简介
Z-Score标准化是数据处理的一种常用方法。通过它能够将不同量级的数据转化为统一量度的Z-Score分值进行比较。
一句话解释版本:
Z-Score通过(x-μ)/σ将两组或多组数据转化为无单位的Z-Score分值,使得数据标准统一化,提高了数据可比性,削弱了数据解释性。
数据分析与挖掘体系位置
Z-Score标准化是数据处理的方法之一。在数据标准化中,常见的方法有如下三种:
Z-Score 标准化
最大最小标准化
小数定标法
本篇主要介绍第一种数据标准化的方法,Z-Score标准化。
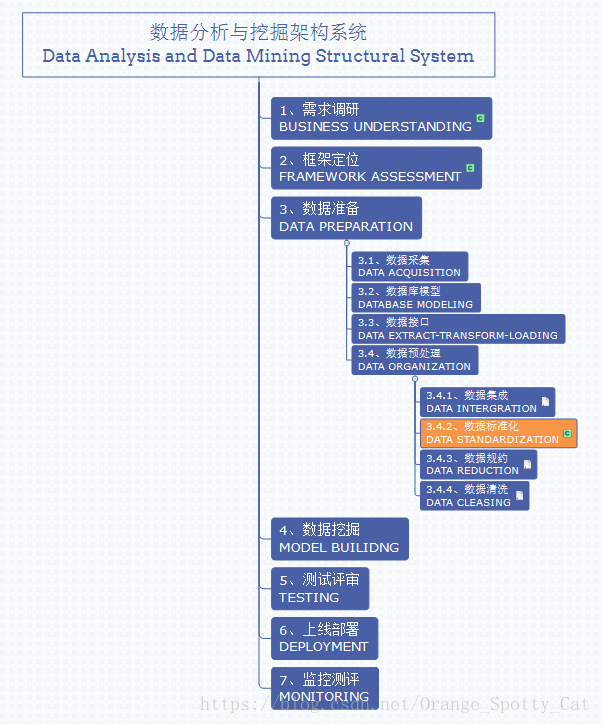
此方法在整个数据分析与挖掘体系中的位置如下图所示。
Z-Score的定义
Z-Score处理方法处于整个框架中的数据准备阶段。也就是说,在源数据通过网络爬虫、接口或其他方式进入数据库中后,下一步就要进行的数据预处理阶段中的重要步骤。
数据分析与挖掘中,很多方法需要样本符合一定的标准,如果需要分析的诸多自变量不是同一个量级,就会给分析工作造成困难,甚至影响后期建模的精准度。
举例来说,假设我们要比较A与B的考试成绩,A的考卷满分是100分(及格60分),B的考卷满分是700分(及格420分)。很显然,A考出的70分与B考出的70分代表着完全不同的意义。但是从数值来讲,A与B在数据表中都是用数字70代表各自的成绩。
那么如何能够用一个同等的标准来比较A与B的成绩呢?Z-Score就可以解决这一问题。
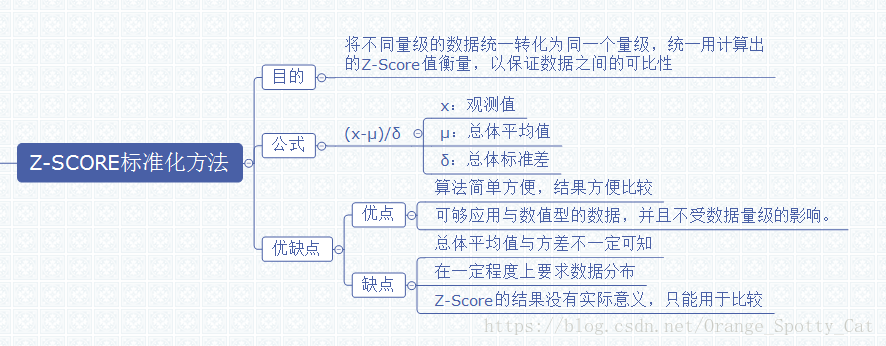
下图描述了Z-Score的定义以及各种特征。
Z-Score的目的
如上图所示,Z-Score的主要目的就是将不同量级的数据统一转化为同一个量级,统一用计算出的Z-Score值衡量,以保证数据之间的可比性。
Z-Score的理解与计算
在对数据进行Z-Score标准化之前,我们需要得到如下信息:
1)总体数据的均值(μ)
在上面的例子中,总体可以是整个班级的平均分,也可以是全市、全国的平均分。
2)总体数据的标准差(σ)
这个总体要与1)中的总体在同一个量级。
3)个体的观测值(x)
在上面的例子中,即A与B各自的成绩。
通过将以上三个值代入Z-Score的公式,即:
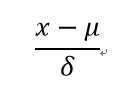
我们就能够将不同的数据转换到相同的量级上,实现标准化。
重新回到前面的例子,假设:A班级的平均分是80,标准差是10,A考了90分;B班的平均分是400,标准差是100,B考了600分。
通过上面的公式,我们可以计算得出,A的Z-Score是1((90-80)/10),B的Z-Socre是2((600-400)/100)。因此B的成绩更为优异。
反之,若A考了60分,B考了300分,A的Z-Score是-2,B的Z-Score是-1。因此A的成绩更差。
因此,可以看出来,通过Z-Score可以有效的把数据转换为统一的标准,但是需要注意,并进行比较。Z-Score本身没有实际意义,它的现实意义需要在比较中得以实现,这也是Z-Score的缺点之一。
Z-Score的优缺点
Z-Score最大的优点就是简单,容易计算,在R中,不需要加载包,仅仅凭借最简单的数学公式就能够计算出Z-Score并进行比较。此外,Z-Score能够应用于数值型的数据,并且不受数据量级的影响,因为它本身的作用就是消除量级给分析带来的不便。
但是Z-Score应用也有风险。首先,估算Z-Score需要总体的平均值与方差,但是这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代。其次,Z-Score对于数据的分布有一定的要求,正态分布是最有利于Z-Score计算的。最后,Z-Score消除了数据具有的实际意义,A的Z-Score与B的Z-Score与他们各自的分数不再有关系,因此Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值。
Z-Score在R中的实现
如下例子是我用R软件写出的Z-Score计算方法。
# define dataset
data_A <- rnorm(100, 80, 10) # randomly create population dataset
data_B <- rnorm(100, 400, 100) # randomly create population dataset
hist(data_A) #histogram
hist(data_B) #histogram
#Calculate population mean and standard deviation
A_data_std <- sd(data_A)*sqrt((length(data_A)-1)/(length(data_A)))
A_data_mean <- mean(data_A)
B_data_std <- sd(data_B)*sqrt((length(data_B)-1)/(length(data_B)))
B_data_mean <- mean(data_B)
# Provided that A got 92 and B got 610
A_obs <- 92
B_obs <- 610
A_Z_score <- (A_obs - A_data_mean) / A_data_std
B_Z_score <- (B_obs - B_data_mean) / B_data_std
原文:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80312154