“高性能架构模式”
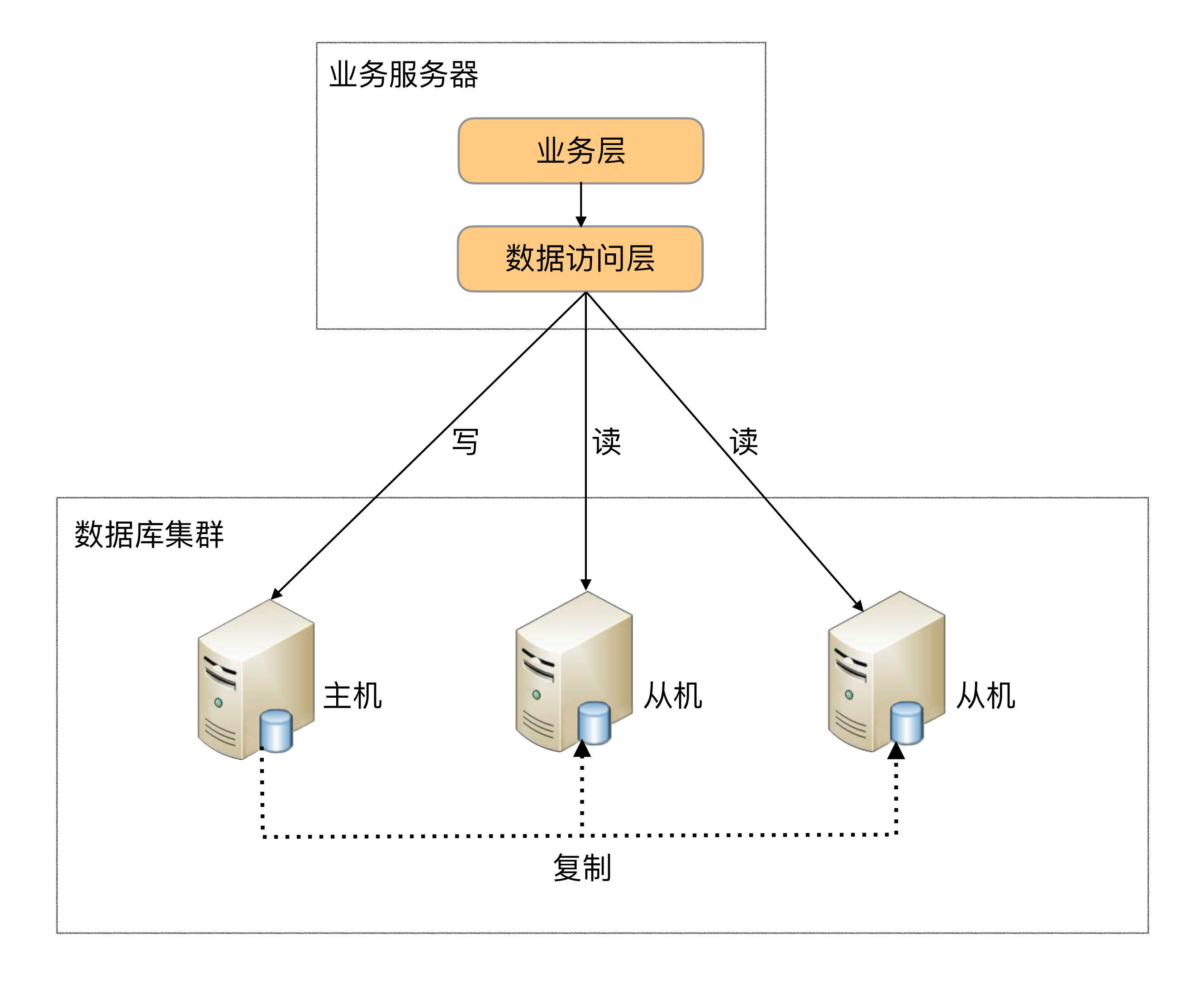
- “读写分离”,其本质是将访问压力分散到集群中的多个节点,但是没有分散存储压力
- 主从结构,主读写,从读,主从通过复制同步;
- 主从复制不一致问题解决:写操作后的读操作指定发给数据库主服务器/读从机失败后再读一次主机/关键业务读写操作全部指向主机,非关键业务采用读写分离
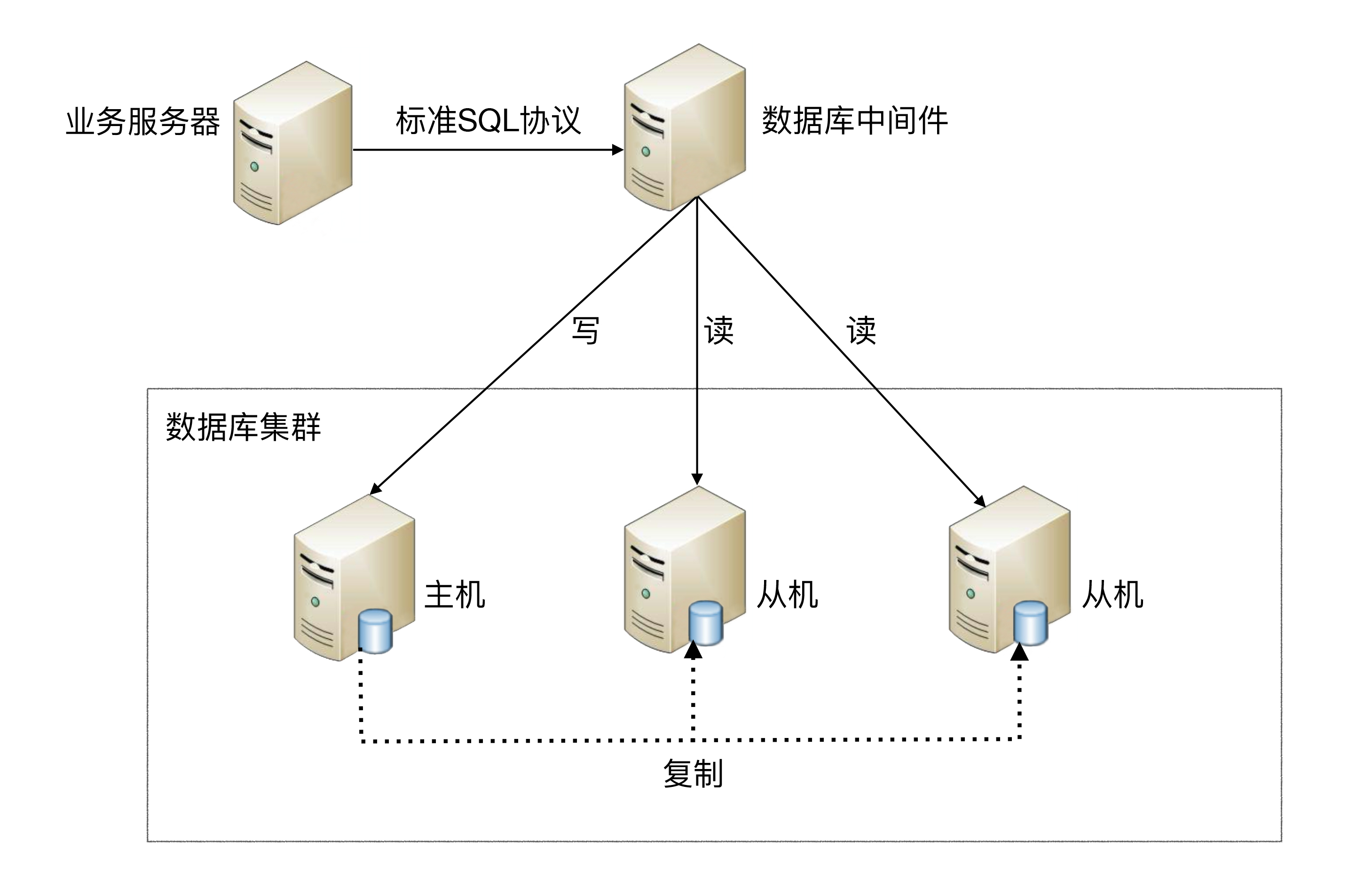
- 分配机制:代码封装/中间件封装/
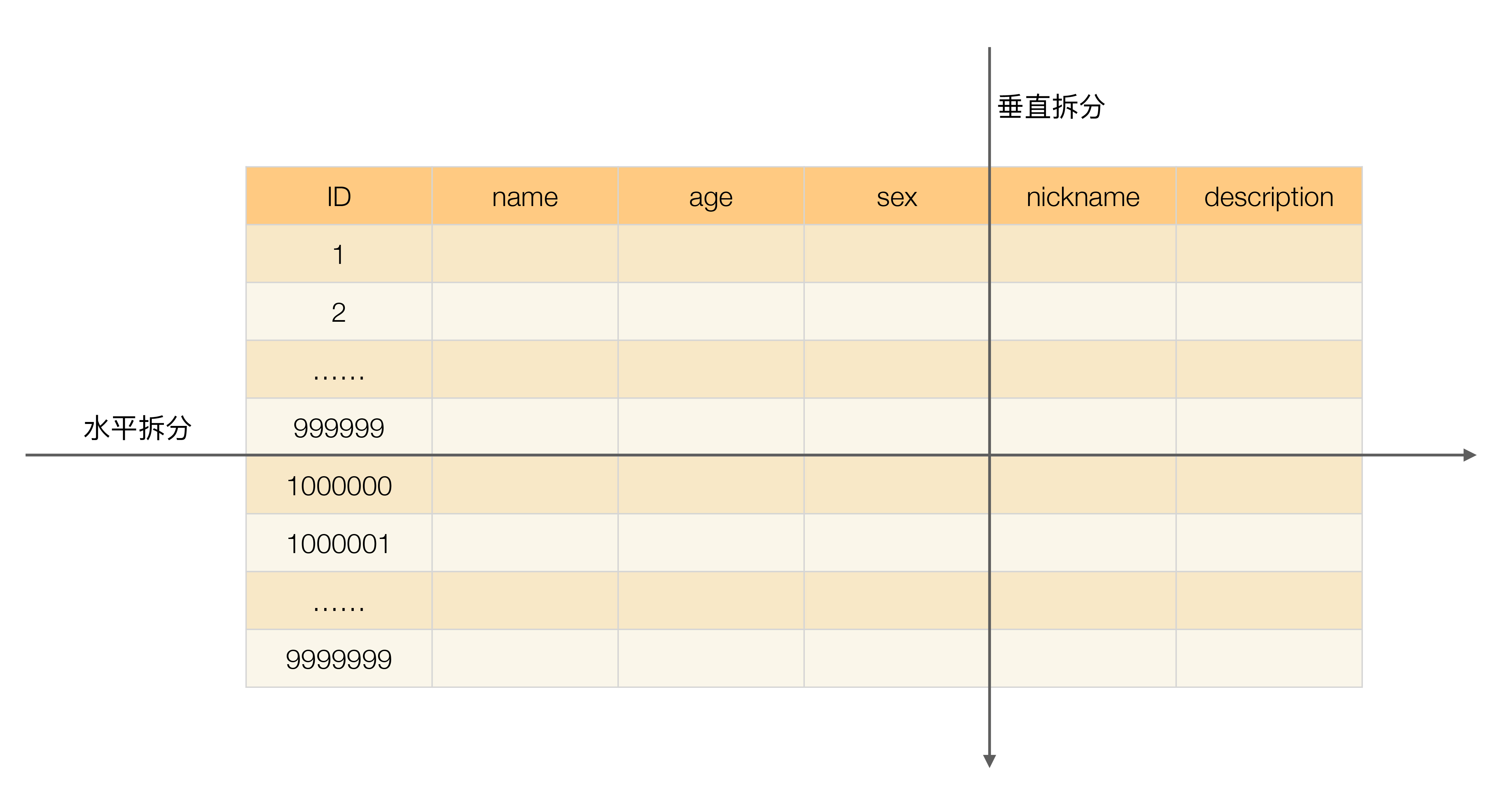
- “分库分表”,既可以分散访问压力,又可以分散存储压力

- Nosql:
