随着公司平台用户数量与表数量的不断增多,各种表之间的数据流向也变得更加复杂,特别是某个任务中会对源表读取并进行一系列复杂的变换后又生成新的数据表,因此需要一套表血缘关系解析机制能清晰地解析出每个任务所形成的表血缘关系链。
实现思路:
spark对sql的操作会形成一个dataframe,dataframe中的logicplan包含了sql的语法树,通过对logicplan的语法树解析可以获取当前stage所操作的输入表和输出表,将整套表关系链连接起来,再去除中间表即可获取当前作业的输入表和输出表信息。
核心代码:
def resolveLogicPlan(plan: LogicalPlan, currentDB:String): (util.Set[DcTable], util.Set[DcTable]) ={
val inputTables = new util.HashSet[DcTable]()
val outputTables = new util.HashSet[DcTable]()
resolveLogic(plan, currentDB, inputTables, outputTables)
Tuple2(inputTables, outputTables)
}
def resolveLogic(plan: LogicalPlan, currentDB:String, inputTables:util.Set[DcTable], outputTables:util.Set[DcTable]): Unit ={
plan match {
case plan: Project =>
val project = plan.asInstanceOf[Project]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Union =>
val project = plan.asInstanceOf[Union]
for(child <- project.children){
resolveLogic(child, currentDB, inputTables, outputTables)
}
case plan: Join =>
val project = plan.asInstanceOf[Join]
resolveLogic(project.left, currentDB, inputTables, outputTables)
resolveLogic(project.right, currentDB, inputTables, outputTables)
case plan: Aggregate =>
val project = plan.asInstanceOf[Aggregate]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Filter =>
val project = plan.asInstanceOf[Filter]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Generate =>
val project = plan.asInstanceOf[Generate]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: RepartitionByExpression =>
val project = plan.asInstanceOf[RepartitionByExpression]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: SerializeFromObject =>
val project = plan.asInstanceOf[SerializeFromObject]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: MapPartitions =>
val project = plan.asInstanceOf[MapPartitions]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: DeserializeToObject =>
val project = plan.asInstanceOf[DeserializeToObject]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Repartition =>
val project = plan.asInstanceOf[Repartition]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Deduplicate =>
val project = plan.asInstanceOf[Deduplicate]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Window =>
val project = plan.asInstanceOf[Window]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: MapElements =>
val project = plan.asInstanceOf[MapElements]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: TypedFilter =>
val project = plan.asInstanceOf[TypedFilter]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: Distinct =>
val project = plan.asInstanceOf[Distinct]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: SubqueryAlias =>
val project = plan.asInstanceOf[SubqueryAlias]
val childInputTables = new util.HashSet[DcTable]()
val childOutputTables = new util.HashSet[DcTable]()
resolveLogic(project.child, currentDB, childInputTables, childOutputTables)
if(childInputTables.size()>0){
for(table <- childInputTables) inputTables.add(table)
}else{
inputTables.add(DcTable(currentDB, project.alias))
}
case plan: CatalogRelation =>
val project = plan.asInstanceOf[CatalogRelation]
val identifier = project.tableMeta.identifier
val dcTable = DcTable(identifier.database.getOrElse(currentDB), identifier.table)
inputTables.add(dcTable)
case plan: UnresolvedRelation =>
val project = plan.asInstanceOf[UnresolvedRelation]
val dcTable = DcTable(project.tableIdentifier.database.getOrElse(currentDB), project.tableIdentifier.table)
inputTables.add(dcTable)
case plan: InsertIntoTable =>
val project = plan.asInstanceOf[InsertIntoTable]
resolveLogic(project.table, currentDB, outputTables, inputTables)
resolveLogic(project.query, currentDB, inputTables, outputTables)
case plan: CreateTable =>
val project = plan.asInstanceOf[CreateTable]
if(project.query.isDefined){
resolveLogic(project.query.get, currentDB, inputTables, outputTables)
}
val tableIdentifier = project.tableDesc.identifier
val dcTable = DcTable(tableIdentifier.database.getOrElse(currentDB), tableIdentifier.table)
outputTables.add(dcTable)
case plan: GlobalLimit =>
val project = plan.asInstanceOf[GlobalLimit]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case plan: LocalLimit =>
val project = plan.asInstanceOf[LocalLimit]
resolveLogic(project.child, currentDB, inputTables, outputTables)
case `plan` => logger.info("******child plan******:
"+plan)
}
}
上述代码是对logicplan做递归解析的,当logicplan为LocalLimit、GlobalLimit、Window等类型时,继续解析其子类型;当logicplan为CataLogRelation、UnresolvedRelation时,解析出的表名作为输入表;当logicplan为CreateTable、InsertIntoTable时,解析出的表名为输出表。
这里需要考虑一种特殊情况,某些源表是通过spark.read加载得到的,这样logicplan解析出来的类型为LogicRDD,不能直接获取到表名,以下面的python代码为例:
schema = StructType([StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True)])
rdd = sparkSession.sparkContext.textFile('/user/hive/warehouse/bigdata.db/tdl_spark_test/testdata.txt').map(lambda r:r.split(',')).map(lambda p: Row(int(p[0]), p[1], int(p[2])))
df = sparkSession.createDataFrame(rdd, schema)
df.createOrReplaceTempView('tdl_spark_test')
sparkSession.sql('create table tdl_file_test as select * from tdl_spark_test')
上述代码首先通过textFile读取文件得到rdd,再对rdd进行变换,最后将rdd注册成dataframe,这里对df的logicplan进行解析会得到LogicRDD,对于这种情况的解决思路是在调用textFile时记录产生的rdd,解析df的logicplan时获取其rdd,判断之前产生的rdd是否为当前rdd的祖先,如果是,则将之前rdd对应的表名计入。
判断rdd依赖关系的逻辑为:
def checkRddRelationShip(rdd1:RDD[_], rdd2:RDD[_]): Boolean ={
if (rdd1.id == rdd2.id) return true
dfsSearch(rdd1, rdd2.dependencies)
}
def dfsSearch(rdd1:RDD[_], dependencies:Seq[Dependency[_]]): Boolean ={
for(dependency <- dependencies){
if(dependency.rdd.id==rdd1.id) return true
if(dfsSearch(rdd1, dependency.rdd.dependencies)) return true
}
false
}
对LogicRDD的解析为:
case plan: LogicalRDD =>
val project = plan.asInstanceOf[LogicalRDD]
try{
for(rdd <- rddTableMap.keySet()){
if(checkRddRelationShip(rdd, project.rdd)){
val tableName = rddTableMap.get(rdd)
val db = StringUtils.substringBefore(tableName, ".")
val table = StringUtils.substringAfter(tableName, ".")
inputTables.add(DcTable(db, table))
}
}
}catch {
case e:Throwable => logger.error("resolve LogicalRDD error:", e)
}
在spark中会生成dataframe的代码段中通过aspect进行拦截,并且解析dataframe得到表的关系链,此时的关系链是一张有向无环图,图中可能包含中间表,去除掉中间表节点,则得到最终的数据流向图。
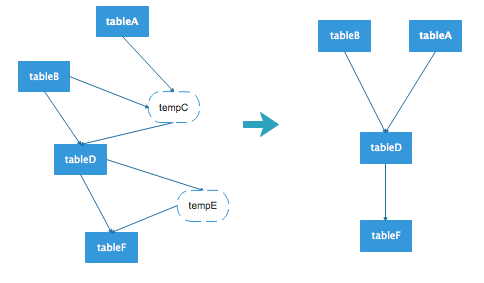
例如上图的左边是一张原始的表数据流向,其中tempC和tempE为临时表,去除这个图中的临时表节点,得到右图的数据流向图。对于前面给出的python代码,执行过后获取的数据流向为:
[bigdata.tdl_spark_test]--->bigdata.tdl_file_test
当然这种解析方式也存在一些缺点,比如首先通过spark.read读取数据注册一张临时表,再将临时表中的某些字段值拉到本地缓存,然后创建一个空的datadrame,将缓存的字段值直接插入到该df中,由于当前创建的df与之前创建的df已经没有依赖关系,因此这种情况将无法解析出准确的数据流向。