime())));
resultDF2.show();
resultDF2.write()
.format("jdbc")
.option("url","jdbc:mysql://lin01.cniao5.com:3306/traffic?characterEncoding=UTF-8")
.option("dbtable","t_tpc_result")
.option("user","root")
.option("password","123456")
.mode(SaveMode.Append)
.save();
}
}
spark.sql语句输出样式: