转载自:https://blog.csdn.net/sunbow0/article/details/50848719
1、基于Spark自动扩展scikit-learn(spark-sklearn)
1.1 导论
Spark MLlib 将传统的单机机器学习算法改造成分布式机器学习算法,比如在梯度下降算法中,单机做法是计算所有样本的梯度值,单机算法是以全体样本为计算单位;而分布式算法的逻辑是以每个样本为单位,在集群上分布式的计算每个样本的梯度值,然后再对每个样本的梯度进行聚合操作等。在Spark Mllib中分布式的计算单位可以是:一个样本数据、一个分区的样本数据,一个矩阵等等,分布式的计算单位根据算法的需求而不同,前提条件是每个单位的计算应该是可独立,不依赖于其它单位的计算结果,所以一般在分布式算法设计时,需要把每个单位计算时所需要的数据放在一个单位里,例如在ALS的分布式设计中,将U和V的数据进行重新分区,并建立新的数据集。
Spark Mllib实现了在大数据训练样本下的分布式计算,适应于工程化的实践项目中,如果当计算模型中需要涉及到各种模型参数的调优时,Spark Mllib就会显得有些不足,那我们能否设想下:在小样本训练集下,我在Spark上随机生成1千万个计算模型,把这1千万个计算模型分布式的运行在Spark集群上对训练集进行模型测试计算,是不是可以得到一个结果最优的模型,该模型对应的参数就是最优参数,然后我们根据最优化参数应用在工程化的实践中。
我们可以对Spark Mllib 进行扩展,把我们的带有参数的机器学习模型当作分布的计算单位,每个单位的元素包括:(带参数的模型,训练样本,测试样本),每个单位的计算过程就是将对训练样本训练带参数的模型,得到模型,然后计算测试样本的精度,在集群中对各个单位进行分布式的计算,最终取得最优结果的那个模型。
这就是我下面要介绍的:Auto-scaling scikit-learn with Spark。
1.2 spark-sklearn背景
数据科学家经常花几个小时或几天来调优模型使得计算的精度最高。这种调优通常是在Python或R中运行大量的单机机器学习(ML)任务。
目前Spark集成了Scikit-learn包,这样可以极大的简化了Python数据科学家们的工作,这个包可以在Spark集群上自动分配模型参数优化计算任务,而且不影响现有的工作流程:
如果在单个机器上使用时, Spark可以使用scikit-learn(Joblib)替代默认的多线程框架。
如果需要工作在多台机器上,也不需要修改代码,可以在单机和集群中运行。
1.3 轻松应对大规模模型计算
对于数据分析处理,Python是一种最流行的编程语言,这在很大程度上是由于高质量的计算库,比如数据分析的Pandas 和机器学习orscikit-learn等。Scikit-learn提供快速、健壮的标准ML算法如集群、分类和回归等。
Scikit-learn的优势通常是在单个节点上进行机器学习的计算,。对于一些常见的场景,如参数调优,大量小任务可以并行地运行。这些场景可以完美使用Spark来解决。
1.4 随机森林的分布优化
采用图像识别数字的一个经典例子。数据包括:数字图像的数据集与对应的标签:

我们通过训练随机森林分类器来识别数字。这个分类器有许多参数需要调整,但是没有简单的方法来知道哪个参数效果的好与坏,除了尝试大量的不同组合。Scikit-learn提供了GridSearchCV接口,一个搜索算法,自动搜索最优参数设置。如下图示例,GridSearchCV采用交叉验证的方式进行参数选择,每个参数设置产生一个模型,最终选择表现最好的模型。