- K-V 存储:解决关系数据库无法存储数据结构的问题,以 Redis 为代表((string、hash、list、set、sorted set、bitmap 和 hyperloglog))。
- 文档数据库:解决关系数据库强 schema 约束的问题,以 MongoDB 为代表(json富文本,适合存储列不固定,比如商品属性等,弱化事务json等)。
- 列式数据库:解决关系数据库大数据场景下的 I/O 问题,以 HBase 为代表(列式存储,适合数据分析写入后按列统计类,较高压缩比,较少的io)。
- 全文搜索引擎:解决关系数据库的全文搜索性能问题,以 Elasticsearch 为代表(倒排索引,单词->文档)。
- 缓存:
- 复杂计算数据/读多写少 -> 将可能重复使用的数据放到内存中,一次生成、多次使用,避免每次使用都去访问存储系统
- 缓存穿透 -> 缓存中没有数据,业务系统需要再次去存储系统查询数据,如果数据库中也没有,防止恶意攻击,可以缓存空结果;如果有但计算消耗大,比如电商分页,则尽量将请求限制在更早的时候或者定时异步更新缓存;还可以利用布隆过滤器过滤
- 缓存雪崩 -> 指当缓存失效(过期)后引起系统性能急剧下降的情况,解决缓存高可用/采用分布式锁/后台异步更新缓存/缓存超时加任意时间/缓存预热
- 缓存热点 -> 解决方案就是复制多份缓存副本,将请求分散到多个缓存服务器上,减轻缓存热点导致的单台缓存服务器压力
- 缓存击穿(热点失效) -> 热点数据突然查询不到,导致所有的请求直接访问数据库,解决:过期时间足够长/分布式锁