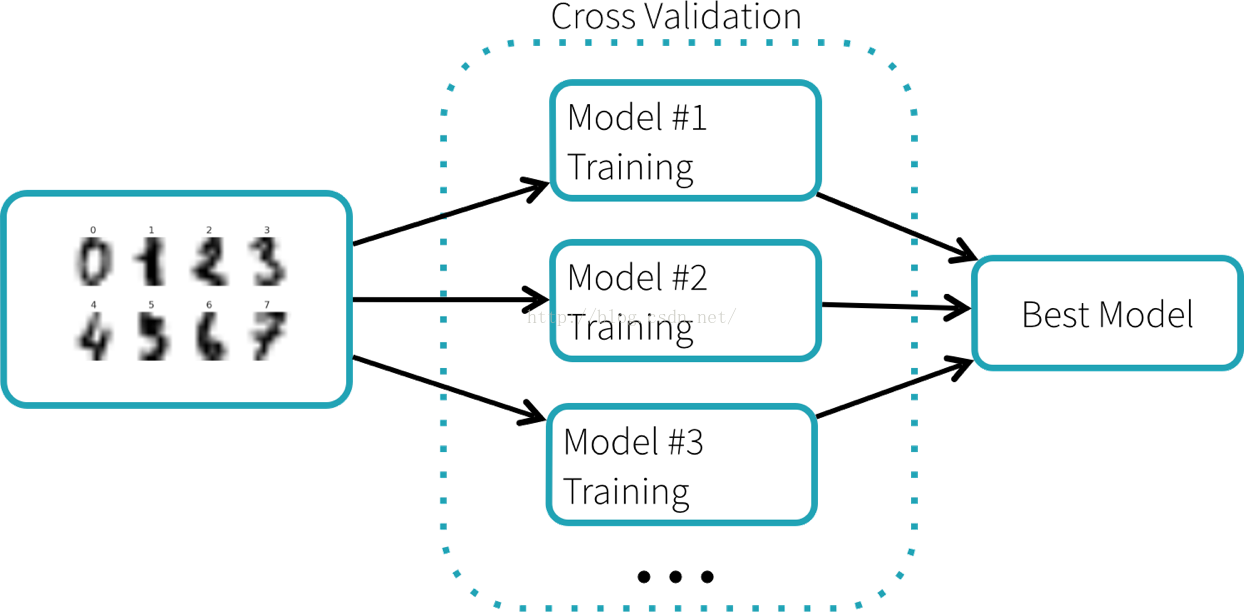
使用scikit-learn的原代码如下:
from sklearn import grid_search, datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
digits = datasets.load_digits()
X, y = digits.data, digits.target
param_grid = {"max_depth": [3, None],
"max_features": [1, 3, 10],
"min_samples_split": [1, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
"n_estimators": [10, 20, 40, 80]}
gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid)
gs.fit(X, y)
训练数据集很小(数百kb),但探索所有的组合大约需要5分钟。Spark的scikit-learn包提供了一种在Spark集群上进行分布式的交叉验证算法计算工作。每个节点运行训练算法使用的本地的scikit-learn库,并且向集群的master报告最佳模型:
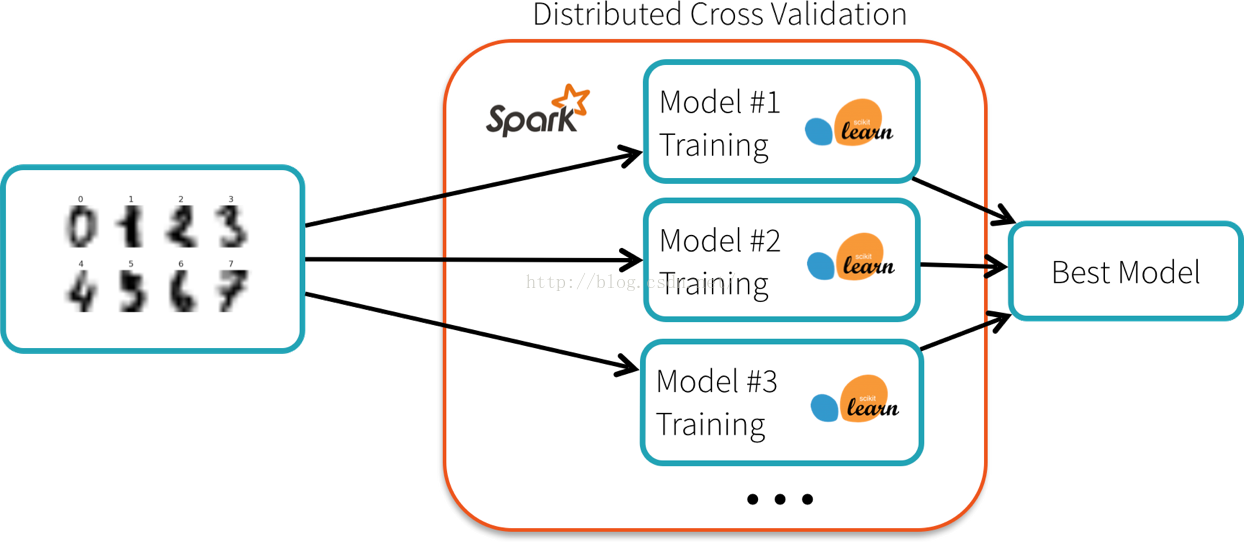
他之前的代码是一样的,除了一行变化:
from sklearn import grid_search, datasets from sklearn.ensemble import RandomForestClassifier # Use spark_sklearn’s grid search instead: from spark_sklearn import GridSearchCV digits = datasets.load_digits() X, y = digits.data, digits.target param_grid = {"max_depth": [3, None], "max_features": [1, 3, 10], "min_samples_split": [1, 3, 10], "min_samples_leaf": [1, 3, 10], "bootstrap": [True, False], "criterion": ["gini", "entropy"], "n_estimators": [10, 20, 40, 80]} gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid)
gs.fit(X, y)
这个例子在4个节点(16 cpu)的集群上运行时间小于30秒。对于大数据集和更多的参数设置,效率的提升则更大。
如果你想试试这个包,需要:
https://pypi.python.org/pypi/spark-sklearn
http://spark-packages.org/package/databricks/spark-sklearn
实例地址:http://go.databricks.com/hubfs/notebooks/Samples/Miscellaneous/blog_post_cv.html
详细见API:
http://pythonhosted.org/spark-sklearn/