- 单服务器高性能:
- PPC - Process Per Connection,其含义是指每次有新的连接就新建一个进程去专门处理这个连接的请求
- prefork - 提前创建进程(pre-fork)。系统在启动的时候就预先创建好进程,然后才开始接受用户的请求,当有新的连接进来的时候,就可以省去 fork 进程的操作,让用户访问更快、体验更好,prefork 模式和 PPC 一样,还是存在父子进程通信复杂、支持的并发连接数量有限的问题,因此目前实际应用也不多
- TPC - Thread Per Connection 的缩写,其含义是指每次有新的连接就新建一个线程去专门处理这个连接的请求
- prethread 模式会预先创建线程,然后才开始接受用户的请求,当有新的连接进来的时候,就可以省去创建线程的操作,让用户感觉更快、体验更好
- 优化?资源浪费问题解决,资源复用,即不再单独为每个连接创建进程,而是创建一个进程池,将连接分配给进程,一个进程可以处理多个连接的业务,当一个连接一个进程时,进程可以采用“read -> 业务处理 -> write”的处理流程,如果当前连接没有数据可以读,则进程就阻塞在 read 操作上。这种阻塞的方式在一个连接一个进程的场景下没有问题,但如果一个进程处理多个连接,进程阻塞在某个连接的 read 操作上,此时即使其他连接有数据可读,进程也无法处理,很显然这样是无法做到高性能的
-
- I/O 多路复用结合线程池:当多条连接共用一个阻塞对象后,进程只需要在一个阻塞对象上等待,而无须再轮询所有连接,常见的实现方式有 select、epoll、kqueue 等。当某条连接有新的数据可以处理时,操作系统会通知进程,进程从阻塞状态返回,开始进行业务处理
- 单 Reactor 单进程 / 线程:单 Reactor 单进程的是 Redis
- 单 Reactor 多线程
- 多 Reactor 多进程 / 线程;Nginx 采用的是多 Reactor 多进程,采用多 Reactor 多线程的实现有 Memcache 和 Netty
- I/O 多路复用结合线程池:当多条连接共用一个阻塞对象后,进程只需要在一个阻塞对象上等待,而无须再轮询所有连接,常见的实现方式有 select、epoll、kqueue 等。当某条连接有新的数据可以处理时,操作系统会通知进程,进程从阻塞状态返回,开始进行业务处理
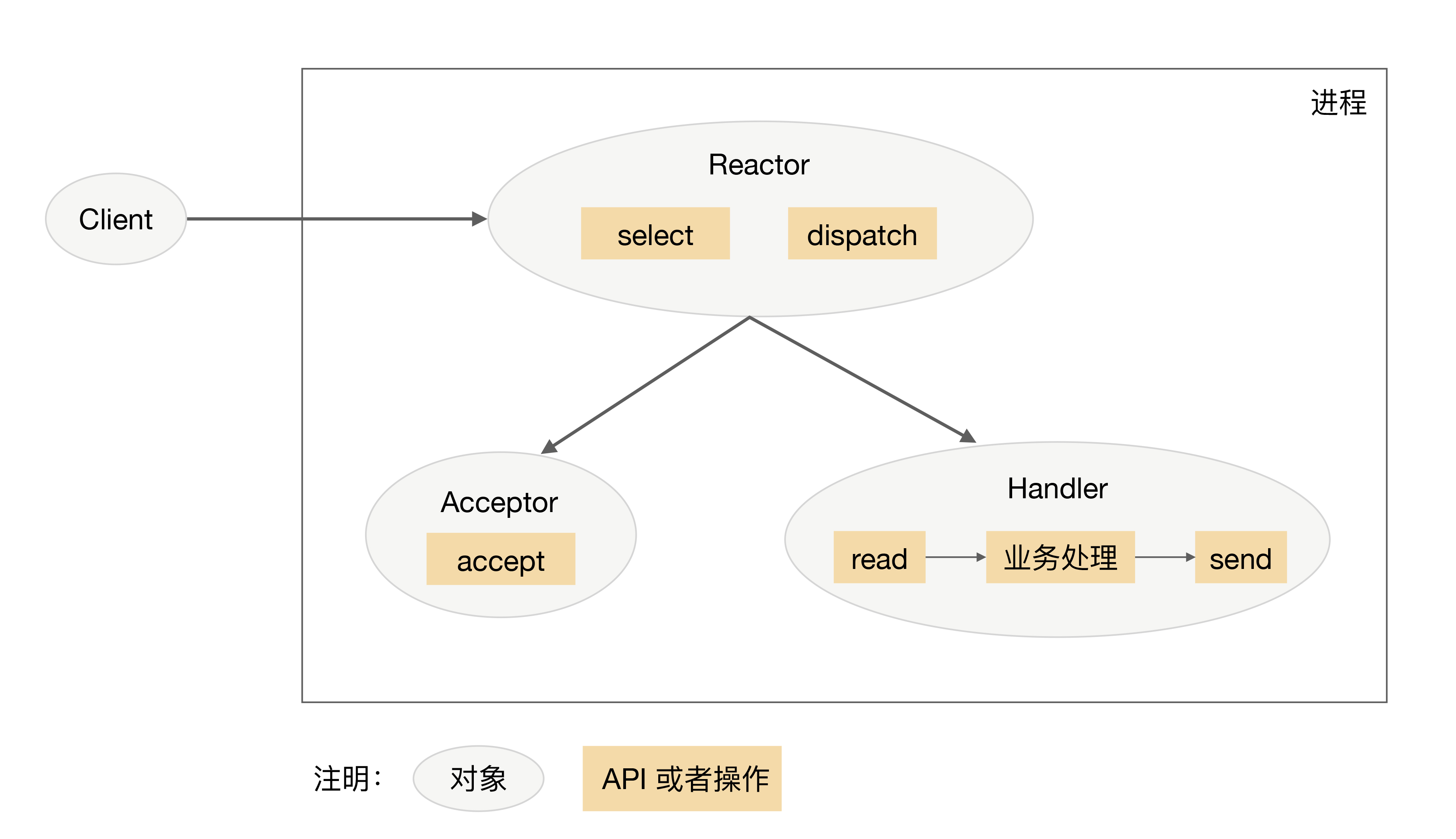
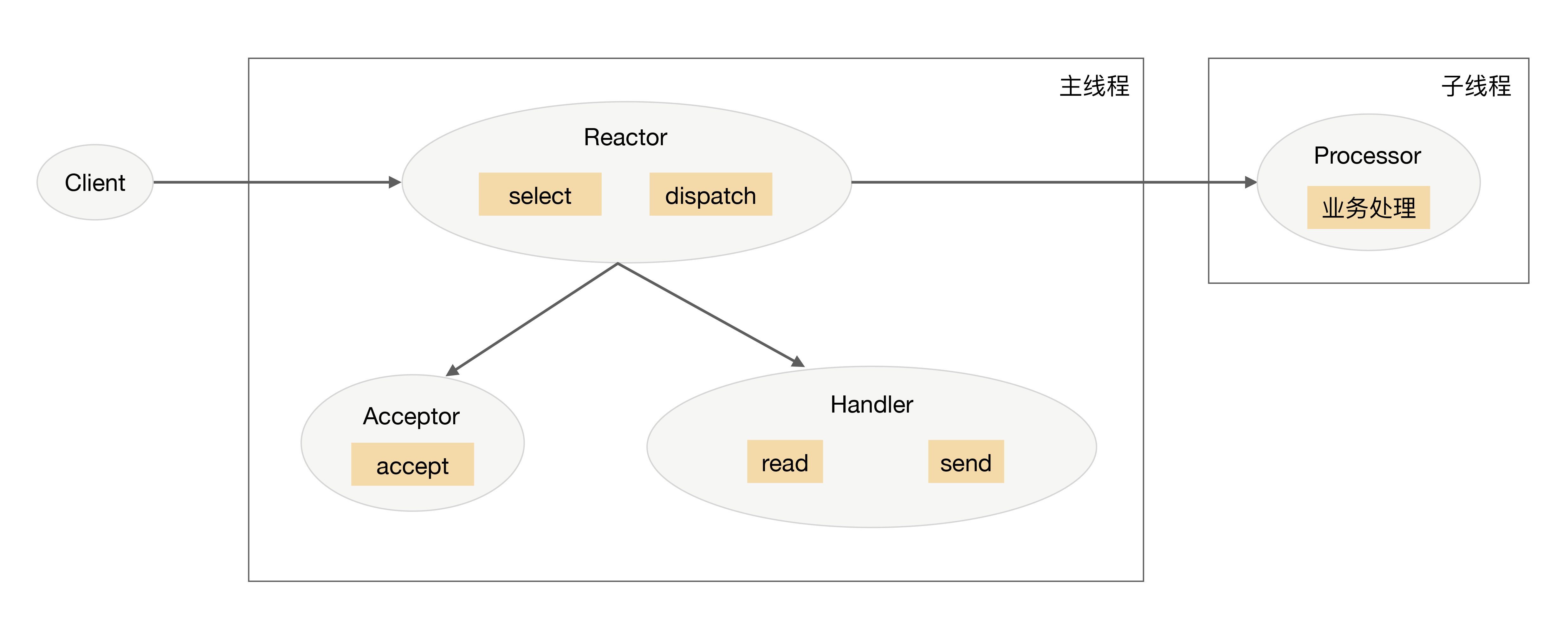
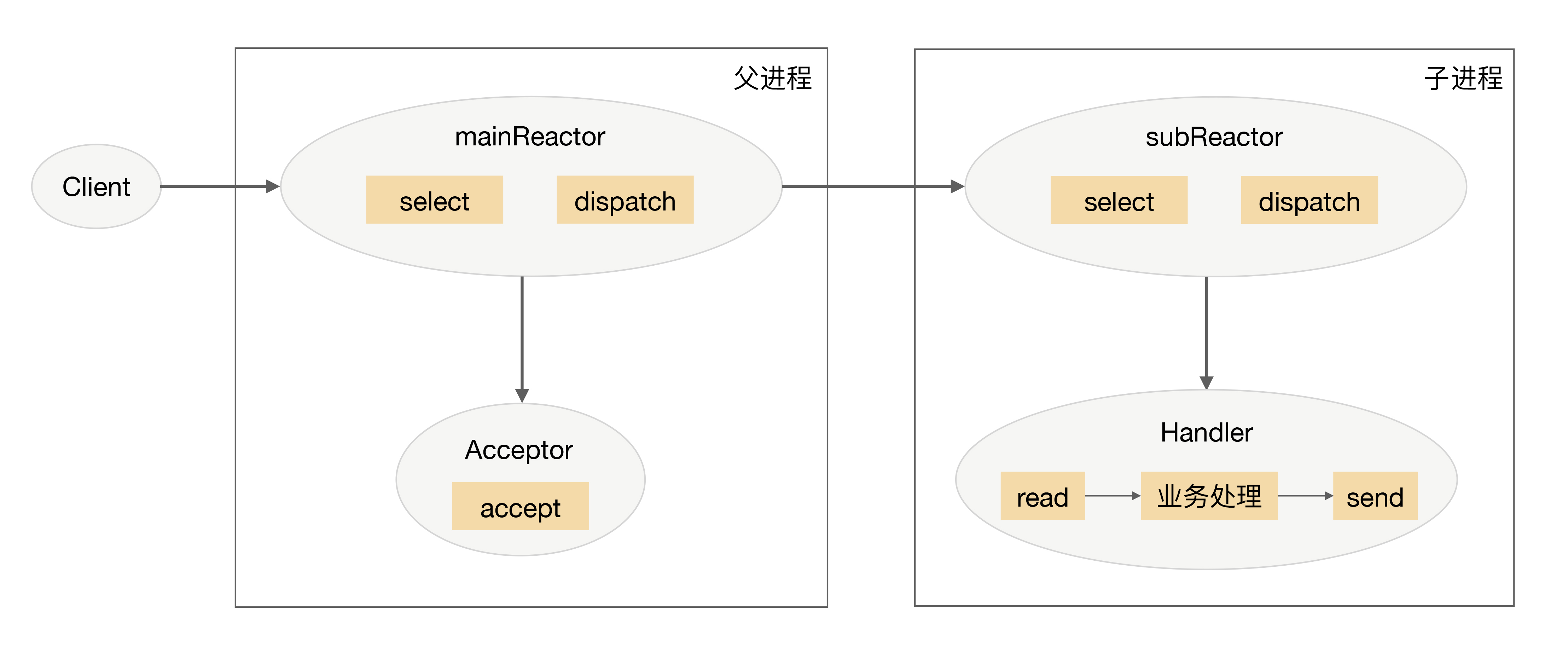
-
- Proactor 非阻塞同步网络模型;来了事件我来处理,处理完了我通知你
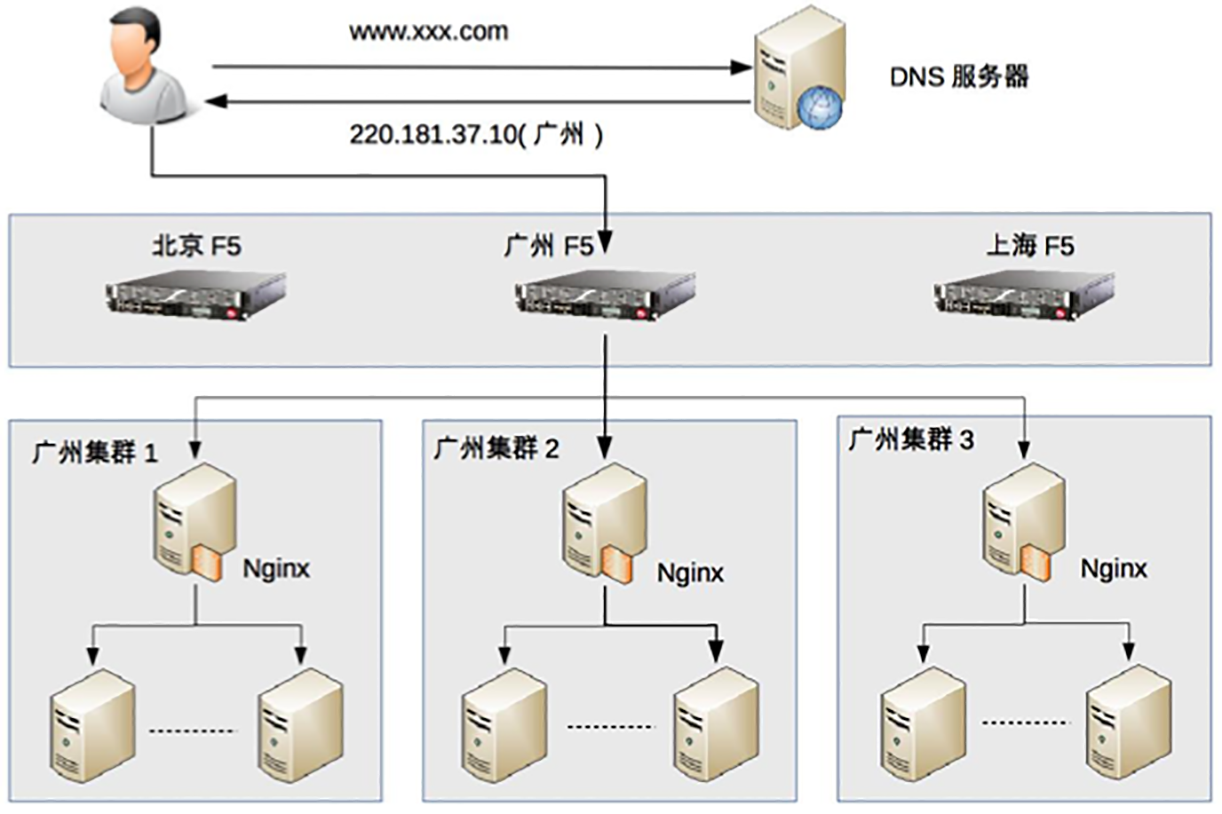
- 集群任务分配器:DNS/硬件负载均衡F5/软件负载均衡nginx.lvs,地理级别负载均衡就近DNS,集群级别负载均衡F5,机器级别负载均衡nginx